ubuntu server docker installed successfully execute the following command to report an error:
systemctl start docker
![]()
method 1: command line add monitoring space
sudo -i
echo 1048576 > /proc/sys/fs/inotify/max_user_watches
exit
method 2: modify the configuration file to make monitoring effective for a long time
sudo vim /etc/sysctl.conf
Add the following statement
to the end of the filefs.inotify.max_user_watches=1048576
nbconvert failed: xelatex not found on PATH, if you have not installed xelatex you may need to do so
problem description
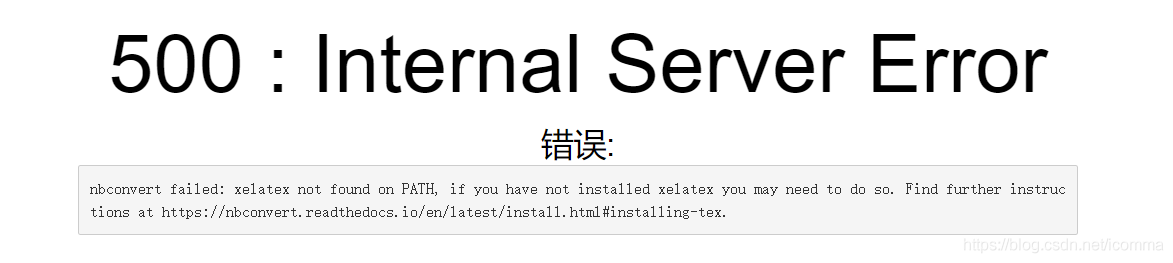
solution:
1. Install pandoc
download pandoc official download http://miktex.org/howto/install-miktex
other available CSDN resources download address
click directly to install, the default installation, you can choose the installation location.
then configure the environment variable to configure the installation path to the system path. For example, I put E:\IDE\Pandoc into the PATH.
2. Install miktex
directly click install, the default installation, you can choose the installation location.
(if the program does not automatically configure environment variables) requires manual configuration of environment variables to configure the installation path to the system path. If mine is put E:\IDE\MiKTeX 2.9\ MiKTeX \bin\x64 in path.
3. Install various macro packages
select convert PDF
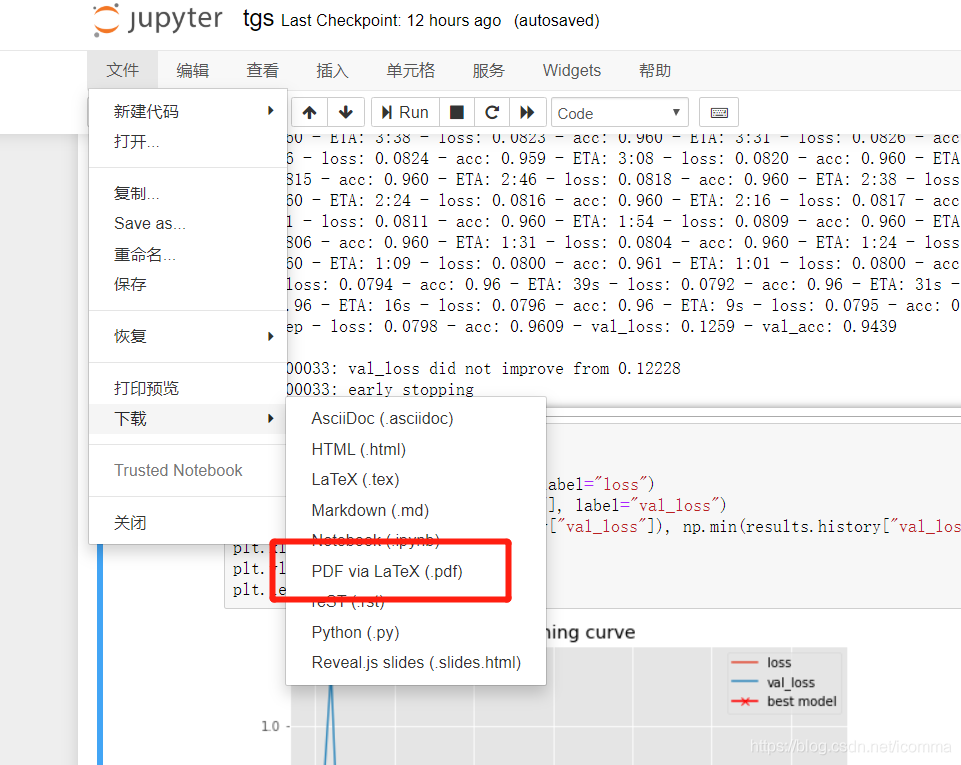
automatically prompt to install various macro packages directly click install (install several times, until the installation is complete…)
note! However, if you encounter Chinese content will report an error, it is unable to convert Chinese, or if you encounter other problems, please feel free to leave a message.
How to Fix Sklearn ValueError: This solver needs samples of at least 2 classes in the data, but the data
error cause
train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose) #请注意X,y
solution: </h3 b>
from sklearn.utils import shuffle
X_shuffle, y_shuffle = shuffle(X, y)
error: </h3 b>
this is because before shuffling, if a CV is done it is possible to have only one class in the dataset. After the shuffle, the data is shuffled, reducing the possibility of the above situation (that is, if the data set is extremely unbalanced, the above bug may still emerge after the shuffle)