Project scenario:
l2t code needs to use theano library and GPU to accelerate calculation
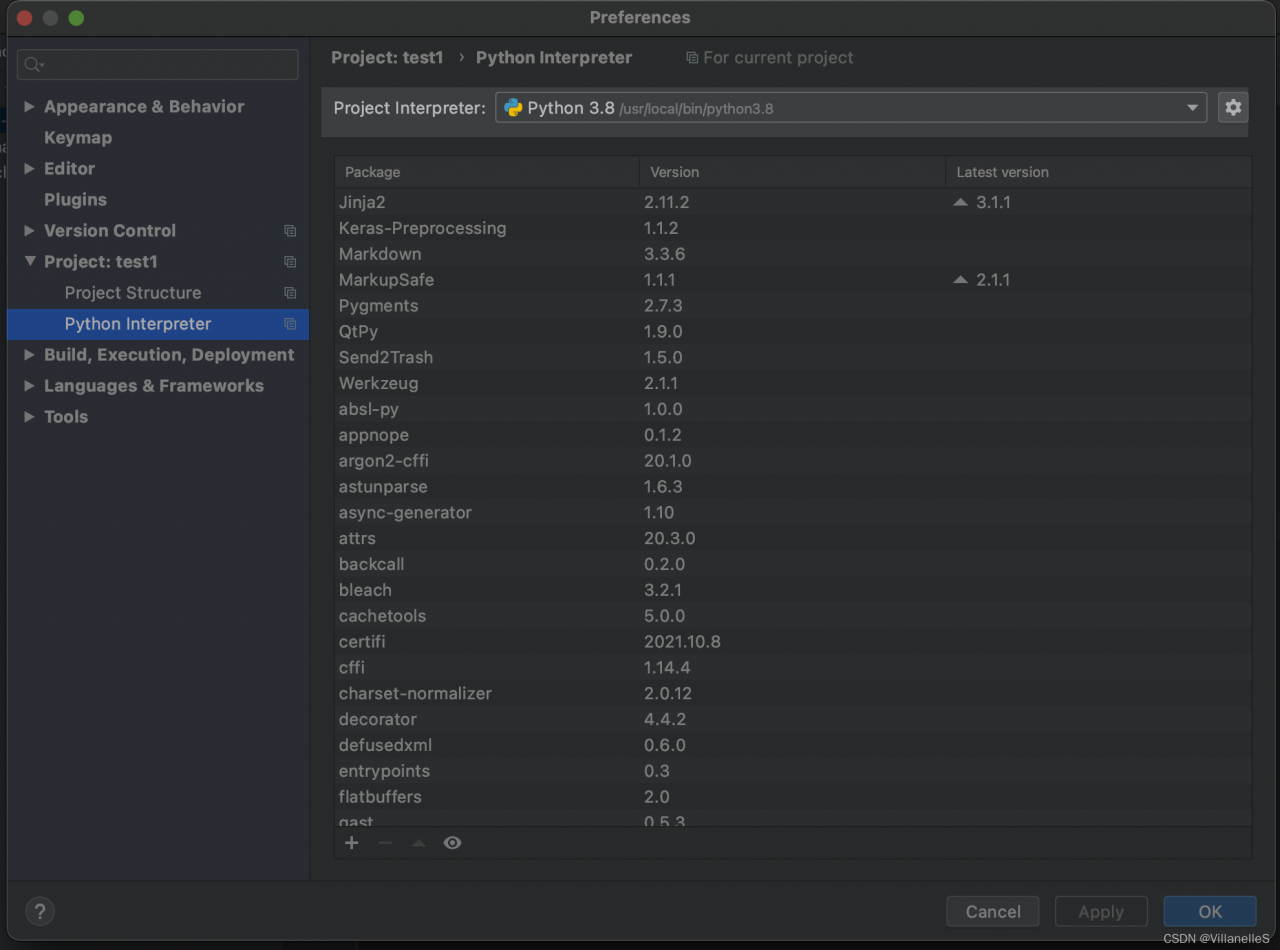
Non root user ubuntu-18.04 + cuda8 0 (you need to downgrade GCC to match, I’ll configure it as 5.3) + cudnn V5 1+theano 1.0.4+pygpu 0.7.6
Problem description
pygpu.gpuarray.GpuArrayException: b'cuMemAlloc: CUDA_ERROR_OUT_OF_MEMORY: out of memory
Training... 2448.24 sec.
Traceback (most recent call last):
File ".../python3.8/site-packages/theano/compile/function_module.py", line 903, in __call__
self.fn() if output_subset is None else\
File "pygpu/gpuarray.pyx", line 689, in pygpu.gpuarray.pygpu_zeros
File "pygpu/gpuarray.pyx", line 700, in pygpu.gpuarray.pygpu_empty
File "pygpu/gpuarray.pyx", line 301, in pygpu.gpuarray.array_empty
pygpu.gpuarray.GpuArrayException: b'cuMemAlloc: CUDA_ERROR_OUT_OF_MEMORY: out of memory'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "learn.py", line 535, in <module>
main()
File "learn.py", line 531, in main
trainer.train()
File "..l2t/lib/python3.8/site-packages/smartlearner-0.1.0-py3.8.egg/smartlearner/trainer.py", line 31, in train
File ../l2t/lib/python3.8/site-packages/smartlearner-0.1.0-py3.8.egg/smartlearner/trainer.py", line 90, in _learning
File "..l2t/lib/python3.8/site-packages/theano/compile/function_module.py", line 914, in __call__
gof.link.raise_with_op(
File "../l2t/lib/python3.8/site-packages/theano/gof/link.py", line 325, in raise_with_op
reraise(exc_type, exc_value, exc_trace)
File "../l2t/lib/python3.8/site-packages/six.py", line 718, in reraise
raise value.with_traceback(tb)
File "../l2t/lib/python3.8/site-packages/theano/compile/function_module.py", line 903, in __call__
self.fn() if output_subset is None else\
File "pygpu/gpuarray.pyx", line 689, in pygpu.gpuarray.pygpu_zeros
File "pygpu/gpuarray.pyx", line 700, in pygpu.gpuarray.pygpu_empty
File "pygpu/gpuarray.pyx", line 301, in pygpu.gpuarray.array_empty
pygpu.gpuarray.GpuArrayException: b'cuMemAlloc: CUDA_ERROR_OUT_OF_MEMORY: out of memory'
Apply node that caused the error: GpuAlloc<None>{memset_0=True}(GpuArrayConstant{[[0.]]}, Elemwise{Composite{((i0 * i1 * i2 * i3) // maximum(i3, i4))}}[(0, 0)].0, Shape_i{3}.0)
Toposort index: 98
Inputs types: [GpuArrayType<None>(float64, (True, True)), TensorType(int64, scalar), TensorType(int64, scalar)]
Inputs shapes: [(1, 1), (), ()]
Inputs strides: [(8, 8), (), ()]
Inputs values: [gpuarray.array([[0.]]), array(2383800), array(100)]
Outputs clients: [[forall_inplace,gpu,grad_of_scan_fn}(Shape_i{1}.0, InplaceGpuDimShuffle{0,2,1}.0, InplaceGpuDimShuffle{0,2,1}.0, InplaceGpuDimShuffle{0,2,1}.0, GpuAlloc<None>{memset_0=True}.0, GpuSubtensor{int64:int64:int64}.0, GpuSubtensor{int64:int64:int64}.0, GpuSubtensor{int64:int64:int64}.0, GpuSubtensor{int64:int64:int64}.0, GpuSubtensor{int64:int64:int64}.0, GpuAlloc<None>{memset_0=True}.0, GpuAlloc<None>{memset_0=True}.0, GpuAlloc<None>{memset_0=True}.0, GpuAlloc<None>{memset_0=True}.0, GpuAlloc<None>{memset_0=True}.0, Shape_i{1}.0, Shape_i{1}.0, Shape_i{1}.0, Shape_i{1}.0, Shape_i{1}.0, Shape_i{1}.0, Shape_i{1}.0, Shape_i{1}.0, Shape_i{1}.0, Shape_i{1}.0, GRU0_W, GRU0_U, GRU0_Uh, GRU1_W, GRU1_U, GRU1_Uh, InplaceGpuDimShuffle{x,0}.0, GpuFromHost<None>.0, GpuElemwise{add,no_inplace}.0, GpuElemwise{add,no_inplace}.0, GpuElemwise{Add}[(0, 1)]<gpuarray>.0, GpuReshape{2}.0, GpuFromHost<None>.0, GpuElemwise{add,no_inplace}.0, GpuElemwise{add,no_inplace}.0, GpuElemwise{Add}[(0, 1)]<gpuarray>.0, GpuReshape{2}.0, GpuFromHost<None>.0, GpuElemwise{add,no_inplace}.0, GpuElemwise{add,no_inplace}.0, GpuElemwise{Add}[(0, 1)]<gpuarray>.0, GpuReshape{2}.0, InplaceGpuDimShuffle{1,0}.0, InplaceGpuDimShuffle{1,0}.0, InplaceGpuDimShuffle{x,0}.0, InplaceGpuDimShuffle{1,0}.0, InplaceGpuDimShuffle{1,0}.0, InplaceGpuDimShuffle{1,0}.0, InplaceGpuDimShuffle{1,0}.0, GpuFromHost<None>.0, InplaceGpuDimShuffle{1,0}.0, GpuAlloc<None>{memset_0=True}.0, GpuFromHost<None>.0, GpuAlloc<None>{memset_0=True}.0, GpuFromHost<None>.0, GpuAlloc<None>{memset_0=True}.0)]]
HINT: Re-running with most Theano optimization disabled could give you a back-trace of when this node was created. This can be done with by setting the Theano flag 'optimizer=fast_compile'. If that does not work, Theano optimizations can be disabled with 'optimizer=None'.
HINT: Use the Theano flag 'exception_verbosity=high' for a debugprint and storage map footprint of this apply node.
Solution:
Reduce gpu__preallocate, I reduced it to 0.8, and optimize it with a small amount of graphs according to the hint when the error is reported

type in the codes
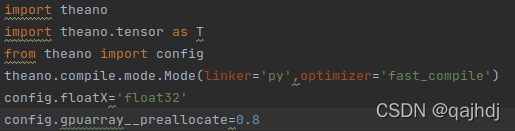
Run successfully!