My problem is with the latest version of px4v1.12.3 of pixhawk1 brush. The specific reason is unknown. The version is too high. It is OK to brush v1.11.3 stable version

My problem is with the latest version of px4v1.12.3 of pixhawk1 brush. The specific reason is unknown. The version is too high. It is OK to brush v1.11.3 stable version
wind system black window start hadoop error solution (continuously updated)
cmd command start process error cmd start prompt io error
cmd command start process error
Failed to setup local dir /tmp/hadoop-GK/nm-local-dir, which was marked as good. org.apache.hadoop.yarn.exceptions.YarnRuntimeException: Permissions incorrectly set for dir /tmp/hadoop-GK/nm-local-dir/nmPrivate, should be rwx------, actual value = rwxrwx-
Solution: Run cmd as administrator
cmd startup prompt io error
IOException: Incompatible clusterIDs in D:\hadoop\3.0.3\data\dfs\datanode: namenode clusterID = CID-45d4d17f-96fd-4644-b0ee- 7835ef5bc790; datanode clusterID = CID-01f27c2a-6229-4a10-b098-89e89d4c62e4
Solution: Delete the data directory in hadoop and restart
error code
public static void main(String[] args)throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
final LocalDateTime localDateTime = LocalDateTime.now();
final String s = objectMapper.writeValueAsString(localDateTime);
System.out.println(s);
}
Error
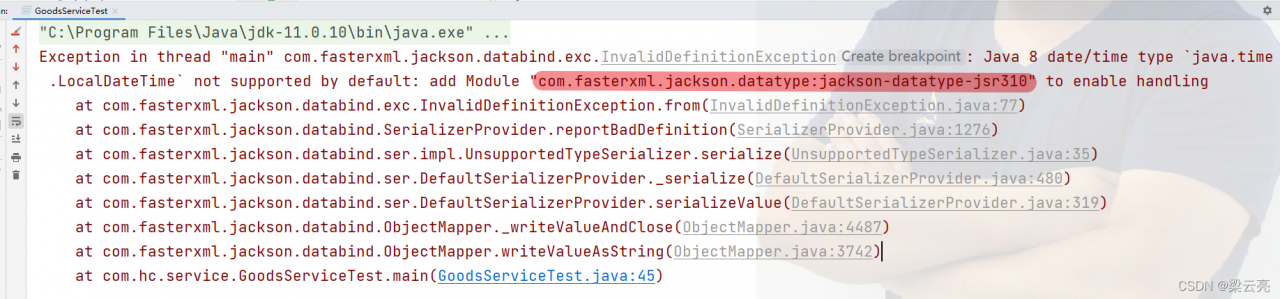
reason
The date was not formatted during conversion
Solution:
public static void main(String[] args)throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
// Date and time formatting
JavaTimeModule javaTimeModule = new JavaTimeModule();
// Set the serialization format of LocalDateTime
javaTimeModule.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
javaTimeModule.addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern("yyyy-MM-dd")));
javaTimeModule.addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern("HH:mm:ss")));
javaTimeModule.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
javaTimeModule.addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern("yyyy-MM-dd")));
javaTimeModule.addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern("HH:mm:ss")));
objectMapper.registerModule(javaTimeModule);
final LocalDateTime localDateTime = LocalDateTime.now();
final String s = objectMapper.writeValueAsString(localDateTime);
System.out.println(s);
}
Error when starting Jenkins
sudo systemctl start jenkinsError Messages:
● jenkins.service - LSB: Jenkins Automation Server Loaded: loaded (/etc/rc.d/init.d/jenkins; bad; vendor preset: disabled) Active: failed (Result: exit-code) since Fri 2021-12-03 11:46:25 CST; 4s ago Docs: man:systemd-sysv-generator(8) Process: 12366 ExecStart=/etc/rc.d/init.d/jenkins start (code=exited, status=127) Dec 03 11:46:25 localhost.localdomain systemd[1]: Starting LSB: Jenkins Automation Server... Dec 03 11:46:25 localhost.localdomain jenkins[12366]: Starting Jenkins /etc/rc.d/init.d/jenkins: line 120: daemonize: command not found Dec 03 11:46:25 localhost.localdomain jenkins[12366]: [FAILED] Dec 03 11:46:25 localhost.localdomain systemd[1]: jenkins.service: control process exited, code=exited status=127 Dec 03 11:46:25 localhost.localdomain systemd[1]: Failed to start LSB: Jenkins Automation Server. Dec 03 11:46:25 localhost.localdomain systemd[1]: Unit jenkins.service entered failed state. Dec 03 11:46:25 localhost.localdomain systemd[1]: jenkins.service failed. Two important messages Error code 127 daemonize command not found
Solution:
yum -y install daemonize1. An error is reported when using Flink to store parquet files
21/07/15 14:24:47 INFO checkpoint.CheckpointCoordinator: Triggering checkpoint 2 (type=CHECKPOINT) @ 1626330287296 for job 06a80360b770722f8dd3e41252a5a8d7. 21/07/15 14:24:47 INFO filesystem.Buckets: Subtask 2 checkpointing for checkpoint with id=2 (max part counter=0). 21/07/15 14:24:47 INFO filesystem.Buckets: Subtask 1 checkpointing for checkpoint with id=2 (max part counter=0). 21/07/15 14:24:47 INFO jobmaster.JobMaster: Trying to recover from a global failure. org.apache.flink.util.FlinkRuntimeException: Exceeded checkpoint tolerable failure threshold. at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleJobLevelCheckpointException(CheckpointFailureManager.java:66) at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:1739) at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:1716) at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.access$600(CheckpointCoordinator.java:93) at org.apache.flink.runtime.checkpoint.CheckpointCoordinator$CheckpointCanceller.run(CheckpointCoordinator.java:1849) at java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source) at java.util.concurrent.FutureTask.run(Unknown Source) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(Unknown Source) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(Unknown Source) at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) at java.lang.Thread.run(Unknown Source)
1). add checkpoint time
2). Look at the POM file version conflict of the flash parquet package. The parquet Avro version is 1.10.0 [the flash.version is 1.11.3]
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.10.0</version>
</dependency>
2. Flink applications rely on third-party packages
Solution: access Maven plug-in and pack fat
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
Add provided to unnecessary jar packages
The above provided will cause the following errors
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/api/common/typeinfo/TypeInformation at com.zhangwen.bigdata.qy.logs.writer.LogToOssParquetWriterLogRecord.main(LogToOssParquetWriterLogRecord.scala) Caused by: java.lang.ClassNotFoundException: org.apache.flink.api.common.typeinfo.TypeInformation at java.net.URLClassLoader.findClass(Unknown Source) at java.lang.ClassLoader.loadClass(Unknown Source) at sun.misc.Launcher$AppClassLoader.loadClass(Unknown Source) at java.lang.ClassLoader.loadClass(Unknown Source) ... 1 more
Solution:
3. The Flink program runs normally locally, and the submitted cluster message: java.lang.nosuchmethoderror: org.apache.parquet.hadoop.parquetwriter $builder. (lorg/Apache/parquet/Io/outputFile;) v
Cause of the problem: the version of parquet Mr related jar package referenced in Flink is inconsistent with that in CDH, resulting in nosucjmethoderror
solution: recompile parquet Avro, parquet common, parquet column, parquet Hadoop, parquet format and Flink parquet through Maven shade plugin, and put them into ${flink_home}\Lib\Directory:
Add the following configuration files to pom.xml of parquet Avro, parquet common, parquet column and parquet Hadoop
<pre><code class="xml">
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<shadedArtifactAttached>true</shadedArtifactAttached>
<!--This indicates that the generated shade package What is its suffix name, through this suffix name, in the reference of the time, there will be no reference to the shade package situation. -->
<shadedClassifierName>shade</shadedClassifierName>
<relocations>
<relocation>
<! -- Source package name -->
<pattern>org.apache.parquet</pattern>
<! -- destination package name -->
<shadedPattern>shaded.org.apache.parquet</shadedPattern>
</relocation>
</relocations>
</configuration>
</execution>
</executions>
</plugin>
</code></pre>
Modify parquet format as follows
<pre><code class="xml">
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<includes>
<include>org.apache.thrift:libthrift</include>
</includes>
</artifactSet>
<filters>
<filter>
<!-- Sigh. The Thrift jar contains its source -->
<artifact>org.apache.thrift:libthrift</artifact>
<excludes>
<exclude>**/*.java</exclude>
<exclude>META-INF/LICENSE.txt</exclude>
<exclude>META-INF/NOTICE.txt</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>org.apache.thrift</pattern>
<shadedPattern>${shade.prefix}.org.apache.thrift</shadedPattern>
</relocation>
<relocation>
<pattern>org.apache.parquet</pattern>
<shadedPattern>shaded.org.apache.parquet</shadedPattern>
</relocation>
</relocations>
</configuration>
</execution>
</executions>
</plugin>
</code></pre>
The Flink parquet pom.xml is modified as follows
<pre><code class="xml">
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<shadedArtifactAttached>true</shadedArtifactAttached>
<!--This indicates that the generated shade package What is its suffix name, through this suffix name, in the reference of the time, there will be no reference to the shade package situation. -->
<shadedClassifierName>shade</shadedClassifierName>
<!
<artifactSet>
<includes>
<include>org.apache.flink:flink-formats</include>
</includes>
</artifactSet>
<relocations>
<relocation>
<! -- Source package name -->
<pattern>org.apache.flink.formats.parquet</pattern>
<! -- destination package name -->
<shadedPattern>shaded.org.apache.flink.formats.parquet</shadedPattern>
</relocation>
<relocation>
<!-- package name -->
<pattern>org.apache.parquet</pattern>
<!-- destination package name -->
<shadedPattern>shaded.org.apache.parquet</shadedPattern>
</relocation>
</relocations>
</configuration>
</execution>
</executions>
</plugin>
</code></pre>
You need to install the jar package locally before the idea can reference it
mvn install:install-file -DgroupId=shade.org.apache.parquet -DartifactId=parquet-common -Dversion=1.10.2-SNAPSHOT -Dpackaging=jar -Dfile=E:\software\install\maven\repo\org\apache\parquet\parquet-common\1.10.2-SNAPSHOT\parquet-common-1.10.2-SNAPSHOT-shade.jar mvn install:install-file -DgroupId=shade.org.apache.parquet -DartifactId=parquet-avro -Dversion=1.10.2-SNAPSHOT -Dpackaging=jar -Dfile=E:\software\install\maven\repo\org\apache\parquet\parquet-avro\1.10.2-SNAPSHOT\parquet-avro-1.10.2-SNAPSHOT-shade.jar mvn install:install-file -DgroupId=shade.org.apache.parquet -DartifactId=parquet-column -Dversion=1.10.2-SNAPSHOT -Dpackaging=jar -Dfile=E:\software\install\maven\repo\org\apache\parquet\parquet-column\1.10.2-SNAPSHOT\parquet-column-1.10.2-SNAPSHOT-shade.jar mvn install:install-file -DgroupId=shade.org.apache.parquet -DartifactId=parquet-hadoop -Dversion=1.10.2-SNAPSHOT -Dpackaging=jar -Dfile=E:\software\install\maven\repo\org\apache\parquet\parquet-hadoop\1.10.2-SNAPSHOT\parquet-hadoop-1.10.2-SNAPSHOT-shade.jar mvn install:install-file -DgroupId=shade.org.apache.flink -DartifactId=flink-formats -Dversion=1.11.3-shade -Dpackaging=jar -Dfile=D:\work\github\flink\flink-1.11.3-src\flink-1.11.3\flink-formats\flink-parquet\target\flink-parquet_2.11-1.11.3-shade.jar mvn install:install-file -DgroupId=shade.org.apache.parquet -DartifactId=parquet-format -Dversion=1.10.2-SNAPSHOT -Dpackaging=jar -Dfile=E:\lib\parquet-format-2.4.0.jar
Change the flash application pom.xml to
<pre>
<dependency>
<groupId>shade.org.apache.flink</groupId>
<artifactId>flink-formats</artifactId>
<version>1.11.3-shade</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>shade.org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.10.2-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>shade.org.apache.parquet</groupId>
<artifactId>parquet-common</artifactId>
<version>1.10.2-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.parquet/parquet-hadoop -->
<dependency>
<groupId>shade.org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>1.10.2-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
</pre>
The imported package name of the flick application is changed to:
import shaded.org.apache.flink.formats.parquet.{ParquetBuilder, ParquetWriterFactory}
import shaded.org.apache.parquet.avro.AvroParquetWriter
import shaded.org.apache.parquet.hadoop.ParquetWriter
import shaded.org.apache.parquet.hadoop.metadata.CompressionCodecName
import shaded.org.apache.parquet.io.OutputFile
Finally, you need to put the jar package into ${flink_home}\lib
Problem description
This error occurs when I use the opencv3.4.16 official so file in Android studio
Sort by Pvalue from smallest to largest
Change the build.gradle file
Change arguments “- dandroid_stl = C + + _shared”
to arguments “- dandroid_stl = gnustl_shared”
Possible causes:
Opencv3.4.16 officially uses the gun compiler, so it is specified as gnustl_shared
This is because the R language default behavior is a unique identifier
Duplicate lines need to be removed
This is very common in differential expression, because different IDs may correspond to the same gene_ symbol
genes_sig <- res_sig %>%
arrange(adj.P.Val) %>% #Sort by Pvalue from smallest to largest
as tibble() %>%
column_to_rownames(var = "gene_symbol")report errors
Error in `.rowNamesDF<-`(x, value = value) :
duplicate 'row.names' are not allowed
In addition: Warning message:
non-unique values when setting 'row.names': ‘’, ‘ AMY2A ’, ‘ ANKRD20A3 ’, ‘ ANXA8 ’, ‘ AQP12B ’, ‘ AREG ’, ‘ ARHGDIG ’, ‘ CLIC1 ’, ‘ CTRB2 ’, ‘ DPCR1 ’, ‘ FAM72B ’, ‘ FCGR3A ’, ‘ FER1L4 ’, ‘ HBA2 ’, ‘ HIST1H4I ’, ‘ HIST2H2AA4 ’, ‘ KRT17P2 ’, ‘ KRT6A ’, ‘ LOC101059935 ’, ‘ MRC1 ’, ‘ MT-TD ’, ‘ MT-TV ’, ‘ NPR3 ’, ‘ NRP2 ’, ‘ PGA3 ’, ‘ PRSS2 ’, ‘ REEP3 ’, ‘ RNU6-776P ’, ‘ SFTA2 ’, ‘ SLC44A4 ’, ‘ SNORD116-3 ’, ‘ SNORD116-5 ’, ‘ SORBS2 ’, ‘ TNXB ’, ‘ TRIM31 ’, ‘ UGT2B15 ’ Try to use the duplicated() function
res_df = res_df[!duplicated(res_df),] %>% as.tibble() %>%
column_to_rownames(var = "gene_symbol") Still not?Duplicated removing duplicate values still shows that duplicate values exist
Error in `.rowNamesDF<-`(x, value = value) :
duplicate 'row.names' are not allowed
In addition: Warning message:
non-unique values when setting 'row.names': ‘ AMY2A ’, ‘ ANKRD20A3 ’, ‘ ANXA8 ’, ‘ AQP12B ’, ‘ AREG ’, ‘ ARHGDIG ’, ‘ CLIC1 ’, ‘ CTRB2 ’, ‘ DPCR1 ’, ‘ FAM72B ’, ‘ FCGR3A ’, ‘ FER1L4 ’, ‘ HIST1H4I ’, ‘ HIST2H2AA4 ’, ‘ KRT17P2 ’, ‘ KRT6A ’, ‘ LOC101059935 ’, ‘ MT-TD ’, ‘ MT-TV ’, ‘ NPR3 ’, ‘ NRP2 ’, ‘ PGA3 ’, ‘ PRSS2 ’, ‘ REEP3 ’, ‘ RNU6-776P ’, ‘ SFTA2 ’, ‘ SORBS2 ’, ‘ TRIM31 ’, ‘ UGT2B15 ’ Another way is to use the uniqe function of the dyplr package
res_df = res_df %>% distinct(gene_symbol,.keep_all = T) %>% as.tibble() %>%
column_to_rownames(var = "gene_symbol") Successfully solved
Problem description
INSERT OVERWRITE table temp.push_temp PARTITION(d_layer='app_video_uid_d_1')
SELECT ...
Could not be cleaned up:
Failed with exception Directory hdfs://Ucluster/user/hive/warehouse/temp.db/push_temp/d_layer=app_video_uid_d_1 could not be cleaned up.
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask. Directory hdfs://Ucluster/user/hive/warehouse/temp.db/push_temp/d_layer=app_video_uid_d_1 could not be cleaned up.
drwxrwxrwt - lisi supergroup 0 2021-11-29 15:04 /user/hive/warehouse/temp.db/push_temp/d_layer=app_video_uid_d_1
Cause of problem
Three words – viscous bit
look carefully at the directory permissions above. The last bit is “t”, which means that the sticky bit is enabled for the directory, that is, only the owner of the directory can delete files under the directory
# Non-owner delete sticky bit files
$ hadoop fs -rm /user/hive/warehouse/temp.db/push_temp/d_layer=app_video_uid_d_1/000000_0
21/11/29 16:32:59 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 7320 minutes, Emptier interval = 0 minutes.
rm: Failed to move to trash: hdfs://Ucluster/user/hive/warehouse/temp.db/push_temp/d_layer=app_video_uid_d_1/000000_0: Permission denied by sticky bit setting: user=admin, inode=000000_0
Because insert overwrite needs to delete the original file in the directory, but it cannot be deleted due to sticky bits, resulting in HQL execution failure
Solution
Cancel the sticky bit of the directory
# Cancellation of sticking position
hadoop fs -chmod -R o-t /user/hive/warehouse/temp.db/push_temp/d_layer=app_video_uid_d_1
# Open sticking position
hadoop fs -chmod -R o+t /user/hive/warehouse/temp.db/push_temp/d_layer=app_video_uid_d_1
C++ Error:
Undefined symbols for architecture x86_64:
“StackMy<std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > >::~StackMy()”, referenced from:
_main in main.cpp.o
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
Lastly, it was found that the error was caused by a custom destructor in the header file, but the destructor was not implemented.
Tensorflow GPU reports an error of self_ traceback = tf_ stack.extract_ stack()
Reason 1: the video memory is full
At this time, you can view the GPU running status by entering the command NVIDIA SMI in CMD,
most likely because of the batch entered_ Size or the number of hidden layers is too large, and the display memory is full and the data cannot be loaded completely. At this time, the GPU will not start working (similar to memory and CPU), and the utilization rate is 0%
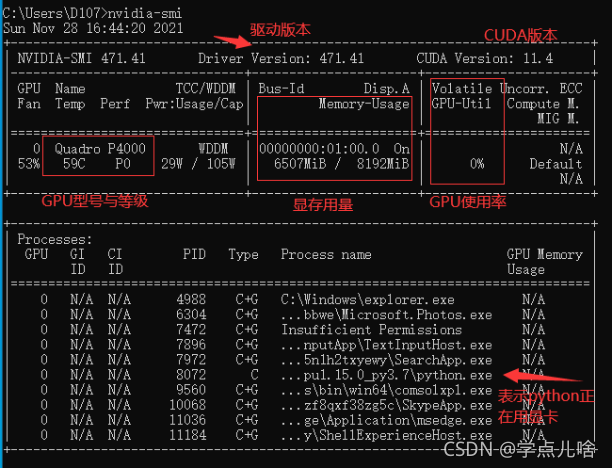
Solution to reason 1:
1. turn down bath_Size and number of hidden layers, reduce the picture resolution, close other software that consumes video memory, and other methods that can reduce the occupation of video memory, and then try again. If the video memory has only two G’s, it’s better to run with CPU
2.
1. Use with code
os.environ['CUDA_VISIBLE_DEVICES'] = '/gpu:0'
config = tf.compat.v1.ConfigProto(allow_soft_placement=True)
config.gpu_options.per_process_gpu_memory_fraction = 0.7
tf.compat.v1.keras.backend.set_session(tf.compat.v1.Session(config=config))
Reason 2. There are duplicate codes and the calling programs overlap
I found this when saving and loading the model. The assignment and operation of variables are repeatedly written during saving and loading, and an error self is reported during loading_traceback = tf_stack.extract_Stack()
There are many reasons for the tensorflow error self_traceback = tf_stack.extract_stack()
the error codes are as follows:
import tensorflow as tf
a = tf.Variable(5., tf.float32)
b = tf.Variable(6., tf.float32)
num = 10
model_save_path = './model/'
model_name = 'model'
saver = tf.train.Saver()
with tf.Session() as sess:
init_op = tf.compat.v1.global_variables_initializer()
sess.run(init_op)
for step in np.arange(num):
c = sess.run(tf.add(a, b))
saver.save(sess, os.path.join(model_save_path, model_name), global_step=step)
print("Parameters saved successfully!")
a = tf.Variable(5., tf.float32)
b = tf.Variable(6., tf.float32) # Note the repetition here
num = 10
model_save_path = './model/'
model_name = 'model'
saver = tf.train.Saver() # Note the repetition here
with tf.Session() as sess:
init_op = tf.compat.v1.global_variables_initializer()
sess.run(init_op)
ckpt = tf.train.get_checkpoint_state(model_save_path)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
print("load success")
Running the code will report an error: self_traceback = tf_stack.extract_stack()
Reason 2 solution
when Saver = TF.Train.Saver() in parameter loading is commented out or commented out
a = tf.Variable(5., tf.float32)
b = tf.Variable(6., tf.float32) # Note the repetition here
The model will no longer report errors. I don’t know the specific reason.
Today, I plan to deploy the web file for JSP. When I open the web.xml file, I start to report errors, as shown in the following figure < Web app underline error
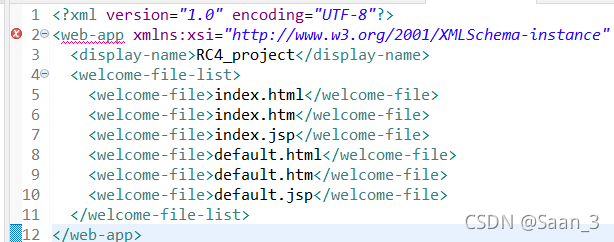
later, a new line is added in front of xmlns, that is, a new line character is added, and no error is reported
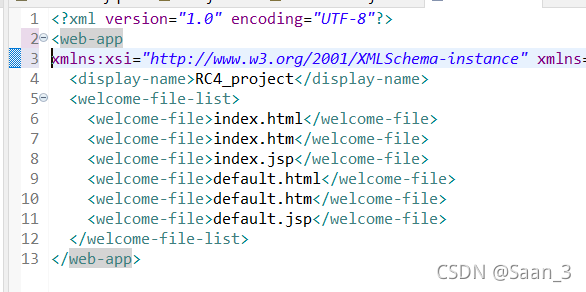
Problem reporting error
reason
All sh script files in the project are not transcoded
Solution:
Right-click in the blank space of the computer (make sure Git is installed) to open git bash here, and then CD to the specified path. Enter the following command
find ./ -name "*.sh" | xargs dos2unix