reference [1], but the official document is a little brief, or need to digest the line
(1) CD/home/appleyuchi/bigdat
(2) the git clone https://gitee.com/mirrors/apache-flink.git
opens the following path :
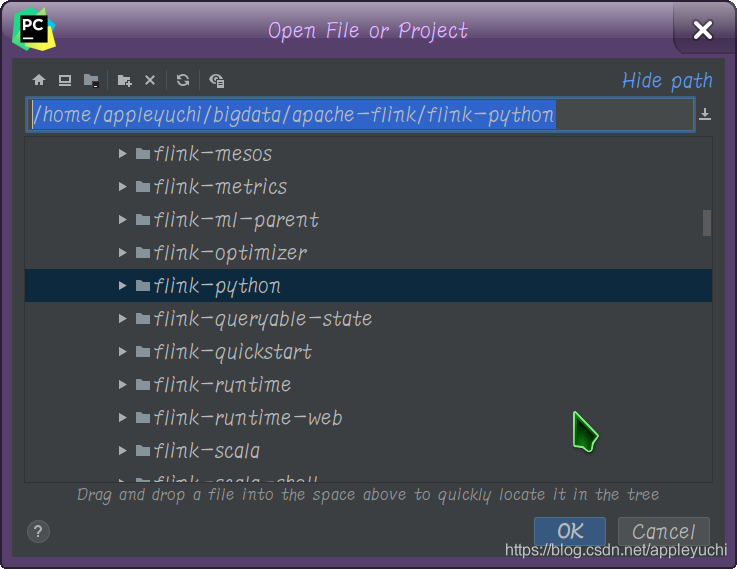
4. PIP install flake8
(5) Settings – & gt; External Tools
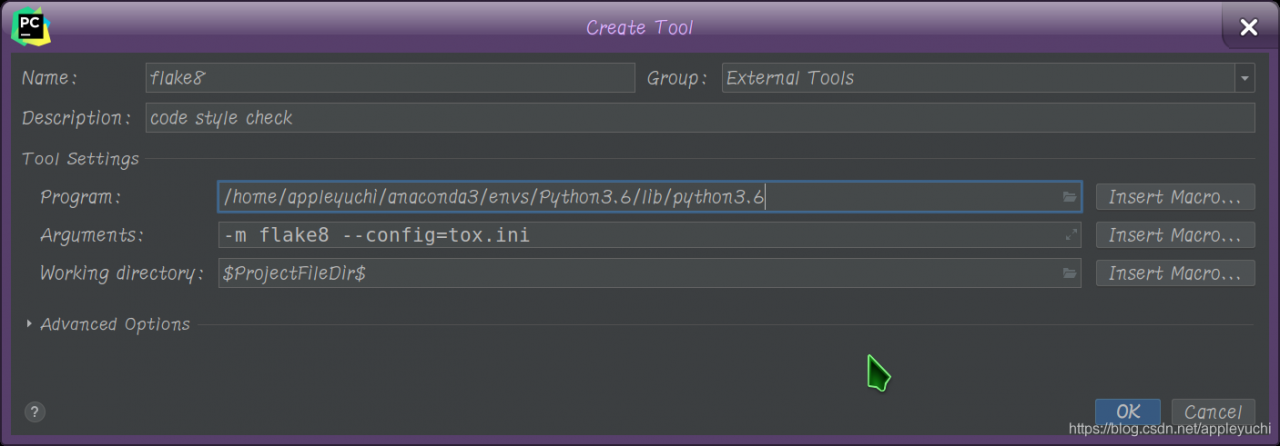
—————————————————————————————————————-
what is this?

—————————————————————————————————————-
, right click Mark Directory as-> Sources Root
—————————————————————————————————————-
python-m PIP install apache-flink(also search for this in pycharm)
—————————————————————————————————————-
run code :
from flink.plan.Environment import get_environment
from flink.functions.GroupReduceFunction import GroupReduceFunction
class Adder(GroupReduceFunction):
def reduce(self, iterator, collector):
count, word = iterator.next()
count += sum([x[0] for x in iterator])
collector.collect((count, word))
# 1. 获取一个运行环境
env = get_environment()
print("------------1--------")
# 2. 加载/创建初始数据
data = env.from_elements("Who's there?",
"I think I hear them. Stand, ho! Who's there?")
print("------------2--------")
# 3. 指定对这些数据的操作
# data.flat_map(lambda x, c: [(1, word) for word in x.lower().split()]) \
# .group_by(1) \
# .reduce_group(Adder(), combinable=True) \
# .output()
data.output()
print("------------3--------")
print(data)
# 4. 运行程序
env.execute() # 设置execute(local=True)强制程序在本机运行—————————————————————————————————————-
finally fails because data.output() cannot output any result
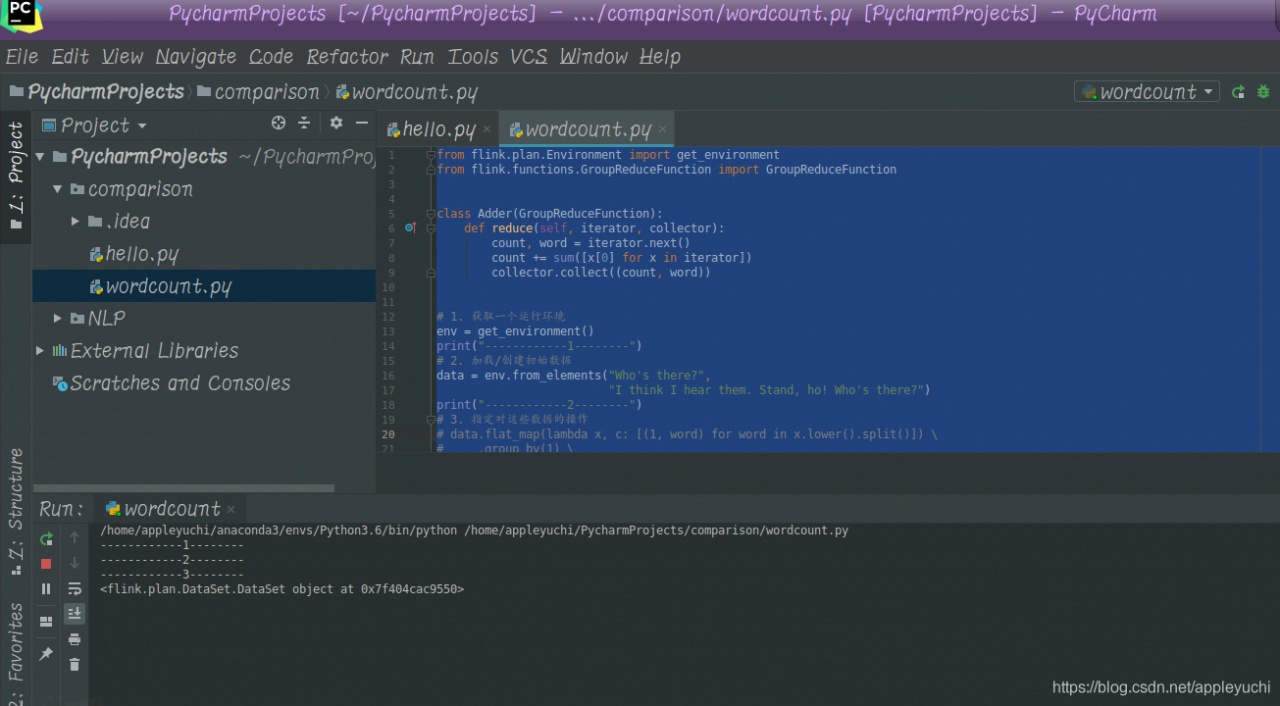
—————————————————————————————————————-
The
command line runs pyflink as
$FLINK_HOME/bin/flink run-py /home/appleyuchi/ desktop/experiment/wordport.py
Reference:
[1]Importing Flink into an IDE
[2]PyCharm builds Spark development environment + the first pyspark program
[3]pycharm not updating with environment variables
Read More:
- Due to multi process — pychar debug breakpoint debugging encounter pychar dataloader will be stuck
- The problem of unable to install win32gui in building Anaconda environment in pychar
- Configure QT designer in pychar
- Solution of modulenotfounderror in running pychar
- Cannot call the same level library solution in pychar
- Using CONDA virtual environment in pychar
- Problem in configuring Maven error: Java_ HOME not found in your environment.
- “Failed to create interpreter” appears when pychar creates a new project
- Solve the problem of red wavy line in pychar when importing module written by oneself
- A series of problems in configuring OpenGL development environment in vs2015
- Configuring common environment variables in Windows
- Configuring NFS server in Linux
- Problems in configuring OpenGL
- Problems encountered in configuring OpenGL development environment in vs2015
- The simplest course of configuring OpenGL in vs2015
- Configuring OpenGL in VS
- Error in initializing namenode when configuring Hadoop!!!
- The solution of configuring OpenGL in vs2017
- Configuring OpenGL in Visual Studio
- Configuring OpenGL in Code:: blocks