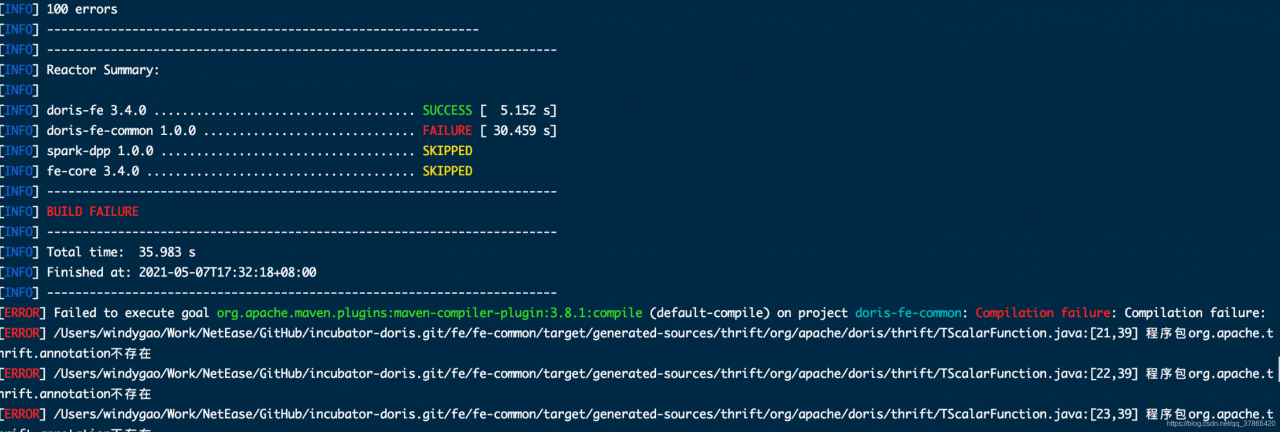
report errors
The error reported by spark when reading Doris table and importing hive table is as follows
Caused by: org.apache.doris.spark.exception.DorisInternalException:
Doris server Doris BE{host='192.168.1.1', port=9060} internal failed,
status code [INTERNAL_ERROR] error message is [failed to initialize storage reader.
tablet=404802818.143972036.284b4c29fe956174-4b76f65647c70daa, res=-230, backend=192.168.1.1]
analysis
Source code analysis
Be node
olap_ scanner.cpp
Status OlapScanner::open() {
SCOPED_TIMER(_parent->_reader_init_timer);
if (_conjunct_ctxs.size() > _direct_conjunct_size) {
_use_pushdown_conjuncts = true;
}
_runtime_filter_marks.resize(_parent->runtime_filter_descs().size(), false);
auto res = _reader->init(_params);
if (res != OLAP_SUCCESS) {
OLAP_LOG_WARNING("fail to init reader.[res=%d]", res);
std::stringstream ss;
ss << "failed to initialize storage reader. tablet=" << _params.tablet->full_name()
<< ", res=" << res << ", backend=" << BackendOptions::get_localhost();
return Status::InternalError(ss.str().c_str());
}
return Status::OK();
}
Failed to read data
be has parameters
tablet_ rowset_ stale_ sweep_ time_ SEC
type: Int64
Description: used to indicate the expiration time of cleaning up the merged version. When the current time is now() minus the latest creation time of rowset in a merged version path is greater than tablet_ rowset_ stale_ sweep_ time_ SEC, clean up the current path and delete these merged rowsets, with the unit of S
default value: 1800
that is, in the process of reading Doris, data is imported into this table, resulting in the deletion of the original version half an hour after the compaction, so the task of spark reading Doris will report an error. When you read a version from Fe, it may be merged
solve
Increase the parallelism of the spark reader. Increasing this parameter can increase the retention time of the old version