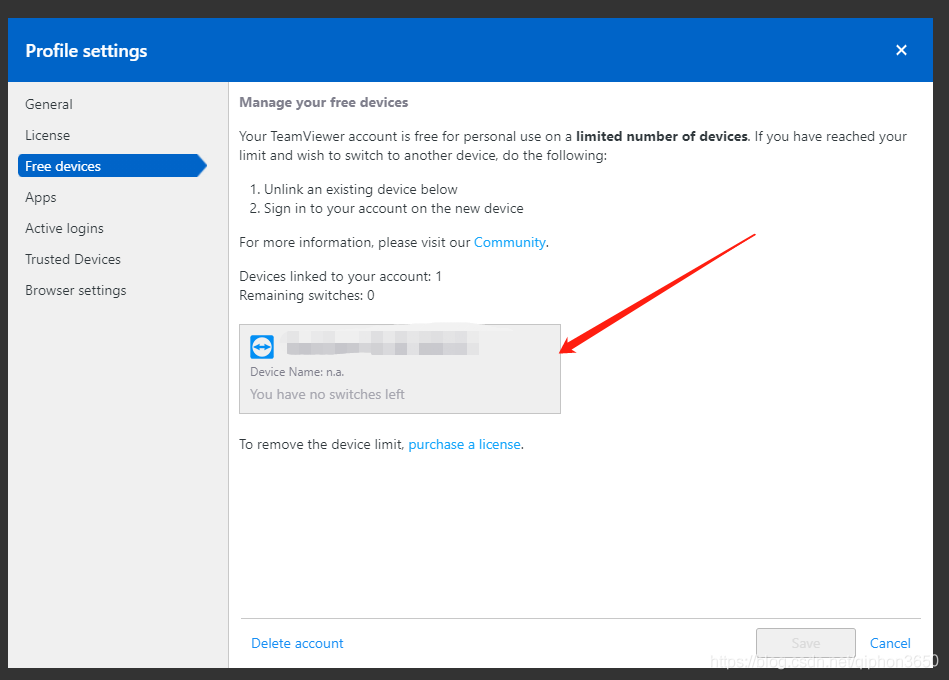
TeamView removes the device
User management – right avatar click edit profile – free device
Category Archives: How to Fix
Mount windows NTFS partition under Linux
Mounting the Windows NTFS partition under Linux
How it works: Use the mount command to mount the partition under Windows into a directory under Linux.
1.uname -r View the current Linux kernel version.
2. Go to
http://www.linux-ntfs.org/ Download the same NTFS patch as the kernel version.
3. Install patch: RPM – the ivh kernel – the module – NTFS – 2. 7.0.x.x – x – 2.1.20-0. Rr. 4.10 i686. RPM
4. Use fdisk-l to view the partition information of the hard disk.
5.
5.
5.
5.
5.
5.
: mkdir/MNT /c corresponds to the C disk
mkdir/MNT /d corresponds to D disk
mkdir/MNT /e corresponds to e disk
6.mount -t NTFS /dev/xxx/MNT /x
6.mount -t NTFS /dev/xxx/MNT /x
6.mount -t NTFS /dev/xxx/MNT /x
: mount /dev/hda1/MNT /c
the mount -t NTFS/dev/hda5/MNT/d
the mount -t NTFS/dev/hda6/MNT/e
How to use dangerously set inner HTML in react
Let’s put the directory title here
Write your own label value transformation through the transformation of the data returned by the interface
The transformation of data returned through the interface
<div dangerouslySetInnerHTML = {{ __html: checkMessages.details }} />
Write your own label value conversion
<div dangerouslySetInnerHTML={{ __html: '<div>hello World</div>' }} />
Solution to the problem that keil can’t set breakpoint
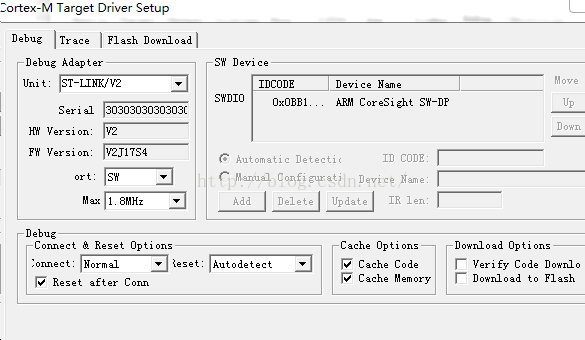
Because Cache Options is not checked
Download Options is checked
The setting shown above is the correct choice
Solution to the problem that SQL database query result field contains new line character, which leads to copy to excel dislocation
Problem description:
in the process of work, sometimes encountered such a problem, write a SQL query to query data in the database, see the number of rows (such as 1000 rows), but make a copy of the query results to Excel, but happened mismatch, and lead to Excel in the number of lines is more than 1000 lines, caused the number of rows of data inconsistency.
field value contains char(10) newline character, copy the field value to Excel.
Source:
some corresponding cell contains a newline, lead to dislocation happened in copy to Excel.
Option 1 (Recommended) : Enclose the field values in question in double quotation marks so that the newline characters in the field values are restricted to the correct Excel cell.
scenario 2: use the script to remove the corresponding field value newline character.
create table #t
(
Name nvarchar(50),
Remark nvarchar(50)
)
insert into #t
lues (‘ A1 ‘+ char(10) +’ B1 ‘, ‘row 1’), (‘ A2B2 ‘, ‘row 2’)
select Name, Remark
om #t
— Solution 1: You can put double quotation marks directly in the field, and copy it to Excel without misplacing or showing redundant double quotation marks.
select ‘”‘ + Name + ‘”‘ as Name, Remark
om #t
select replace(replace(Name, char(13), ‘ ‘), char(10), ‘ ‘) as Name, Remark
om #t
drop table #t
Runtimeerror using Python training model: CUDA out of memory error resolution
RuntimeError: CUDA out of memory occurs using the PyTorch training model
Training: Due to the limited GPU video memory resources, the batchsize of training input should not be too large, which will lead to Out of Memory errors.
Solution: Reduce the batchSize to even 1
Use with torch.no_grad():fore testing the code
ValueError: not enough values to unpack (expected 6, got 1)
This is a problem that comes up all the time when dividing data sets by emoji labels.
The code is:
The code is:
angle, idx, _, gender, expression, gaze = image_name.split('_')The format of image_name is: dataset000_01_caucasian_female_angry_left.jpg
There have been some errors running on the server
ValueError: not enough values to unpack (expected 6, got 1)Solution:
Later, it was found that after decompressing the data set in the unified format, the zip file was not deleted after the execution of the unzip command, so it was not easy to find. The main reason for this problem is that the file name of the compressed price can not be divided into 6 parts, so the error has been reported.
Delete the ZIP file.
ValueError: not enough values to unpack (expected 2, got 0)
ValueError: not enough values to unpack (Expected 2, got 0) sometimes appears when reading TXT files. The reason I found myself is that there are several blank lines at the end of the TXT file. Delete the last blank line and make sure that the last line is the text you want to read. The TXT file looks like nothing if you press Enter at the end, but those empty lines actually have one character, the newline \n, so there can be no empty lines.
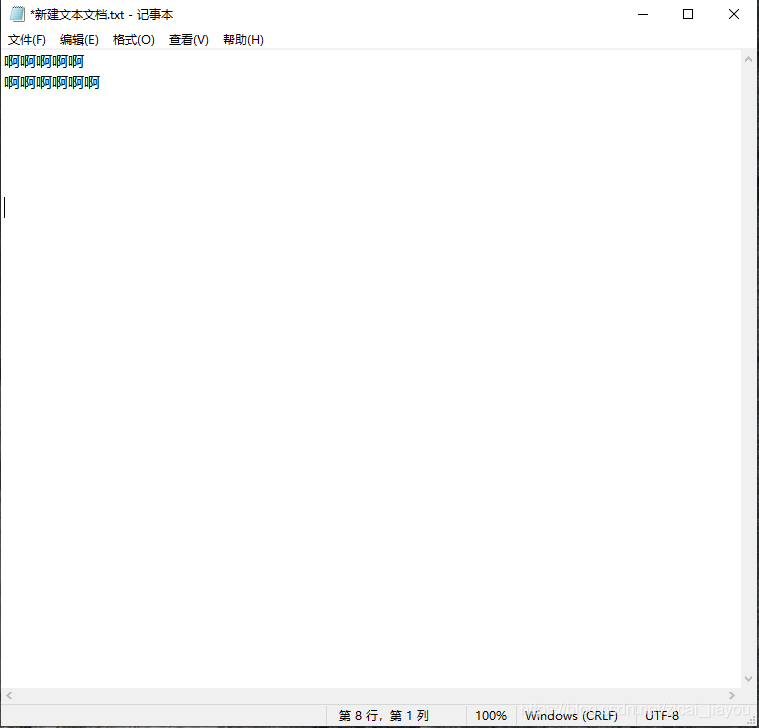
Just like that the blank line between the cursor and the text actually has a newline character on each line.
Click Backspace to go back to your last line of text. Press the direction key of the keyboard cursor can not get down.
Just like that the blank line between the cursor and the text actually has a newline character on each line.
Click Backspace to go back to your last line of text. Press the direction key of the keyboard cursor can not get down.
Python3-ValueError:not enough values to unpack (expected 2, got 0)
Python3-valueError :not enough values to unpack (expected 2, got 0)
Specific errors are as follows:
Specific errors are as follows:
Traceback (most recent call last):
File "/Users/zhangsf/code/python/my-project/Subsidy.py", line 83, in <module>
xy1.boxplot(column='ranking', by='subsidy')
File "/Users/zhangsf/anaconda3/lib/python3.7/site-packages/pandas/plotting/_core.py", line 2254, in boxplot_frame
return_type=return_type, **kwds)
File "/Users/zhangsf/anaconda3/lib/python3.7/site-packages/pandas/plotting/_core.py", line 2223, in boxplot
return_type=return_type)
File "/Users/zhangsf/anaconda3/lib/python3.7/site-packages/pandas/plotting/_core.py", line 2682, in _grouped_plot_by_column
keys, values = zip(*gp_col)
ValueError: not enough values to unpack (expected 2, got 0)
It means that python expected there to be two return values from zip(), but there were none.
Error: This means that Python expects zip () to return two values, but neither
The error statement is:
xy1.boxplot(column='ranking', by='subsidy')The reason is that there is a problem with the imported data, which causes the ranking of the column to be NaN and no return value
Just re-introduce the correct data
Error: improvement of not enough values to unpack (expected 2, got 1)
Not enough values to unpack (expected 2, got 1
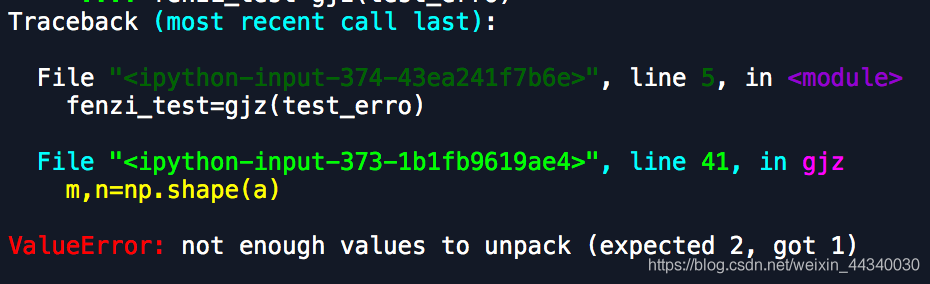

where the code was originally of type array

so fenzi_test is substituted here as an array
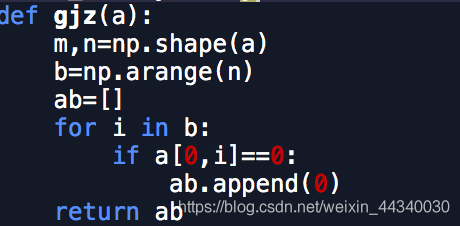
so m,n is wrong
Showed by an example, the
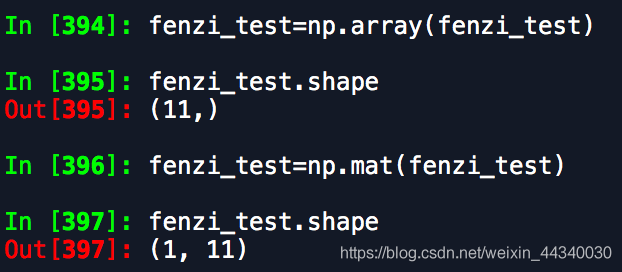
you can see that the shape of array and matrix lose unless the result is not the same m, n = np. Shape (data)
so, change the type

Taberror: inconsistent use of tabs and spaces in indentation
Python has an error: TabError: inconsistent use of tabs and Spaces in indentation
If you use a TAB with four Spaces, you can use a TAB with four Spaces.
Solution: Check the code and either use all tabs, all 4 Spaces, or correct with the IDE editor.
Running Python 3.7 web.py Runtimeerror: generator raised stopiteration exception occurred during test
When I first started learning Python, I found an exception when I ran the web.py home page test code.
The code is as follows:
The code is as follows:
import web
urls = (
'/(.*)', 'hello'
)
app = web.application(urls, globals())
class hello:
def GET(self, name):
if not name:
name = 'World'
return 'Hello, ' + name + '!'
if __name__ == "__main__":
app.run()The exceptions are as follows:
Traceback (most recent call last):
File "C:\Users\HHHHH\AppData\Local\Programs\Python\Python37-32\lib\site-packages\web\utils.py", line 526, in take
yield next(seq)
StopIteration
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "D:\workspace\HelloPython\Helloworld.py", line 7, in <module>
app = web.application(urls, globals())
File "C:\Users\HHHHH\AppData\Local\Programs\Python\Python37-32\lib\site-packages\web\application.py", line 62, in __init__
self.init_mapping(mapping)
File "C:\Users\HHHHH\AppData\Local\Programs\Python\Python37-32\lib\site-packages\web\application.py", line 130, in init_mapping
self.mapping = list(utils.group(mapping, 2))
File "C:\Users\HHHHH\AppData\Local\Programs\Python\Python37-32\lib\site-packages\web\utils.py", line 531, in group
x = list(take(seq, size))
RuntimeError: generator raised StopIteration
Follow the exception prompt to find the appropriate code (… Utils.py “, line 531, in group), as follows:
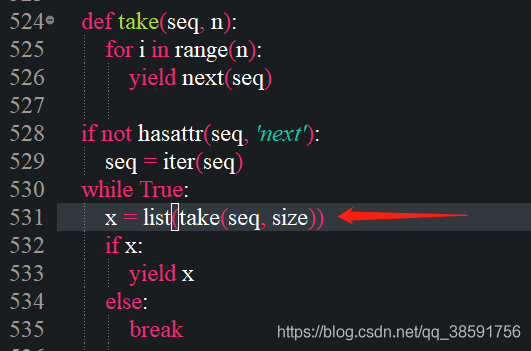
Here, call line 524 take method and modify it as follows according to the information on the official website (note the indentation) :

Restart successfully after modification:
END