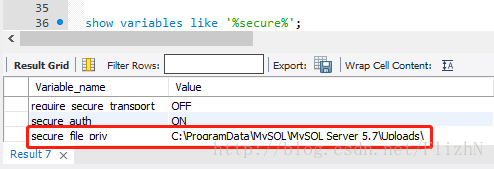
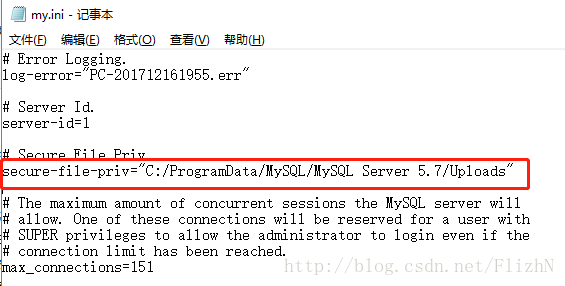
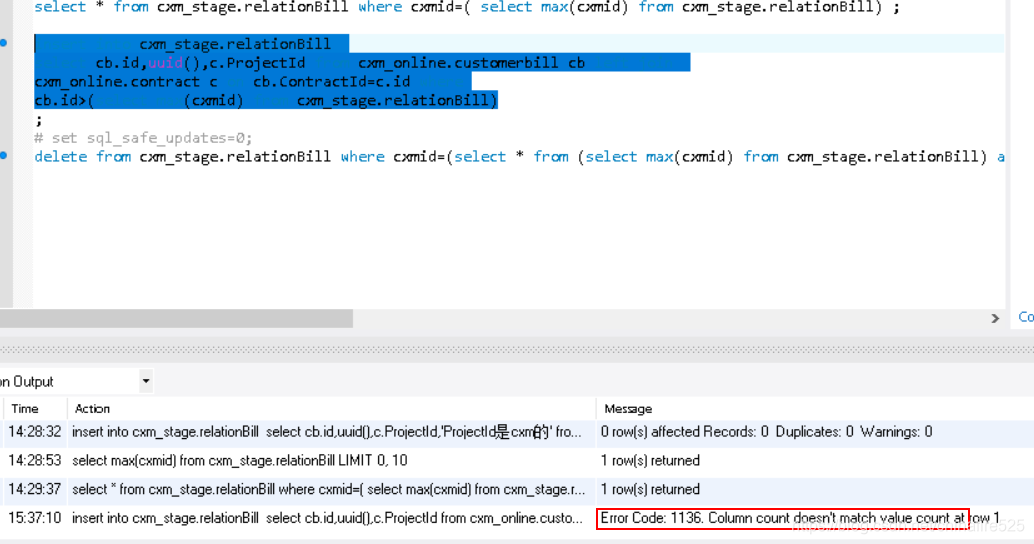
ERROR: column “t.domainid” must appear in the GROUP BY clause or be used in an aggregate function
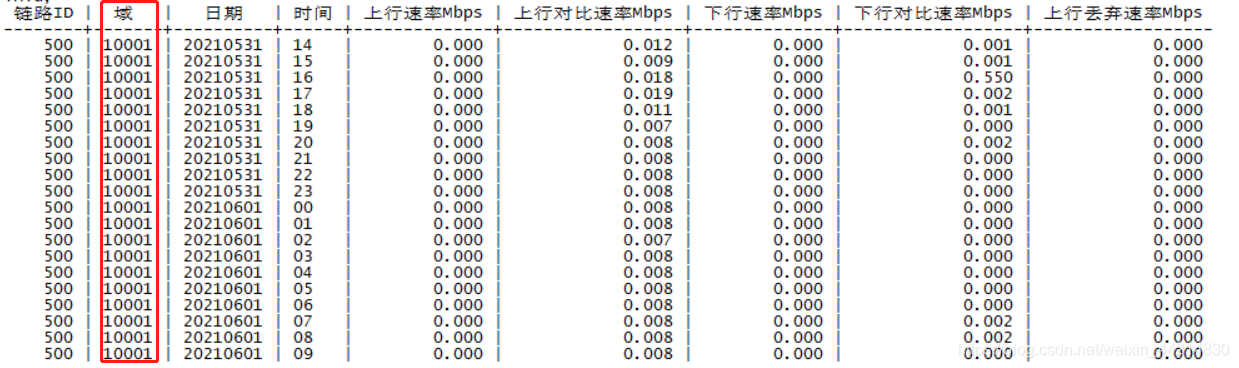
The data table is as follows.
select * from td_link_1h_d_20210427 limit 10;
time | linkid | domainid | ipversion | upbps | dnbps | updisbps | dndisbps | upmaxbps | dnmaxbps | upminbps | dnminbps
------------+--------+----------+-----------+-------------+-------------+----------+-----------+-------------+-------------+-------------+-------------
1619452800 | 4401 | 10001 | 4 | 147856388 | 5923764 | 0 | 0 | 166378265 | 12533696 | 123212832 | 2247349
1619452800 | 5002 | 10001 | 6 | 0 | 0 | 0 | 0 | 4 | 4 | 0 | 0
1619452800 | 5503 | 10001 | 6 | 0 | 149 | 0 | 0 | 2 | 194 | 0 | 102
1619452800 | 8724 | 10001 | 6 | 238 | 0 | 0 | 0 | 609 | 2 | 23 | 0
1619452800 | 1201 | 10001 | 4 | 255570975 | 4111481619 | 3035634 | 19703184 | 292787968 | 4751690795 | 209619623 | 3334699801
1619452800 | 4700 | 10001 | 4 | 19626007220 | 8697825644 | 0 | 0 | 23504765993 | 9930189669 | 16586678202 | 7205462505
1619452800 | 13249 | 10001 | 6 | 3066257 | 262560 | 0 | 12 | 5817708 | 339458 | 954397 | 217159
1619452800 | 9156 | 10001 | 4 | 19773923700 | 2984265593 | 0 | 0 | 22335976464 | 3388045463 | 17124116138 | 2543622015
1619452800 | 11741 | 10001 | 4 | 5628620627 | 20052950343 | 51741713 | 318854796 | 6958633624 | 23485369390 | 4357751762 | 15861228522
1619452800 | 2700 | 10001 | 4 | 657502770 | 2246692965 | 0 | 0 | 845823645 | 2394743374 | 506699006 | 1880772827
(10 rows)
The following error occurred when querying the database by grouping statistics:
select linkid as "ID",domainid as "Domain",to_char(time::abstime,'YYYYMMDD') as "DATE",to_char(time::abstime,'HH24') as "Time",round(sum(case when time >= '2021-06-07 14:00:00'::abstime::int and time < '2021-06-08 13:59:59'::abstime::int then upbps else 0 end )/1000/1000,3) as "Mbps",round(sum(case when time >= '2021-05-31 14:00:00'::abstime::int and time < '2021-06-01 13:59:59'::abstime::int then upbps else 0 end )/1000/1000,3) as "Mbps",round(sum(case when time >= '2021-06-07 14:00:00'::abstime::int and time < '2021-06-08 13:59:59'::abstime::int then dnbps else 0 end )/1000/1000,3) as "下行速率Mbps",round(sum(case when time >= '2021-05-31 14:00:00'::abstime::int and time < '2021-06-01 13:59:59'::abstime::int then dnbps else 0 end )/1000/1000,3) as "下行对比速率Mbps",round(sum(case when time >= '2021-06-07 14:00:00'::abstime::int and time < '2021-06-08 13:59:59'::abstime::int then updisbps else 0 end )/1000/1000,3) as "上行丢弃速率Mbps" from (((select time, linkid,domainid,ipversion,upbps, dnbps, updisbps from td_link_1h_d_20210531 UNION all select time, linkid,domainid,ipversion,upbps, dnbps, updisbps from td_link_1h_d_20210601) UNION all select time, linkid,domainid,ipversion,upbps, dnbps, updisbps from td_link_1h_d_20210607) UNION all select time, linkid,domainid,ipversion,upbps, dnbps, updisbps from td_link_1h_d_20210608)T where (time >= '2021-06-07 14:00:00'::abstime::int and time < '2021-06-08 13:59:59'::abstime::int ) or (time >= '2021-05-31 14:00:00'::abstime::int and time < '2021-06-01 13:59:59'::abstime::int) and (ipversion in (4,6)) group by linkid,time order by linkid,time;
ERROR: column "t.domainid" must appear in the GROUP BY clause or be used in an aggregate function
LINE 1: select linkid as "ID",domainid as "Domain",to_char(time::abs...
^
After checking a lot of data, it is found that the error means that the domainid field must appear in group by or be used for aggregation function
so I modify the SQL statement, add the domainid field to group by, and then query again
select linkid as "ID",domainid as "Doamin",to_char(time::abstime,'YYYYMMDD') as "DATE",to_char(time::abstime,'HH24') as "TIME",round(sum(case when time >= '2021-06-07 14:00:00'::abstime::int and time < '2021-06-08 13:59:59'::abstime::int then upbps else 0 end )/1000/1000,3) as "上行速率Mbps",round(sum(case when time >= '2021-05-31 14:00:00'::abstime::int and time < '2021-06-01 13:59:59'::abstime::int then upbps else 0 end )/1000/1000,3) as "上行对比速率Mbps",round(sum(case when time >= '2021-06-07 14:00:00'::abstime::int and time < '2021-06-08 13:59:59'::abstime::int then dnbps else 0 end )/1000/1000,3) as "下行速率Mbps",round(sum(case when time >= '2021-05-31 14:00:00'::abstime::int and time < '2021-06-01 13:59:59'::abstime::int then dnbps else 0 end )/1000/1000,3) as "下行对比速率Mbps",round(sum(case when time >= '2021-06-07 14:00:00'::abstime::int and time < '2021-06-08 13:59:59'::abstime::int then updisbps else 0 end )/1000/1000,3) as "上行丢弃速率Mbps" from (((select time, linkid,domainid,ipversion,upbps, dnbps, updisbps from td_link_1h_d_20210531 UNION all select time, linkid,domainid,ipversion,upbps, dnbps, updisbps from td_link_1h_d_20210601) UNION all select time, linkid,domainid,ipversion,upbps, dnbps, updisbps from td_link_1h_d_20210607) UNION all select time, linkid,domainid,ipversion,upbps, dnbps, updisbps from td_link_1h_d_20210608)T where (time >= '2021-06-07 14:00:00'::abstime::int and time < '2021-06-08 13:59:59'::abstime::int ) or (time >= '2021-05-31 14:00:00'::abstime::int and time < '2021-06-01 13:59:59'::abstime::int) and (ipversion in (4,6)) group by linkid,time,domainid order by linkid,time,domainid;