1. An error is reported when using Flink to store parquet files
21/07/15 14:24:47 INFO checkpoint.CheckpointCoordinator: Triggering checkpoint 2 (type=CHECKPOINT) @ 1626330287296 for job 06a80360b770722f8dd3e41252a5a8d7. 21/07/15 14:24:47 INFO filesystem.Buckets: Subtask 2 checkpointing for checkpoint with id=2 (max part counter=0). 21/07/15 14:24:47 INFO filesystem.Buckets: Subtask 1 checkpointing for checkpoint with id=2 (max part counter=0). 21/07/15 14:24:47 INFO jobmaster.JobMaster: Trying to recover from a global failure. org.apache.flink.util.FlinkRuntimeException: Exceeded checkpoint tolerable failure threshold. at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleJobLevelCheckpointException(CheckpointFailureManager.java:66) at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:1739) at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:1716) at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.access$600(CheckpointCoordinator.java:93) at org.apache.flink.runtime.checkpoint.CheckpointCoordinator$CheckpointCanceller.run(CheckpointCoordinator.java:1849) at java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source) at java.util.concurrent.FutureTask.run(Unknown Source) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(Unknown Source) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(Unknown Source) at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) at java.lang.Thread.run(Unknown Source)
1). add checkpoint time
2). Look at the POM file version conflict of the flash parquet package. The parquet Avro version is 1.10.0 [the flash.version is 1.11.3]
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.10.0</version>
</dependency>
2. Flink applications rely on third-party packages
Solution: access Maven plug-in and pack fat
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
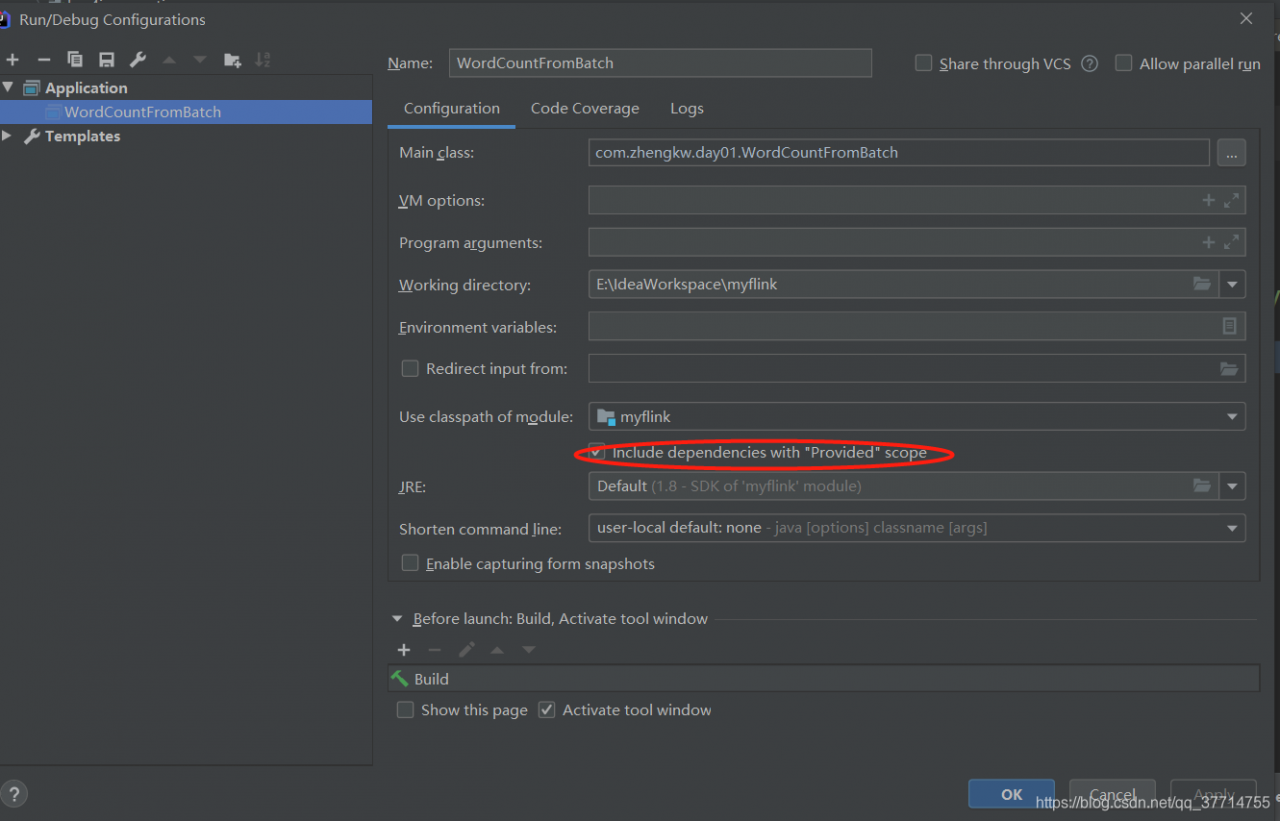
Add provided to unnecessary jar packages
The above provided will cause the following errors
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/api/common/typeinfo/TypeInformation at com.zhangwen.bigdata.qy.logs.writer.LogToOssParquetWriterLogRecord.main(LogToOssParquetWriterLogRecord.scala) Caused by: java.lang.ClassNotFoundException: org.apache.flink.api.common.typeinfo.TypeInformation at java.net.URLClassLoader.findClass(Unknown Source) at java.lang.ClassLoader.loadClass(Unknown Source) at sun.misc.Launcher$AppClassLoader.loadClass(Unknown Source) at java.lang.ClassLoader.loadClass(Unknown Source) ... 1 more
Solution:
3. The Flink program runs normally locally, and the submitted cluster message: java.lang.nosuchmethoderror: org.apache.parquet.hadoop.parquetwriter $builder. (lorg/Apache/parquet/Io/outputFile;) v
Cause of the problem: the version of parquet Mr related jar package referenced in Flink is inconsistent with that in CDH, resulting in nosucjmethoderror
solution: recompile parquet Avro, parquet common, parquet column, parquet Hadoop, parquet format and Flink parquet through Maven shade plugin, and put them into ${flink_home}\Lib\Directory:
Add the following configuration files to pom.xml of parquet Avro, parquet common, parquet column and parquet Hadoop
<pre><code class="xml">
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<shadedArtifactAttached>true</shadedArtifactAttached>
<!--This indicates that the generated shade package What is its suffix name, through this suffix name, in the reference of the time, there will be no reference to the shade package situation. -->
<shadedClassifierName>shade</shadedClassifierName>
<relocations>
<relocation>
<! -- Source package name -->
<pattern>org.apache.parquet</pattern>
<! -- destination package name -->
<shadedPattern>shaded.org.apache.parquet</shadedPattern>
</relocation>
</relocations>
</configuration>
</execution>
</executions>
</plugin>
</code></pre>
Modify parquet format as follows
<pre><code class="xml">
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<includes>
<include>org.apache.thrift:libthrift</include>
</includes>
</artifactSet>
<filters>
<filter>
<!-- Sigh. The Thrift jar contains its source -->
<artifact>org.apache.thrift:libthrift</artifact>
<excludes>
<exclude>**/*.java</exclude>
<exclude>META-INF/LICENSE.txt</exclude>
<exclude>META-INF/NOTICE.txt</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>org.apache.thrift</pattern>
<shadedPattern>${shade.prefix}.org.apache.thrift</shadedPattern>
</relocation>
<relocation>
<pattern>org.apache.parquet</pattern>
<shadedPattern>shaded.org.apache.parquet</shadedPattern>
</relocation>
</relocations>
</configuration>
</execution>
</executions>
</plugin>
</code></pre>
The Flink parquet pom.xml is modified as follows
<pre><code class="xml">
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<shadedArtifactAttached>true</shadedArtifactAttached>
<!--This indicates that the generated shade package What is its suffix name, through this suffix name, in the reference of the time, there will be no reference to the shade package situation. -->
<shadedClassifierName>shade</shadedClassifierName>
<!
<artifactSet>
<includes>
<include>org.apache.flink:flink-formats</include>
</includes>
</artifactSet>
<relocations>
<relocation>
<! -- Source package name -->
<pattern>org.apache.flink.formats.parquet</pattern>
<! -- destination package name -->
<shadedPattern>shaded.org.apache.flink.formats.parquet</shadedPattern>
</relocation>
<relocation>
<!-- package name -->
<pattern>org.apache.parquet</pattern>
<!-- destination package name -->
<shadedPattern>shaded.org.apache.parquet</shadedPattern>
</relocation>
</relocations>
</configuration>
</execution>
</executions>
</plugin>
</code></pre>
You need to install the jar package locally before the idea can reference it
mvn install:install-file -DgroupId=shade.org.apache.parquet -DartifactId=parquet-common -Dversion=1.10.2-SNAPSHOT -Dpackaging=jar -Dfile=E:\software\install\maven\repo\org\apache\parquet\parquet-common\1.10.2-SNAPSHOT\parquet-common-1.10.2-SNAPSHOT-shade.jar mvn install:install-file -DgroupId=shade.org.apache.parquet -DartifactId=parquet-avro -Dversion=1.10.2-SNAPSHOT -Dpackaging=jar -Dfile=E:\software\install\maven\repo\org\apache\parquet\parquet-avro\1.10.2-SNAPSHOT\parquet-avro-1.10.2-SNAPSHOT-shade.jar mvn install:install-file -DgroupId=shade.org.apache.parquet -DartifactId=parquet-column -Dversion=1.10.2-SNAPSHOT -Dpackaging=jar -Dfile=E:\software\install\maven\repo\org\apache\parquet\parquet-column\1.10.2-SNAPSHOT\parquet-column-1.10.2-SNAPSHOT-shade.jar mvn install:install-file -DgroupId=shade.org.apache.parquet -DartifactId=parquet-hadoop -Dversion=1.10.2-SNAPSHOT -Dpackaging=jar -Dfile=E:\software\install\maven\repo\org\apache\parquet\parquet-hadoop\1.10.2-SNAPSHOT\parquet-hadoop-1.10.2-SNAPSHOT-shade.jar mvn install:install-file -DgroupId=shade.org.apache.flink -DartifactId=flink-formats -Dversion=1.11.3-shade -Dpackaging=jar -Dfile=D:\work\github\flink\flink-1.11.3-src\flink-1.11.3\flink-formats\flink-parquet\target\flink-parquet_2.11-1.11.3-shade.jar mvn install:install-file -DgroupId=shade.org.apache.parquet -DartifactId=parquet-format -Dversion=1.10.2-SNAPSHOT -Dpackaging=jar -Dfile=E:\lib\parquet-format-2.4.0.jar
Change the flash application pom.xml to
<pre>
<dependency>
<groupId>shade.org.apache.flink</groupId>
<artifactId>flink-formats</artifactId>
<version>1.11.3-shade</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>shade.org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.10.2-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>shade.org.apache.parquet</groupId>
<artifactId>parquet-common</artifactId>
<version>1.10.2-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.parquet/parquet-hadoop -->
<dependency>
<groupId>shade.org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>1.10.2-SNAPSHOT</version>
<scope>provided</scope>
</dependency>
</pre>
The imported package name of the flick application is changed to:
import shaded.org.apache.flink.formats.parquet.{ParquetBuilder, ParquetWriterFactory}
import shaded.org.apache.parquet.avro.AvroParquetWriter
import shaded.org.apache.parquet.hadoop.ParquetWriter
import shaded.org.apache.parquet.hadoop.metadata.CompressionCodecName
import shaded.org.apache.parquet.io.OutputFile
Finally, you need to put the jar package into ${flink_home}\lib