The occurrence of this error is also inexplicable. The error is reported when importing the KFP module after installing the KFP module, but there is no error in its own installation process.
Open KFP to locate the error position:
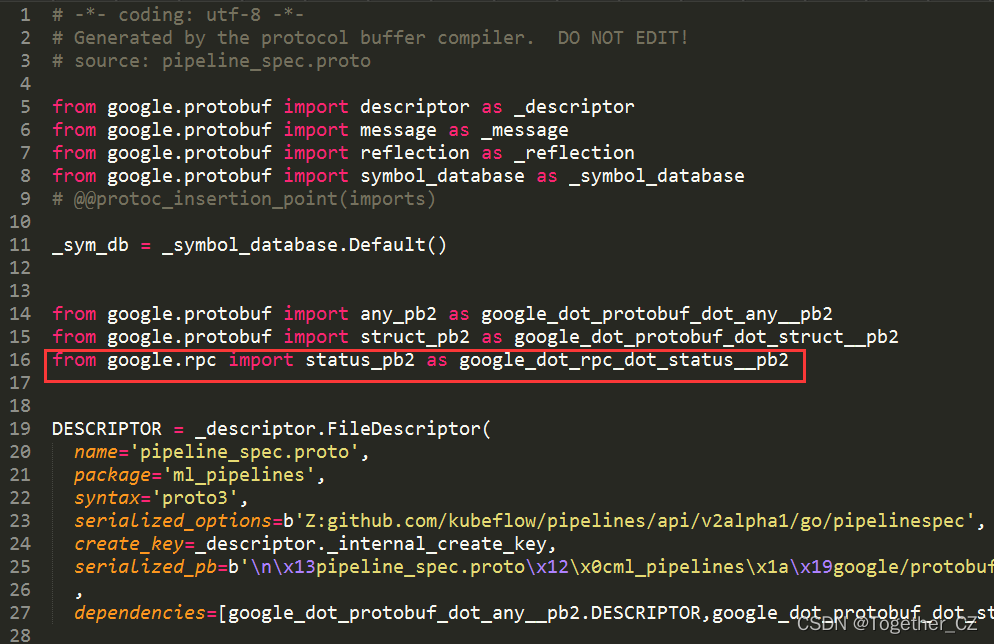
According to the past experience, after all the troubleshooting, I still can’t find the cause of the error. At this time, I have to open the local Google installation directory. The screenshot is as follows:

It was found that there was no RPC directory. The reason was found. Because I really didn’t want to study more, I created a new virtual environment and installed it. After that, I copied all the modules in Google and copied them to my current Google directory, as shown below:
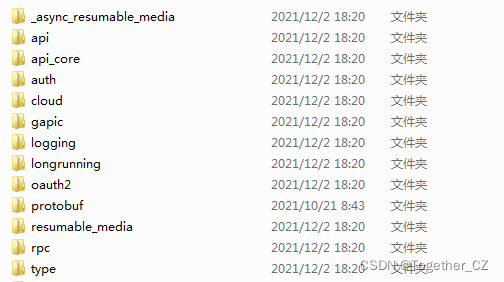
Re import, solve the problem.