tf.contrib.rnn .BasicLSTMCell
Inherited from: layerrnncell
Aliases:
Class tf.contrib.rnn .BasicLSTMCellClass tf.nn.rnn_ cell.BasicLSTMCellThe basic LSTM cycle network unit is based on http://arxiv.org/abs/1409.2329 . Implementation. Will forget_ Bias (default: 1) is added to the bias of forgetting the door to reduce the previous scale at the beginning of the training. This neuron does not allow cell clipping, projection layer and peep hole connection. It is a basic LSTM neuron. If you want a more advanced model, you can use: tf.nn.rnn_ cell.LSTMCell .
__init__(
num_units,
forget_bias=1.0,
state_is_tuple=True,
activation=None,
reuse=None,
name=None,
dtype=None
)Parameter Description:
num_ units:int Type, the number of neurons in LSTM unit, that is, the number of output neurons_ bias:float Type, offset added to forget gate. When recovering from the checkpoint of cudnnlstm training, it must be manually set to 0.0. state_ is_ Tuple: if true, the accepted and returned status is C_ State and M_ State; if false, they join along the column axis. The latter is about to be abandoned. Activation: activation function of internal state. The default is tanhreuse: Boolean type, which describes whether to reuse variables in an existing scope. If it is not true and the existing scope already has the given variable, an error is thrown. name:String Type, the name of the layer. Layers with the same name will share weights, but to avoid errors, reuse is needed in this case= True.dtype : the default data type of this layer. The default value is none, which means that the type of the first input is used. This parameter is required if build is called before call.
Source code:
class BasicLSTMCell(LayerRNNCell):
"""Basic LSTM recurrent network cell.
The implementation is based on: http://arxiv.org/abs/1409.2329.
We add forget_bias (default: 1) to the biases of the forget gate in order to
reduce the scale of forgetting in the beginning of the training.
It does not allow cell clipping, a projection layer, and does not
use peep-hole connections: it is the basic baseline.
For advanced models, please use the full @{tf.nn.rnn_cell.LSTMCell}
that follows.
"""
def __init__(self, num_units, forget_bias=1.0,
state_is_tuple=True, activation=None, reuse=None, name=None):
"""Initialize the base LSTM cell.
Args:
num_units:int type, the number of neurons in the LSTM cell, i.e. the number of output neurons
forget_bias:float type, bias adds the forget gate. It must be manually set to 0.0 when recovering from the checkpoints (checkpoints) of CudnnLSTM training.
state_is_tuple:If True, the accepted and returned states are 2-tuples of c_state and m_state; if False, they are connected along the column axis. The latter is about to be deprecated.
activation:The activation function for the internal state. Default is tanh
reuse:Boolean type describing whether to reuse the variable in an existing scope. If not True, and the existing scope already has the given variable, an error will be raised.
name:String type, the name of the layer. Layers with the same name will share weights, but to avoid errors, reuse=True is required in this case.
When restoring from CudnnLSTM-trained checkpoints, must use
`CudnnCompatibleLSTMCell` instead.
"""
super(BasicLSTMCell, self).__init__(_reuse=reuse, name=name)
if not state_is_tuple:
logging.warn("%s: Using a concatenated state is slower and will soon be "
"deprecated. Use state_is_tuple=True.", self)
# Inputs must be 2-dimensional.
self.input_spec = base_layer.InputSpec(ndim=2)
self._num_units = num_units
self._forget_bias = forget_bias
self._state_is_tuple = state_is_tuple
self._activation = activation or math_ops.tanh
@property
def state_size(self):
return (LSTMStateTuple(self._num_units, self._num_units)
if self._state_is_tuple else 2 * self._num_units)
@property
def output_size(self):
return self._num_units
def build(self, inputs_shape):
if inputs_shape[1].value is None:
raise ValueError("Expected inputs.shape[-1] to be known, saw shape: %s"
% inputs_shape)
input_depth = inputs_shape[1].value
h_depth = self._num_units
self._kernel = self.add_variable(
_WEIGHTS_VARIABLE_NAME,
shape=[input_depth + h_depth, 4 * self._num_units])
self._bias = self.add_variable(
_BIAS_VARIABLE_NAME,
shape=[4 * self._num_units],
initializer=init_ops.zeros_initializer(dtype=self.dtype))
self.built = True
def call(self, inputs, state):
"""Long short-term memory cell (LSTM).
Args:
inputs: `2-D` tensor with shape `[batch_size, input_size]`.
state: An `LSTMStateTuple` of state tensors, each shaped
`[batch_size, self.state_size]`, if `state_is_tuple` has been set to
`True`. Otherwise, a `Tensor` shaped
`[batch_size, 2 * self.state_size]`.
Returns:
A pair containing the new hidden state, and the new state (either a
`LSTMStateTuple` or a concatenated state, depending on
`state_is_tuple`).
"""
sigmoid = math_ops.sigmoid
one = constant_op.constant(1, dtype=dtypes.int32)
# Parameters of gates are concatenated into one multiply for efficiency.
if self._state_is_tuple:
c, h = state
else:
c, h = array_ops.split(value=state, num_or_size_splits=2, axis=one)
gate_inputs = math_ops.matmul(
array_ops.concat([inputs, h], 1), self._kernel)
gate_inputs = nn_ops.bias_add(gate_inputs, self._bias)
# i = input_gate, j = new_input, f = forget_gate, o = output_gate
i, j, f, o = array_ops.split(
value=gate_inputs, num_or_size_splits=4, axis=one)
forget_bias_tensor = constant_op.constant(self._forget_bias, dtype=f.dtype)
# Note that using `add` and `multiply` instead of `+` and `*` gives a
# performance improvement. So using those at the cost of readability.
add = math_ops.add
multiply = math_ops.multiply
new_c = add(multiply(c, sigmoid(add(f, forget_bias_tensor))),
multiply(sigmoid(i), self._activation(j)))
new_h = multiply(self._activation(new_c), sigmoid(o))
if self._state_is_tuple:
new_state = LSTMStateTuple(new_c, new_h)
else:
new_state = array_ops.concat([new_c, new_h], 1)
return new_h, new_state
The following operations are implemented
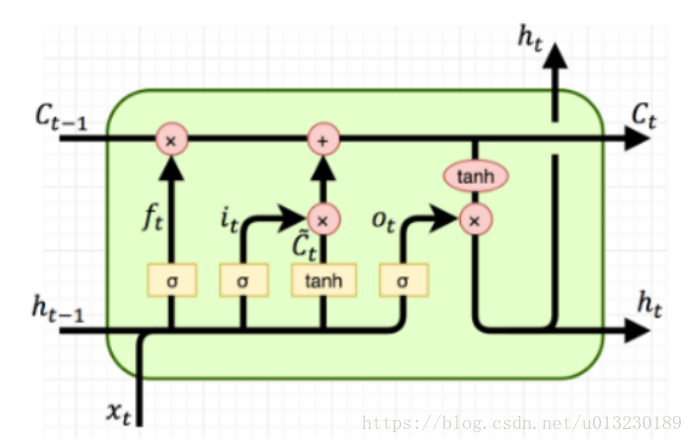
The formula is as follows:
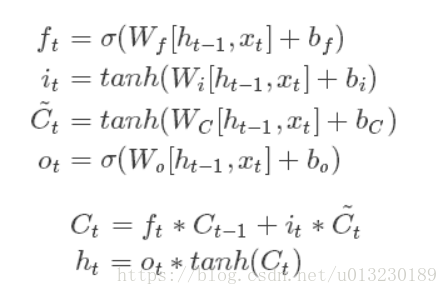
It can be seen from the pictures and formulas that LSTM unit has a single input (CT-1, HT-1, XT) and three outputs (CT, HT, HT).
Constructor init has a state_ is_ Tuple = true. If it is true, the accepted and returned status is C_ State and M_ State; if false, they join along the column axis.
if self._state_is_tuple:
new_state = LSTMStateTuple(new_c, new_h)
else:
new_state = array_ops.concat([new_c, new_h], 1)The hidden state of LSTM unit is (CT, HT) tuple.
Let’s look at the call function. The following line of code is to calculate the forgetting gate, input gate, and output gate (without activating the function).
# i = input_gate, j = new_input, f = forget_gate, o = output_gate
i, j, f, o = array_ops.split(
value=gate_inputs, num_or_size_splits=4, axis=one)The output CT and HT: are calculated
new_c = add(multiply(c, sigmoid(add(f, forget_bias_tensor))),
multiply(sigmoid(i), self._activation(j)))
new_h = multiply(self._activation(new_c), sigmoid(o))Code example:
import tensorflow as tf
output_dim=128
lstm=tf.nn.rnn_cell.BasicLSTMCell(output_dim)
batch_size=10 #Batch size
timesteps=40 #time steps
embedding_dim=300 #word vector dimension
inputs=tf.Variable(tf.random_normal([batch_size,embedding_dim]))
previous_state = (tf.random_normal(shape=(batch_size, output_dim)), tf.random_normal(shape=(batch_size, output_dim)))
output,(new_h, new_state)=lstm(inputs,previous_state)
print(output.shape) #(10, 128)
print(new_h.shape) #(10, 128)
print(new_state.shape) #(10, 128)Read More:
- [Solved] git error – remote: http basic: access denied
- Git Error: remote: HTTP Basic: Access denied [How to Solve]
- NXP mx8 Platform tensorflow-lite build error [How to Solve]
- The upgrade of Ubuntu results in an error in the compilation of Android Jack [Two Method to Solve]
- Solutions to errors in installing xunsearch engine in centos8.0
- Ubuntu20.04 install the ROS noetic version in catkin_Problems in make compilation
- [Solved] UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 3-9: ordinal not in range(128)
- When installing software in Ubuntu, it prompts: E: You don’t have enough free space in /var/cache/apt/archives/.
- Vector series in actual C + +_ To_ fit()
- [Solved] Centos7 Error: gcc: configure: error: in build‘: configure: error: no acceptable C compiler found in $PATH
- How to Delete New Memory in Vector
- How to Solve labelme Install Error in Ubuntu
- How to Create Threads in Linux
- Using common file upload to upload files in SSH project
- The solution of insufficient disk space of docker in Ubuntu
- Installation and configuration of redis in Linux
- [Solved] Go use zoom to connect DM database and start reporting error in Linux
- Solve the problem of 404 Not Found error in nginx accessing dynamic interface
- [Solved] configure: error: no acceptable C compiler found in $PATH
- [Solved] Error in installing backups.lzma for Python on Linux