When reading and processing the data in the CSV file with panda in Python, you may encounter such an error:
TypeError: invalid type comparisonInvalid type comparison
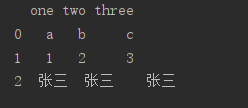
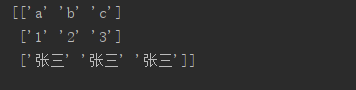
At this time, you can print the data in your data frame
1. There may be no data in some items, which will be displayed as Nan when printing. Nan can’t be compared with any data, and it’s not equal to any value, including himself (so you can also use a! =A to judge whether a is Nan.
Therefore, in the following data processing, if a comparison operation is performed, an error will be reported:
TypeError: invalid type comparisonMethod, add parameters when reading the CSV
keep_default_na=FalseIn this way, entries without data will be recognized as null characters instead of Nan
2. Maybe the data types of different columns in your dataframe are different. Some of them are recognized as STR and some as int. although they all look like numbers, they will also report errors when compared later
At this time, you can add a parameter
converters={'from':str,'to':str} # Convert both the from and to columns to strThe explanation of converters is as follows:
converters: dict, default None
Dict of functions for converting values in certain columns. Keys can either
be integers or column labels
The same type can be compared together
 Done!
Done!