Problem description
Problems encountered during distributed training
RuntimeError: NCCL error in: ../torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp:47, unhandled cuda error, NCCL version 21.0.3
ncclUnhandledCudaError: Call to CUDA function failed.
The specific errors are as follows:
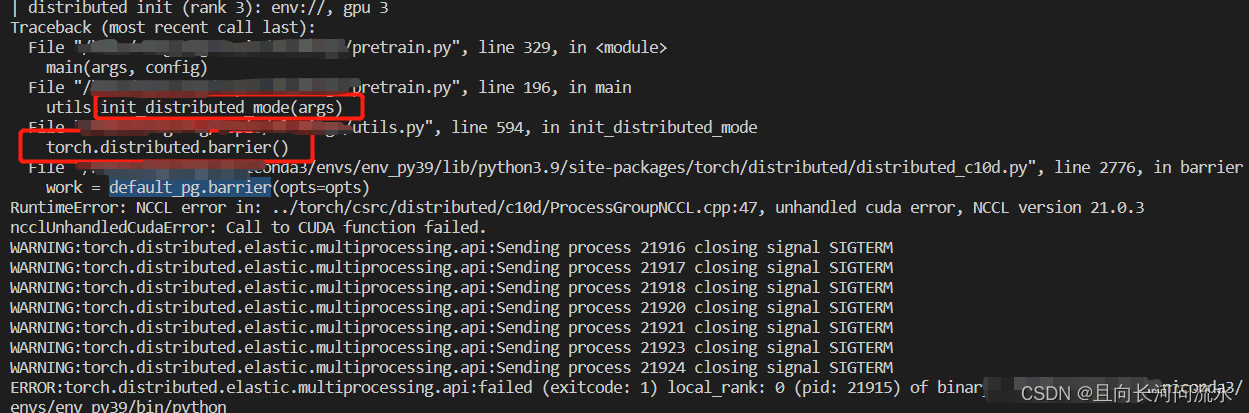
Problem-solving
According to the analysis of error reporting information, an error is reported during initialization during distributed training, not during training. Therefore, the problem is located on the initialization of distributed training.
Enter the following command to check the card of the current server
nvidia-smi -L
The first card found is 3070
GPU 0: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 1: NVIDIA GeForce RTX 3070 (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 2: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 3: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 4: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 5: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 6: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
GPU 7: NVIDIA GeForce RTX 2080 Ti (UUID: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx)
Therefore, here I directly try to use 2-7 cards for training.
Correct solution!