1 Error description
1.1 System Environment
Hardware Environment(Ascend/GPU/CPU): Ascend
Software Environment:
– MindSpore version (source or binary): 1.8.0
– Python version (e.g., Python 3.7.5): 3.7.6
– OS platform and distribution (e.g., Linux Ubuntu 16.04): Ubuntu 4.15.0-74-generic
– GCC/Compiler version (if compiled from source):
1.2 Basic information
1.2.1 Script
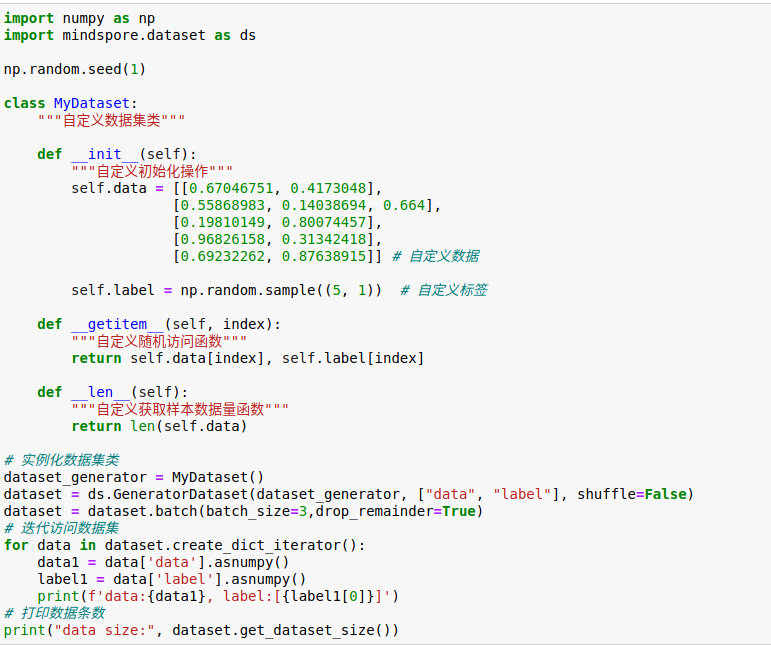
The training script is to update the variable Tensor according to the AddSign algorithm by constructing a single operator network of ApplyPowerSign. The script is as follows:
01 class Net(nn.Cell):
02 def __init__(self):
03 super(Net, self).__init__()
04 self.apply_power_sign = ops.ApplyPowerSign()
05 self.var = Parameter(Tensor(np.array([[0.6, 0.4],
06 [0.1, 0.5]]).astype(np.float16)), name="var")
07 self.m = Parameter(Tensor(np.array([[0.6, 0.5],
08 [0.2, 0.6]]).astype(np.float32)), name="m")
09 self.lr = 0.001
10 self.logbase = np.e
11 self.sign_decay = 0.99
12 self.beta = 0.9
13 def construct(self, grad):
14 out = self.apply_power_sign(self.var, self.m, self.lr, self.logbase,
15 self.sign_decay, self.beta, grad)
16 return out
17
18 net = Net()
19 grad = Tensor(np.array([[0.3, 0.7], [0.1, 0.8]]).astype(np.float32))
20 output = net(grad)
21 print(output)
1.2.2 Error reporting
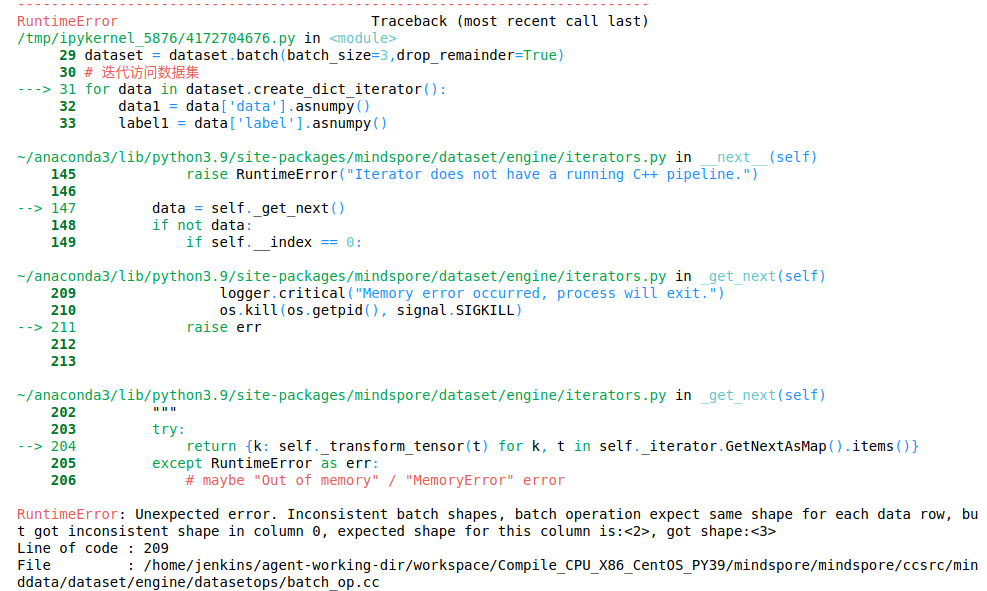
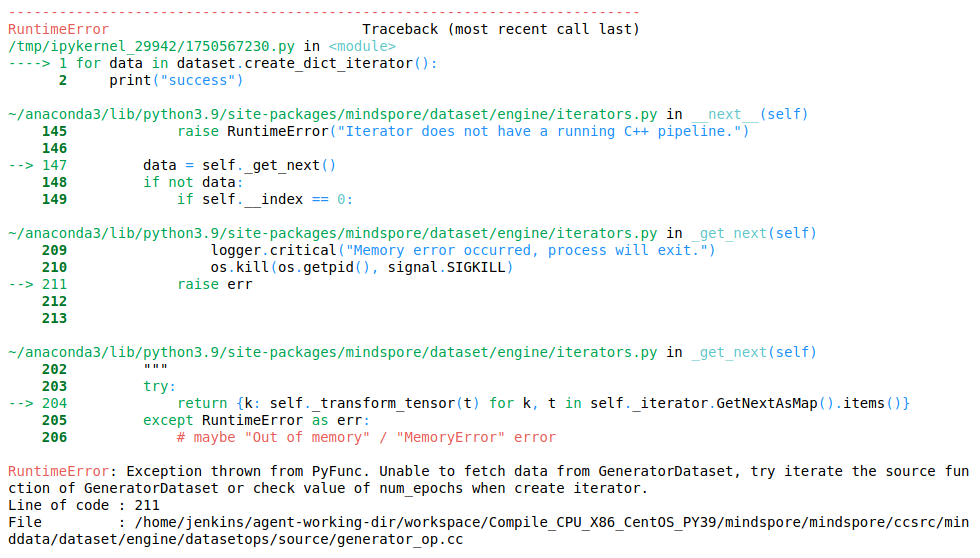
The error message here is as follows:
Traceback (most recent call last):
File "ApplyPowerSign.py", line 27, in <module>
output = net(grad)
File "/root/archiconda3/envs/lilinjie_high/lib/python3.7/site-packages/mindspore/nn/cell.py", line 573, in __call__
out = self.compile_and_run(*args)
File "/root/archiconda3/envs/lilinjie_high/lib/python3.7/site-packages/mindspore/nn/cell.py", line 956, in compile_and_run
self.compile(*inputs)
File "/root/archiconda3/envs/lilinjie_high/lib/python3.7/site-packages/mindspore/nn/cell.py", line 929, in compile
_cell_graph_executor.compile(self, *inputs, phase=self.phase, auto_parallel_mode=self._auto_parallel_mode)
File "/root/archiconda3/envs/lilinjie_high/lib/python3.7/site-packages/mindspore/common/api.py", line 1063, in compile
result = self._graph_executor.compile(obj, args_list, phase, self._use_vm_mode())
RuntimeError: Data type conversion of 'Parameter' is not supported, so data type float16 cannot be converted to data type float32 automatically.
For more details, please refer at https://www.mindspore.cn/docs/zh-CN/master/note/operator_list_implicit.html.
Cause Analysis
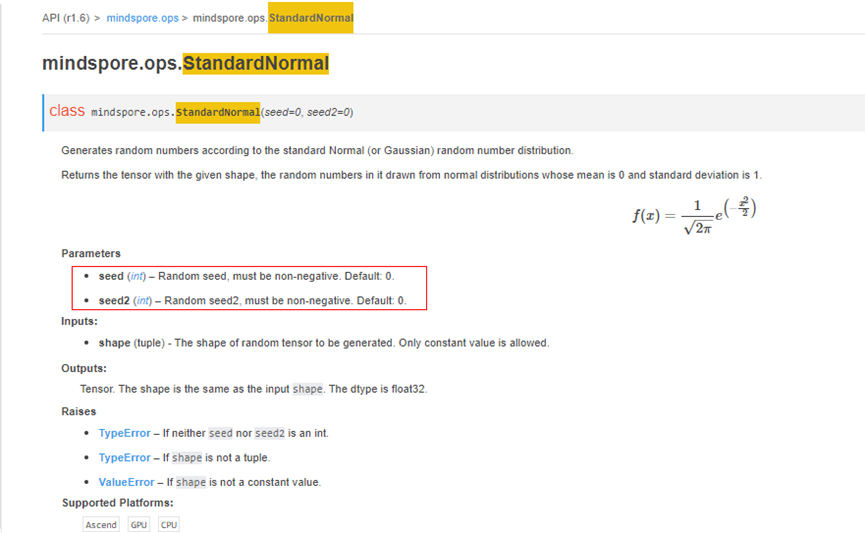
Let’s look at the error message. In AttributeError, we write RuntimeError: Data type conversion of ‘Parameter’ is not supported, so data type float16 cannot be converted to data type float32 automatically, which means that the Parameter data type cannot be converted. This point about the use of Parameter is explained on the official website API:
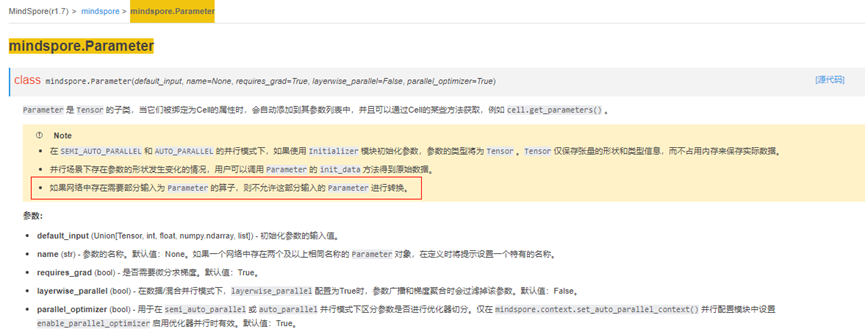
Therefore, if Parameter is input as part of the network, its data type needs to be determined in the composition stage, and it is not supported to convert its data type in the middle.
2 Solutions
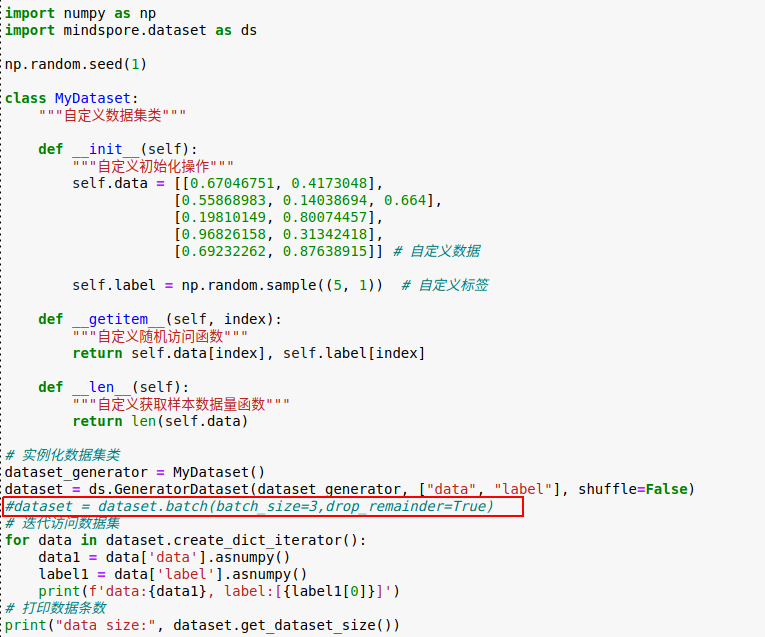
For the reasons known above, it is easy to make the following modifications:
01 class Net(nn.Cell):
02 def __init__(self):
03 super(Net, self).__init__()
04 self.apply_power_sign = ops.ApplyPowerSign()
05 self.var = Parameter(Tensor(np.array([[0.6, 0.4],
06 [0.1, 0.5]]).astype(np.float32)), name="var")
07 self.m = Parameter(Tensor(np.array([[0.6, 0.5],
08 [0.2, 0.6]]).astype(np.float32)), name="m")
09 self.lr = 0.001
10 self.logbase = np.e
11 self.sign_decay = 0.99
12 self.beta = 0.9
13 def construct(self, grad):
14 out = self.apply_power_sign(self.var, self.m, self.lr, self.logbase,
15 self.sign_decay, self.beta, grad)
16 return out
17
18 net = Net()
19 grad = Tensor(np.array([[0.3, 0.7], [0.1, 0.8]]).astype(np.float32))
20 output = net(grad)
21 print(output)
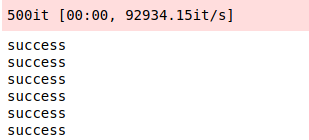
At this point, the execution is successful, and the output is as follows:
output: (Tensor(shape=[2, 2], dtype=Float32, value=
[[ 5.95575690e-01, 3.89676481e-01],
[ 9.85252112e-02, 4.88201708e-01]]), Tensor(shape=[2, 2], dtype=Float32,
value=[[ 5.70000052e-01, 5.19999981e-01],
[ 1.89999998e-01, 6.20000064e-01]]))
3 Summary
Steps to locate the error report:
1. Find the line of user code that reported the error: 20 output = net(grad) ;
2. According to the keywords in the log error message, narrow down the scope of the analysis problem. Data type conversion of ‘Parameter’ is not supported, so data type float16 cannot be converted to data type float32 automatically. ;
3. It is necessary to focus on the correctness of variable definition and initialization.