Directly find the xml file that introduces the dependency (I am the xml file of spark-core), change the version of snappy-java in it to 1.1.8.4. just reload it.
<dependency>
<groupId>org.xerial.snappy</groupId>
<artifactId>snappy-java</artifactId>
<version>1.1.8.4</version>
<scope>compile</scope>
</dependency>
How to Solve: (Detailed exploration process)
The MacBook Pro with the new M1 pro chip arrived a few days ago, and I couldn’t wait to try it out. Because the chip uses the ARM instruction set, the previous Intel chip computers used the X86 instruction set, so there were inevitably some problems. However, after a year of adaptation, there are basically no major problems, so after a few days of trying, I decided to use the machine for work production.
Because I want to install Java, at first I used the traditional Intel version of jdk (because the main use is jdk1.8, and Oracle only did the adaptation of jdk17 for the arm version), and I feel that some programs in the development will not be executed so fast (and 18 MacBook Pro execution speed is about the same), because after all, it has to go through Rosetta2 translate. Therefore, after using it for a few days, I replaced the Intel version of jdk with the ARM version of jdk, but there is a problem in the documentation, the direct download link given in the documentation is not the ARM version, I found that the execution has been using the intel version of java after installation, then I found that the download link is wrong, you need to manually download the real ARM version of jdk from the official website.
After installing the arm version of jdk, the compilation speed is really improved, but when executing the spark program locally, I encountered such a problem, the detailed log is as follows:
Caused by: org.xerial.snappy.SnappyError: [FAILED_TO_LOAD_NATIVE_LIBRARY] no native library is found for os.name=Mac and os.arch=aarch64
at org.xerial.snappy.SnappyLoader.findNativeLibrary(SnappyLoader.java:331)
at org.xerial.snappy.SnappyLoader.loadNativeLibrary(SnappyLoader.java:171)
at org.xerial.snappy.SnappyLoader.load(SnappyLoader.java:152)
at org.xerial.snappy.Snappy.<clinit>(Snappy.java:47)
at org.apache.parquet.hadoop.codec.SnappyDecompressor.decompress(SnappyDecompressor.java:62)
at org.apache.parquet.hadoop.codec.NonBlockedDecompressorStream.read(NonBlockedDecompressorStream.java:51)
at java.io.DataInputStream.readFully(DataInputStream.java:195)
at java.io.DataInputStream.readFully(DataInputStream.java:169)
at org.apache.parquet.bytes.BytesInput$StreamBytesInput.toByteArray(BytesInput.java:205)
at org.apache.parquet.column.values.dictionary.PlainValuesDictionary$PlainBinaryDictionary.<init>(PlainValuesDictionary.java:89)
at org.apache.parquet.column.values.dictionary.PlainValuesDictionary$PlainBinaryDictionary.<init>(PlainValuesDictionary.java:72)
at org.apache.parquet.column.Encoding$1.initDictionary(Encoding.java:90)
at org.apache.parquet.column.Encoding$4.initDictionary(Encoding.java:149)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.<init>(VectorizedColumnReader.java:103)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.checkEndOfRowGroup(VectorizedParquetRecordReader.java:280)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.nextBatch(VectorizedParquetRecordReader.java:225)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.nextKeyValue(VectorizedParquetRecordReader.java:137)
at org.apache.spark.sql.execution.datasources.RecordReaderIterator.hasNext(RecordReaderIterator.scala:39)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:105)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:177)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:105)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.scan_nextBatch$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:395)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.agg_doAggregateWithKeys$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:395)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:125)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335)
... 3 more
org.xerial.snappy is a compressed/uncompressed library, I am using spark version 2.2.0, which depends on snappy 1.1.2.6. The contents of this version are as follows:
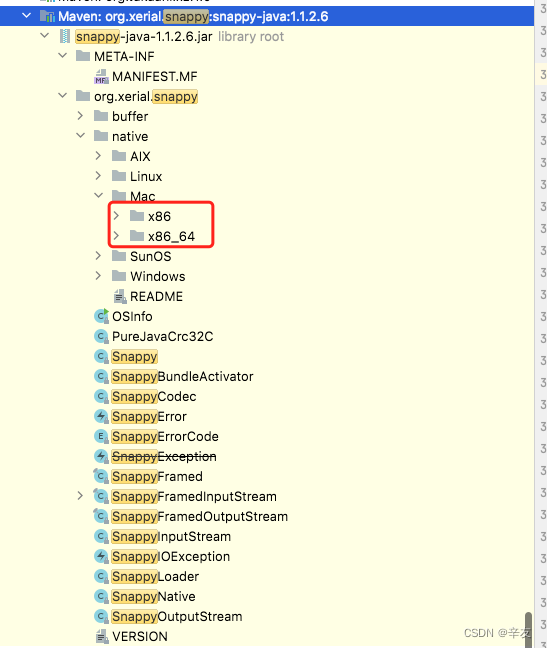
As you can see, this version of snappy only supports x86 and x86_64 for Mac systems, not arm64. Just find the dependency that introduces snappy-java and upgrade its version directly to the latest version.
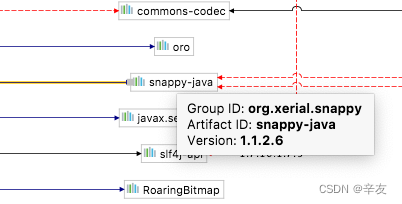
Searching through IDEA’s dependency graph, I found that the library was imported by spark-core, my version of spark-core is 2.2.0 and the snappy-java introduced is 1.1.2.6. As shown in the figure:
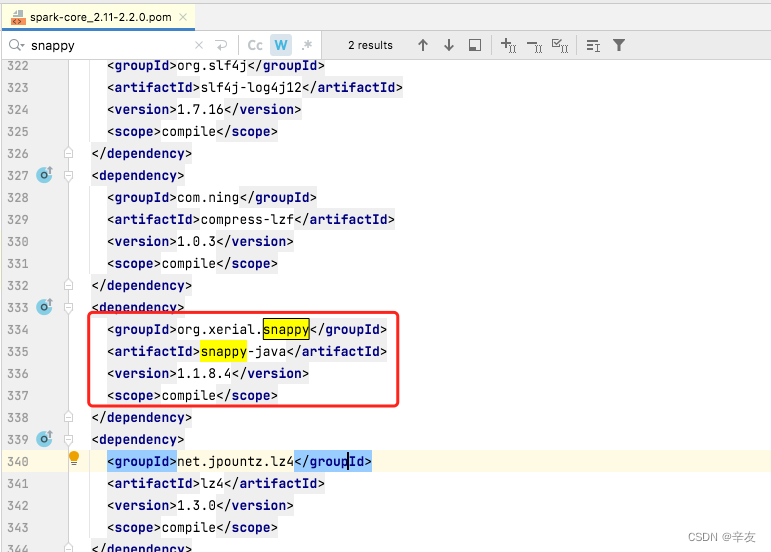
The latest version of snappy-java is 1.1.8.4 in the mvnrepository, so replace the original version in the spark-core xml file directly, as shown in the figure
Reload the dependency and execute it again. The code executes smoothly and the problem is solved.

