1 Error description
1.1 System Environment
ardware Environment(Ascend/GPU/CPU): CPU
Software Environment:
– MindSpore version (source or binary): 1.6.0
– Python version (eg, Python 3.7.5): 3.7.6
– OS platform and distribution (eg, Linux Ubuntu 16.04): Ubuntu 4.15.0-74-generic
– GCC/Compiler version (if compiled from source):
1.2 Basic information
1.2.1 Script
This case uses a custom iterable data set for training. During the training process, the first epoch data is iterated normally, and the second epoch will report an error. The custom data code is as follows:
import numpy as np
import mindspore.dataset as ds
from tqdm import tqdm
class IterDatasetGenerator:
def __init__(self, datax, datay, classes_per_it, num_samples, iterations):
self.__iterations = iterations
self.__data = datax
self.__labels = datay
self.__iter = 0
self.classes_per_it = classes_per_it
self.sample_per_class = num_samples
self.classes, self.counts = np.unique(self.__labels, return_counts=True)
self.idxs = range(len(self.__labels))
self.indexes = np.empty((len(self.classes), max(self.counts)), dtype=int) * np.nan
self.numel_per_class = np.zeros_like(self.classes)
for idx, label in tqdm(enumerate(self.__labels)):
label_idx = np.argwhere(self.classes == label).item()
self.indexes[label_idx, np.where(np.isnan(self.indexes[label_idx]))[0][0]] = idx
self.numel_per_class[label_idx] = int(self.numel_per_class[label_idx]) + 1
def __next__(self):
spc = self.sample_per_class
cpi = self.classes_per_it
if self.__iter >= self.__iterations:
raise StopIteration
else:
batch_size = spc * cpi
batch = np.random.randint(low=batch_size, high=10 * batch_size, size=(batch_size), dtype=np.int64)
c_idxs = np.random.permutation(len(self.classes))[:cpi]
for i, c in enumerate(self.classes[c_idxs]):
index = i*spc
ci = [c_i for c_i in range(len(self.classes)) if self.classes[c_i] == c][0]
label_idx = list(range(len(self.classes)))[ci]
sample_idxs = np.random.permutation(int(self.numel_per_class[label_idx]))[:spc]
ind = 0
for i in sample_idxs:
batch[index+ind] = self.indexes[label_idx]
ind = ind + 1
batch = batch[np.random.permutation(len(batch))]
data_x = []
data_y = []
for b in batch:
data_x.append(self.__data<b>)
data_y.append(self.__labels<b>)
self.__iter += 1
item = (data_x, data_y)
return item
def __iter__(self):
return self
def __len__(self):
return self.__iterations
np.random.seed(58)
data1 = np.random.sample((500,2))
data2 = np.random.sample((500,1))
dataset_generator = IterDatasetGenerator(data1,data2,5,10,10)
dataset = ds.GeneratorDataset(dataset_generator,["data","label"],shuffle=False)
epochs=3
for epoch in range(epochs):
for data in dataset.create_dict_iterator():
print("success")
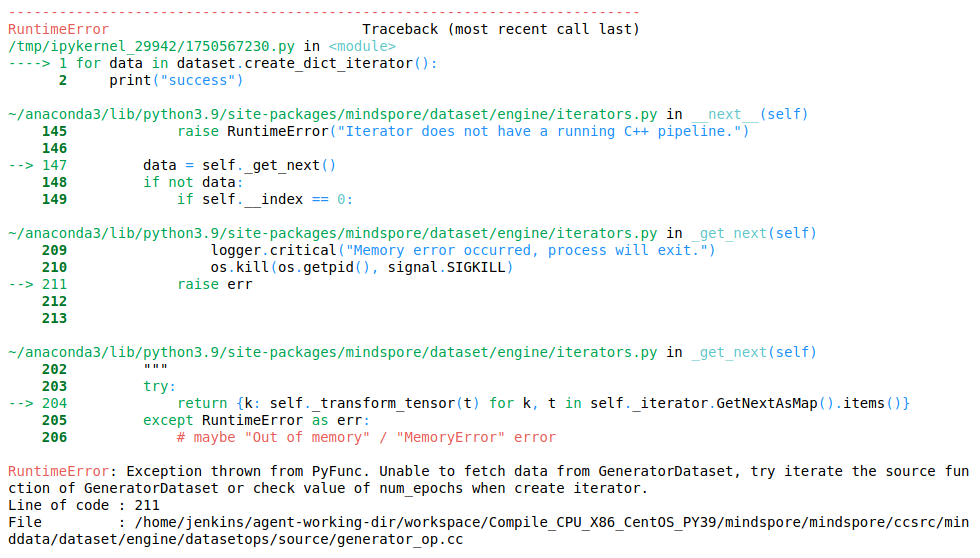
1.2.2 Error reporting
Error message: RuntimeError: Exception thrown from PyFunc. Unable to fetch data from GeneratorDataset, try iterate the source function of GeneratorDataset or check value of num_epochs when create iterator.
2 Reason analysis
In the process of each data iteration, self.__iter will accumulate. When the second epoch is prefetched, self.__iter has accumulated to the value of the set iterations, resulting in self.__iter >= self.__iterations, and the loop ends.
3 Solutions
Add the clearing operation to def iter(self): and set self.__iter = 0.

The execution is successful at this time, and the output is as follows: