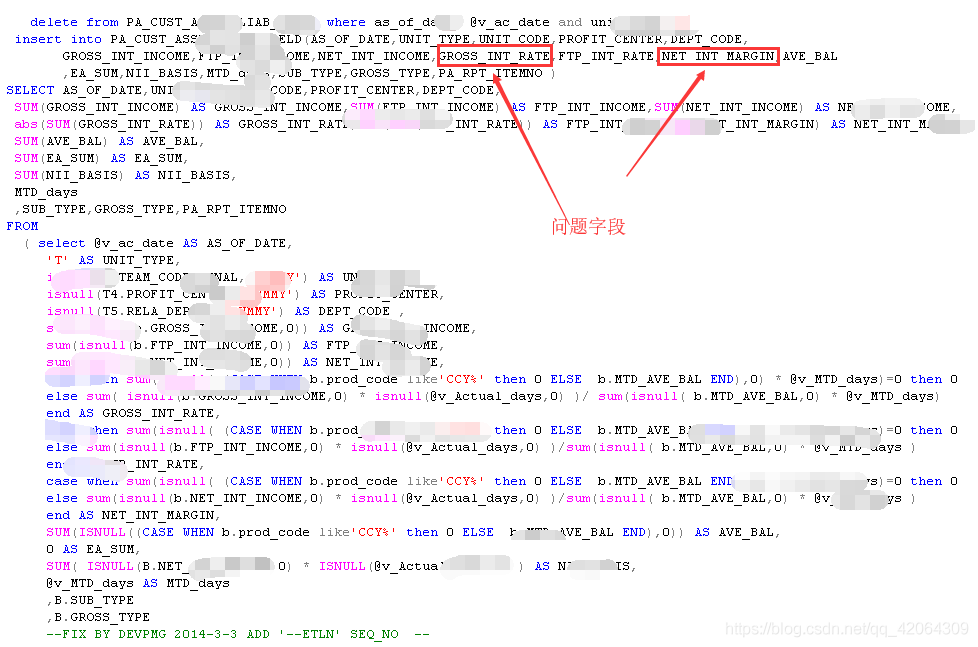
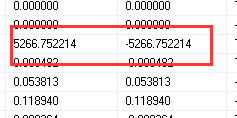
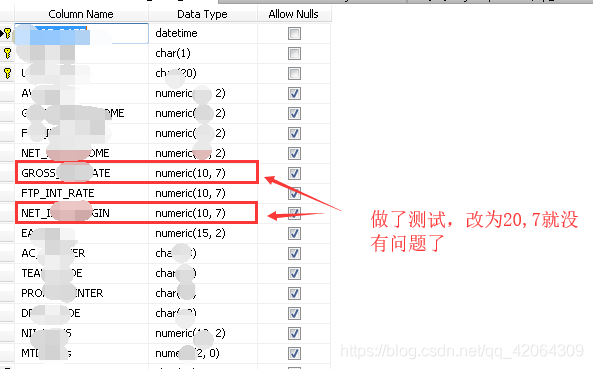
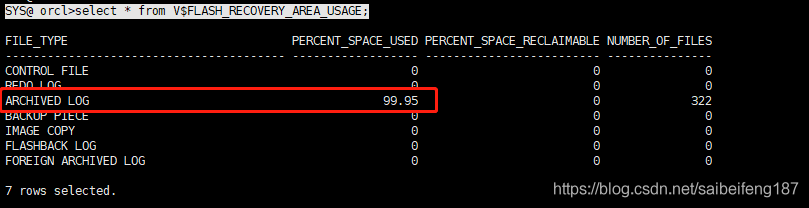
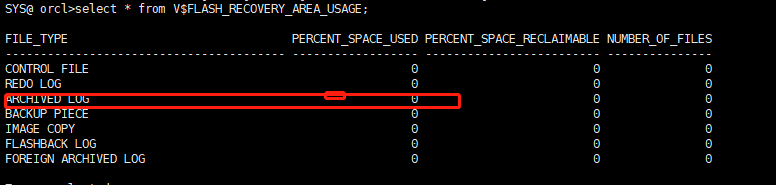
Until the release of ArcGIS Desktop 10 SP1
1: in the desktop ArcGIS9, inside the Geodatabase (PGDB, FGDB, ArcSDE GDB) create a Table (Table), if the Table name begin with GDB (GDB, gdb1, GDBSDF, gdb_3d, etc.) after creating all could not see the form, and in fact is the existence of this Table, if you create a Table with the same Table will be prompted to exist, can use PGDB open Access to view, create a class there is no problem. There is no problem with ArcGIS10.
Problem analysis: currently, just a guess, because ArcGIS9 GDB Schema are GDB_ table in the beginning, the Schema are invisible to users in ArcCatalog, speculation is likely the GDB to block out the beginning of the table, don’t show, but while streamlining the GDB with ArcGIS10 Schema, but there are still four tables, starting with the GDB ArcGIS10 create tables can be seen, a bit surprised, may ArcGIS10 write these four table table name directly in the dead into the program.
2: when using ArcGIS desktop import export data, because the default using ArcGIS to create objects and other elements of the system will create a ObjectID fields, is a unique identifier, some users will use this ObjectID, may record the corresponding ObjectID to correspond to the specified elements, but in the process of data import and export, especially the import, the user will be very depressed these ObjectID rearrangement, so users will not be able to come here to use the ObjectID, how should do?
The ObjectID is rearranged by the Import/Export tool. It is suggested that users use Copy/Paste directly to the data set or element class object. In this way, ObjectID is not rearranged.
3: In the process of data Import using ArcGIS desktop, take Import as an example, “Output Location” in the Import box prompts a small Red Cross, such path does not exist or error-000732 Error occurs?
Solution: the relative path “Database Connections/Connection to lish. Sde” is modified to the absolute path “C:/Users/gis/AppData/Roaming/ESRI Desktop10.0 ArcCatalog/Connection to lish. Sde”, because the problem some machines have similar problems, some machines have no, the reason is still unknown.
4: When SDE creates or imports data containing the field name “AREA”, the field name is automatically prefixed.
Question: This problem exists in ArcGIS9 software, but not in ArcGIS10, for unknown reasons!
5: When creating a LoadRaster dataset, if the whole Raster was loaded and the InputRaster prompted the Red Cross, the Raster object had to be double-clicked and opened into three bands to be loaded. How could the whole Raster object be loaded without being loaded in the form of bands?
Problem analysis: The default Rand Number selected by the user when creating a RasterDataset was “1”. Setting the Rand Number to “3” would solve the problem.
6: Users are using joins to mount tables (element classes versus normal tables), but sometimes a library cannot be mounted on a non-Windows operating system. What can be done?
Problem analysis: Because the Join is using Ole mechanism for articulated, but the Windows operating system default Ole drive, but not the Windows operating system, so the Windows operating system does not support Ole, which does not support the use of the Join, so users can completely change the way in which different using sde commands to complete (sdetable – o create_view), effect is the same, and taking advantage of sde command to create a view can be saved, read-only, This view can be treated as a read-only element class.
sdetable command reference: http://wenku.baidu.com/view/16c6362acfc789eb172dc8c2.html
7: Use ArcCatalog to export ArcSDE data to PGDB and import it in. Some field ranges change.
Problem analysis: Import field for text, for example, because PGDB is usually Access, the text field’s biggest support for Access to 255, more than the value into the remark field, so if a user ArcSDE text field length is 1000, then imported into the PGDB inside because of greater than 255 into the remark field, then pour into ArcSDE, note field does not record length, directly convert note length to CLOB (in Chinese version is more than 2000 of Oracle database with CLOB storage), so, If the user does not want to encounter this phenomenon during the data import and export, please replace the exported PGDB with FGDB.
8: when using ArcMap or ArcGIS Engine for simple operations such as map enlargement, the following phenomenon occurs: the map is blank, “gsrvr.exe” Error or “Network IO Error” Error is prompted?
Problem analysis: First, check whether the user’s database matches the version of your ArcSDE. This error is typical ArcGIS9.3/9.3.1 and Oracle10.2.0.1 (note the small version number of the database). It is suggested that the database should be Oracle10.2.0.3.
9: In the editing process of using ArcCatalog, when saving data, prompt: “Create: An unexpected failure in Dimension”, OrA-20092: Maximum number of Grids per feature(8000) excplug.Ora-06512: In “SDE_ST_DOMAIN_METHODS” line 1487 and so on.
Problem analysis: ArcGIS defaults that an object cannot exceed 8000 grids, which is a hard and fast rule, so it means that the grid setting of the layer edited by the user is too small or an object edited by the user is too large. Either the user deletes the index, rebuilds the index, or the user edits the grid value and replaces it with a larger grid value.
10: Null character missing at the end of the ArcMap import datagram ORA-01480 STR bound value.
Problem solving: if the user has this problem, the user’s machine configuration should be
operating system: Windows Server 2003/2008 Enterprise x64 SP2
Oracle version 10.2.0.4.0-64bit
ArcSDE version: ArcSDE 9.3.1 for oracle10g64
DeskTop version: 9.3.1
vector storage mode: ST_Geometry
this has no way, if the user’s configuration completely meets the above configuration, congratulations, you are so lucky, this is all encountered by you, as of press ArcGIS9.3.1 also did not solve the problem.
The user could either use a direct connection to derive the data, or use BLOB storage instead of ST_Geometry storage, and presumably more people would choose the first option.
11: ArcMap USES Identify figure to find both length and area are 0?
The user must be using SDO_Geometry geometry to store geometry data. The structure is not at all like the ST_Geometry structure where length and area can be recorded, so this is normal.