Java web part problem and solution
The
error is based on the number of errors that occur in the writing process. Careful examination, rigorous scholarship!
JSP images cannot display properly?
found problem: path problem, path is incomplete.
shows a serious error, how many lines:
is generally in the select statement related character input error, carefully check.
request-getparameter (” ID “) where the parameter comes from
where the JSP page jumps over, the ID is the ID from the jump join of that page.
solve the import project, add Tomcat and JDK after the project appears Red Cross : modify the JDK version of the project and eclipse version of the JDK version. J compiler and project facts in
project (JAVA, WWM, and runtimes modified Tomcat version on the right).
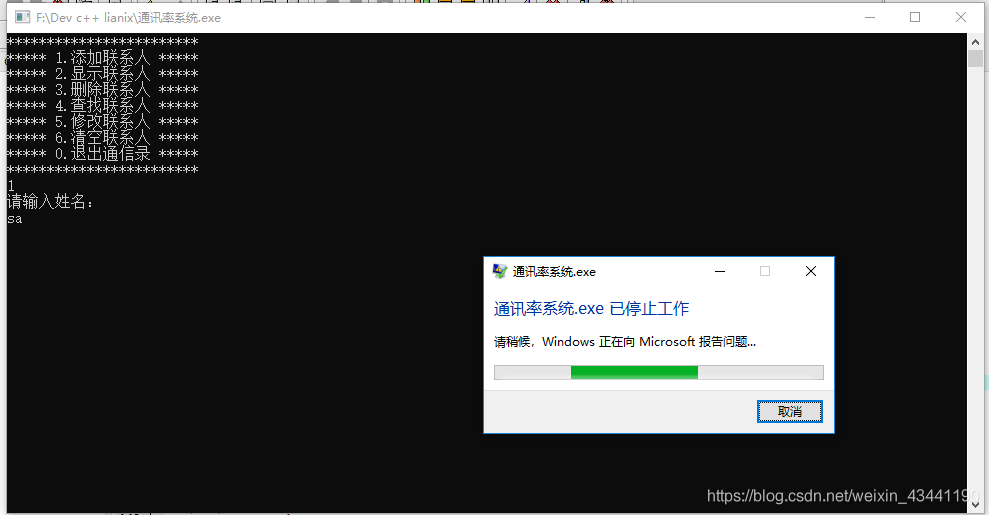
Java web project, after starting Tomcat, display:
information.
describes a source server that was unable to find a representation of the target resource or was unwilling to expose an existing representation of the resource.
tries to find that since there was a related shop project originally, although the name was changed later, the new import project named shop was affected. When adding to Tomcat, the Path name was shop3 in web modules, and when accessing with the browser, it should be noted that the Path name was shop3 instead of shop.
2020.10.18
eclipse json file error, because eclipse thinks that json file does not need annotation, so compile error.
address: Prefrences, validation, json validator, cancel manual, build. Again, right click and validation on the json file that is in error.
valicat trial expires, modify system time before the probation period:
address: https://jingyan.baidu.com/article/adc815133376b6b622bf7354.html
Publishing to Tomcat v9.0 Server at localhost…
Publishing the configuration…
Error file to E:/download/apache-tomcat-9.0.38-windows-x64/apache-tomcat-9.0.38/backup\ sys_loginmapper.xml :
E:\ Download \ Apache-Tomcat-9.0.38-Windows-x64 \ Apache-Tomcat-9.0.38 \conf\ SYs_loginmapper.xml (the system cannot find the specified file)
E:\download\apache-tomcat-9.0.38-windows-x64\apache-tomcat-9.0.38\conf\ sys_loginmapper.xml (the system could not find the specified file)
OK
resolve in eclipse-> Project Explorer-> Servers-> Under Tomcat, sys_loginmapper. XML file was found and copied to:
Error file to E:/download/apache-tomcat-9.0.38-windows-x64/apache-tomcat-9.0.38/backup to solve the problem.
start Tomcat anomalies: Java. Lang. NoClassDefFoundError: javax.mail/XML/bind/is thrown.
j is the JDK version problem, I used jdk11, changed to jdk8 can be used normally, the reason for the error should be the introduction of JDK 9 and the version of Java modularity mechanism.
start Tomcat error:
Could not publish server configuration for Tomcat v9.0 server at localhost. Multiple Contexts have a path of “/ MRBBS”. Project Explorer-> Servers-> Server.xml file was found under Tomcat, and found at the bottom:
< The Context the docBase = “MRBBS” path = “/ MRBBS” reloadable = “true” source = “org. Eclipse. JST. Jee. Server: MRBBS”/& gt;
delete duplicate content, you can.
start Tomcat outbreak exception:
Could not get JDBC Connection;
Request processing failed; Nested exception is org. Mybatis. Spring. MyBatisSystemException: nested exception is
org. Apache. Ibatis. Exceptions. PersistenceException:
why : When the Spring container manages the PropertySource, not only does it read its own properties file, but it also reads both JVM system properties and
JVM system env properties into the container.
so at this point the username read in spring-transaction.xml is not the username above JDBC.
solution , change the username on jdbc.properties to user (as long as it is not called username), and change the values in the spring-transaction.xml corresponding to
to correspond:
When Tomcat is started, an exception occurs:
serverTimezone problem.
JDBC in the configuration file. The properties of add after url:
url = JDBC: mysql:// 127.0.0.1:3306/MRBBS
url = JDBC: mysql:// 127.0.0.1:3306/MRBBS?ServerTimezone =Asia/Shanghai
change to east area 8 time.

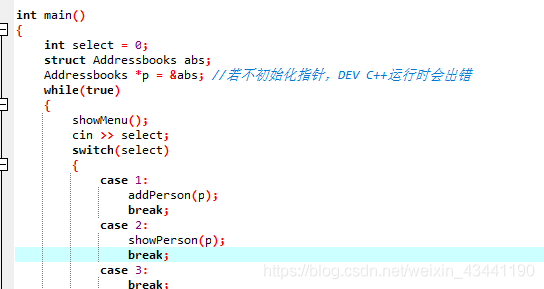
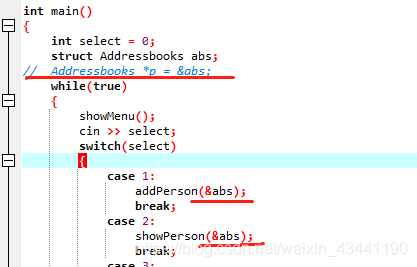 will not fail at compile time, but will fail at run time if no pointer is initialized and the address is passed directly.
will not fail at compile time, but will fail at run time if no pointer is initialized and the address is passed directly.