Hbase error:
hbase(main):001:0> status
ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is the initializing
the at org.. Apache hadoop, hbase. Master. HMaster. CheckInitialized (HMaster. Java: 2293)
the at org.apache.hadoop.hbase.master.MasterRpcServices.getClusterStatus(MasterRpcServices.java:777)
…..
Solution:
log in zookeeper client and delete /hbase
#./bin/zkCli. Sh
[zk: localhost:2181(CONNECTED) 1] RMR /hbase
Then restart the HBase service
Tag Archives: hbase
Hbase Native memory allocation (mmap) failed to map xxx bytes for committing reserved memory
New start test environment Hbase error, error log as follows
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 31715688448 bytes for committing reserved memory.
# An error report file with more information is saved as:
# /opt/cm-5.13.0/run/cloudera-scm-agent/process/521-hbase-REGIONSERVER/hs_err_pid132687.logView the Hbase RegionServer configuration

See 31G allocated and check server memory usage
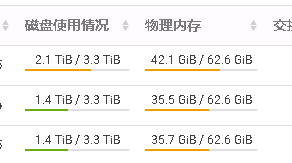
Spotting a huge shortage of memory that could be allocated to RegionServer and causing problems, RegionServer freed it or resized its configuration, restarted the service and got it back on.
Java query HBase outoforderscannernextexception
Java query hbase timeout, and sometimes an error OutOfOrderScannerNextException
there is only one message like this, no other error message
Caused by: org.apache.hadoop.hbase.exceptions.OutOfOrderScannerNextException: org.apache.hadoop.hbase.exceptions.OutOfOrderScannerNextException: Expected nextCallSeq: 1 But the nextCallSeq got from client: 0; request=scanner_id: 178 number_of_rows: 100 close_scanner: false next_call_seq: 0then I trim the rowkey, make it the same length, and there it is…
HBase import CSV file
- upload the file to Linux and then pass it to HDFS
hadoop fs -put 1.csv /
- enter the shell command of hbase and create hbase table
create 'amazon_key_word','MM'
- import data by command
format: hbase [class] [separator] [row key, column family] [table] [import file]
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," -Dimporttsv.columns=HBASE_ROW_KEY,MM:dept,MM:search_word,MM:Search_ranking,MM:asin,MM:name,MM:click_v,MM:conversion,MM:asin2,MM:name2,MM:click_v2,MM:conversion2,MM:asin3,MM:name3,MM:click_v3,MM:conversion3 amazon_key_word /1.csv
Note that the first column data is hbase rowkey