HTTPError: HTTP error 418:
>
>
>
>
>
>
>
> 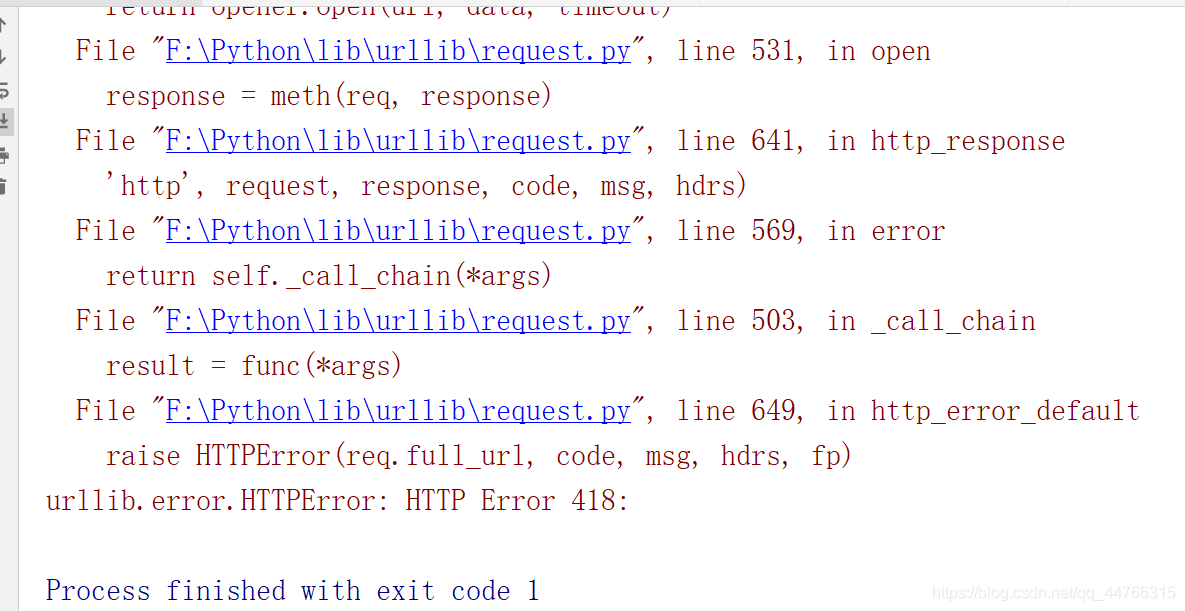 ‘s disguise code is as follows:
‘s disguise code is as follows:
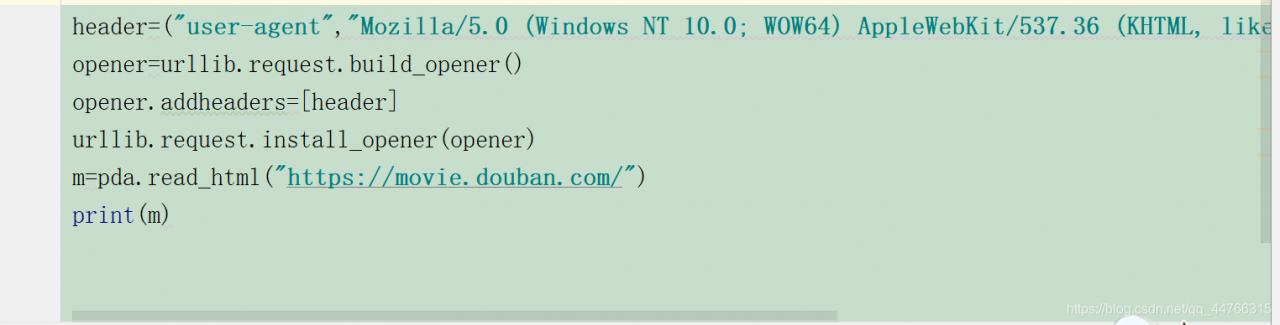 ‘s many partners go to user-agent every time they do a crawler project. In fact, it is not necessary, but it is ok to use the previous one. Try to change the last number when tested, and most of the time it works.
‘s many partners go to user-agent every time they do a crawler project. In fact, it is not necessary, but it is ok to use the previous one. Try to change the last number when tested, and most of the time it works.
and this is what I came up with:
 , I hope it’s helpful to you.
, I hope it’s helpful to you.