Project scenario:
QT network programming appears when requesting the website: qt.network.ssl: QSslSocket::connectToHostEncrypted: TLS initialization failed
Problem description

Cause analysis:
The computer may not have the correct OpenSSL installed.
Solution:
1. we use the following code to determine the OpenSSL version our QT support
#include <QSslSocket>
#include <QDebug>
qDebug()<< QSslSocket::sslLibraryBuildVersionString();
My output here is: 
you can see that my OpenSSL version is bit 1.1.1. Download the corresponding version of OpenSSL
2. on this website: http://slproweb.com/products/Win32OpenSSL.html Download the corresponding OpenSSL version. One thing to note is: if you use MinGW 32-bit kit, Download

otherwise, if you use MinGW 64 bit kit, Download win64 OpenSSL. Note that both compilers only need to download the EXE executable of the light version.
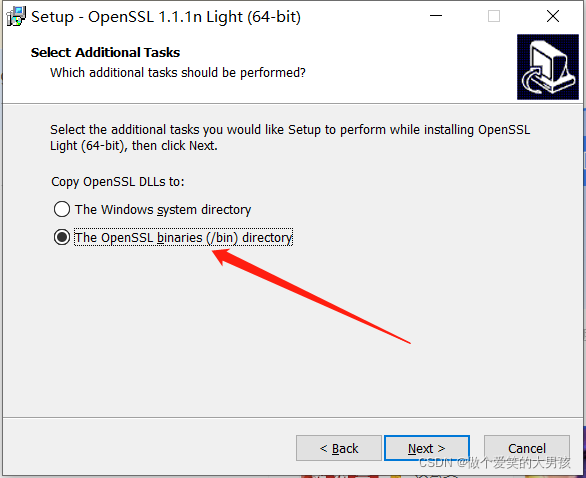
3. Install OpenSSL
click next all the time. In the last step, set the folder to bin.
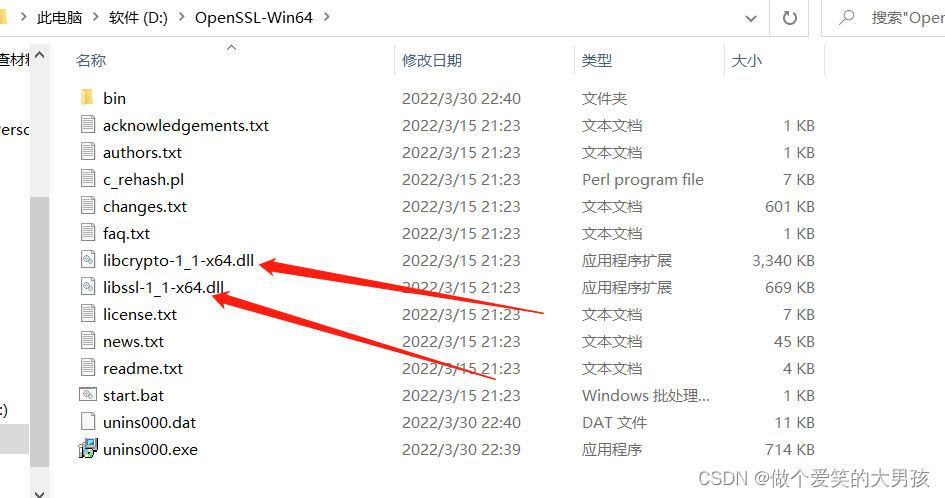
 4. Copy the file
4. Copy the file
I downloaded the Win64 version of OpenSSL here. Therefore, copy the libcrypto-1_1-x64.dll and libssl-1_1-x64.dll files in the OpenSSL folder to the qt installation directory. The specific directory is here: D:\Qt\Qt5.14.0\5.14.0\ mingw73_64\bin. If you download 32-bit, you only need to put it in the D:\Qt\Qt5.14.0\5.14.0\mingw73_32\bin directory, and the others are similar.
 5. Ends
5. Ends
if you run the project file again, QT will not report the error: qt.network.ssl: QSslSocket::connectToHostEncrypted: TLS initialization failed