1. Problem description
Use waterdrop to import data into the Clickhouse, and then the log reports an error:
Caused by: ru.yandex.clickhouse.except.ClickHouseException: ClickHouse exception, code: 252, host: 10.252.32.26, port: 8123; Code: 252, e.displayText() = DB::Exception: Too many partitions for single INSERT block (more than 100). The limit is controlled by 'max_partitions_per_insert_block' setting. Large number of partitions is a common misconception. It will lead to severe negative performance impact, including slow server startup, slow INSERT queries and slow SELECT queries. Recommended total number of partitions for a table is under 1000..10000. Please note, that partitioning is not intended to speed up SELECT queries (ORDER BY key is sufficient to make range queries fast). Partitions are intended for data manipulation (DROP PARTITION, etc). (version 20.3.10.75 (official build))
at ru.yandex.clickhouse.except.ClickHouseExceptionSpecifier.specify(ClickHouseExceptionSpecifier.java:58)
at ru.yandex.clickhouse.except.ClickHouseExceptionSpecifier.specify(ClickHouseExceptionSpecifier.java:28)
at ru.yandex.clickhouse.ClickHouseStatementImpl.checkForErrorAndThrow(ClickHouseStatementImpl.java:680)
at ru.yandex.clickhouse.ClickHouseStatementImpl.sendStream(ClickHouseStatementImpl.java:656)
at ru.yandex.clickhouse.ClickHouseStatementImpl.sendStream(ClickHouseStatementImpl.java:639)
at ru.yandex.clickhouse.ClickHousePreparedStatementImpl.executeBatch(ClickHousePreparedStatementImpl.java:382)
at io.github.interestinglab.waterdrop.output.Clickhouse$$anonfun$process$1.apply(Clickhouse.scala:133)
at io.github.interestinglab.waterdrop.output.Clickhouse$$anonfun$process$1.apply(Clickhouse.scala:115)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$29.apply(RDD.scala:926)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$29.apply(RDD.scala:926)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2069)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2069)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:338)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.Throwable: Code: 252, e.displayText() = DB::Exception: Too many partitions for single INSERT block (more than 100). The limit is controlled by 'max_partitions_per_insert_block' setting. Large number of partitions is a common misconception. It will lead to severe negative performance impact, including slow server startup, slow INSERT queries and slow SELECT queries. Recommended total number of partitions for a table is under 1000..10000. Please note, that partitioning is not intended to speed up SELECT queries (ORDER BY key is sufficient to make range queries fast). Partitions are intended for data manipulation (DROP PARTITION, etc). (version 20.3.10.75 (official build))
2. Cause of problem
Clickhouse limit Max_partitions_per_insert_Block, that is, the partition of each inserted block. The solution is to modify this parameter and restart Clickhouse.
3. Solution
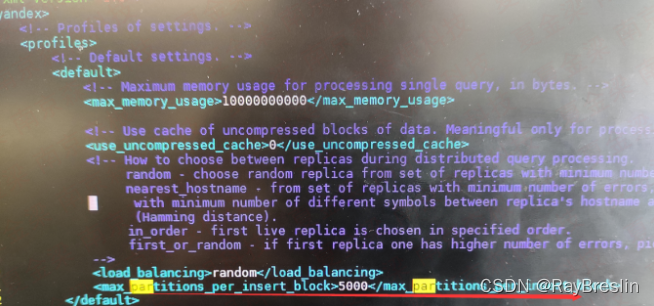
1. Modify users XML configuration
vi users.xml
add to
<max_partitions_per_insert_block>5000</max_partitions_per_insert_block>
2. Restart
sudo systemctl restart clickhouse-server