preface
Scalar is a tensor of order 0 (a number), which is 1 * 1;
vector is a tensor of order 1, which is 1 * n;
tensor can give the relationship between all coordinates, which is n * n.
So it is usually said that tensor (n * n) is reshaped into vector (1 * n). In fact, there is no big change in the reshaping process.
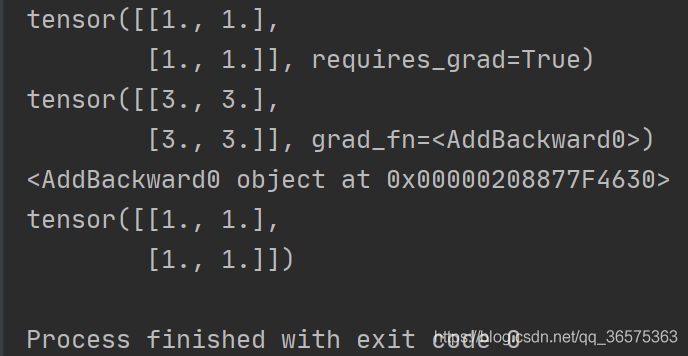
import torch
x=torch.ones(2,2,requires_grad=True)
print(x)
y=x+2
print(y)
#If a tensor is not created by the user, it has the grad_fn attribute. The grad_fn attribute holds a reference to the Function that created the tensor
print(y.grad_fn)
y.backward()
print(x.grad)Running results
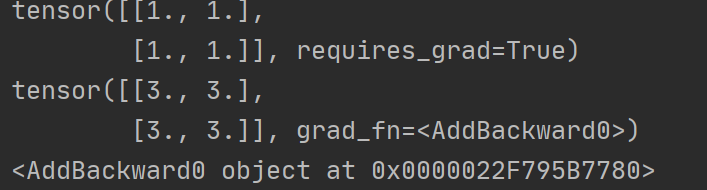
You can see that y is a tensor, which cannot use backward (), and needs to be converted to scalar,
Of course, tensor is also OK, that is, you need to change a code:
z.backward( torch.ones_ like(x))
Our return value is not a scalar, so we need to input a tensor of the same size as the parameter. Here we use ones_ The like function generates a tensor from X. In my opinion, because we want to obtain the derivative of X, the function y must be a value obtained, that is, a scalar. Then we start to find the partial derivatives of X and y, respectively.
After modification
import torch
x=torch.ones(2,2,requires_grad=True)
print(x)
y=x+2
print(y)
#If a tensor is not created by the user, it has the grad_fn attribute. The grad_fn attribute holds a reference to the Function that created the tensor
print(y.grad_fn)
y.backward(torch.ones_like(x))
print(x.grad)Running results