Error Message (Error Codes below):
RuntimeError: Expected object of scalar type Float but got scalar type Double for argument #2 ‘mat1’ in call to _th_addmm
for epoch in range(num_epochs):
# Convert numpy arrays to torch tensors
inputs = torch.from_numpy(x_train)
targets = torch.from_numpy(y_train)
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Epoch [{}/{}] Loss: {:.4f}".format(epoch+1, num_epochs, loss.item()))
Solution:
Method 1. Add
inputs = inputs.float()
targets = targets.float()
model = model.float()
Complete code
for epoch in range(num_epochs):
# Convert numpy arrays to torch tensors
inputs = torch.from_numpy(x_train)
targets = torch.from_numpy(y_train)
inputs = inputs.float()
targets = inputs.float()
model = model.float()
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Epoch [{}/{}] Loss: {:.4f}".format(epoch+1, num_epochs, loss.item()))
Method 2. Add
inputs = inputs.double()
targets = inputs.double()
model = model.double()
Complete code
for epoch in range(num_epochs):
# Convert numpy arrays to torch tensors
inputs = torch.from_numpy(x_train)
targets = torch.from_numpy(y_train)
inputs = inputs.double()
targets = inputs.double()
model = model.double()
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, targets)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Epoch [{}/{}] Loss: {:.4f}".format(epoch+1, num_epochs, loss.item()))
 activate the environment when you run the code: “CONDA activate + your environment name”
activate the environment when you run the code: “CONDA activate + your environment name”  after entering your environment, enter “Python – M PIP install Jupiter”, and then “enter”
after entering your environment, enter “Python – M PIP install Jupiter”, and then “enter” appears at the bottom to indicate that the installation is successful
appears at the bottom to indicate that the installation is successful  then enter: IPython notebook
then enter: IPython notebook 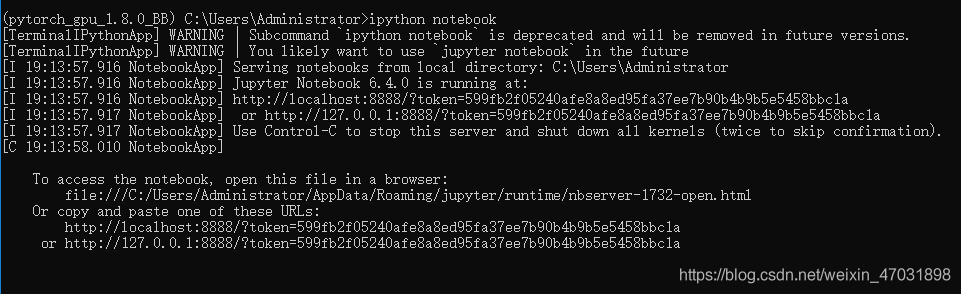 . This page indicates that the problem has been solved
. This page indicates that the problem has been solved