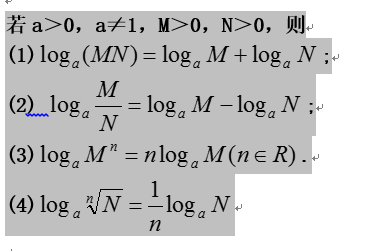##Login items
the program started by the current user of Mac OSX after successful login. The configuration file of the startup items of this category is stored in ~ / library / preferences/ com.apple.loginitems . plist, so only for the current user, you can set it in the following ways:
1. Set under “users and groups” in system preferences, which can be deleted, added, opened and closed;
2. You can modify ~ / library / preferences directly/ com.apple.loginitems . plist configuration file, in which each startup item corresponds to a dictionary, with three values of alias, icon and name, in which name is nsstring type and others are data type. We don’t know how to generate it serially, so we can delete it at present;
3. Add and delete through lssharedfilelistinsertitemurl and lssharedfilelistitemremove method, and related introduction (the registration program starts up)

##Launchdemon
this type of startup items are all started by launchd. Launchd is the key process used to initialize the system environment in Mac OS. It is the first process started in OS environment after the kernel is loaded successfully. In this way, it is very easy to configure the self booting item. Only one plist file is needed. The directory where the plist file exists is
~/Library/LaunchAgents
/Library/LaunchAgents
/System/Library/LaunchAgents
The above three directories are the recommended paths for the system. They are the processes started after login
~/Library/LaunchDaemons
/Library/LaunchDaemons
/System/Library/LaunchDaemons
If it is placed in the above three directories, it will be started as the daemons and the processes started immediately after the system starts
Different directory processes have different permissions and priorities. You can set them in the following ways:
1. Through launchctl load xxx.plist Or launchctl unload xxx.plist Command to add and delete the specified startup items;
2. Directly create, modify and delete plist files under related directories.
The main fields in plist and their meanings
Label is used as a unique identifier in launchd, similar to that every program has an identifier.
User name specifies the user to run the startup item. This item is applicable only when launchd is running as root.
Groupname specifies the group to run the startup item. This item applies only when launchd is running as root.
The key value of keepalive is used to control whether the executable file runs continuously or starts after meeting specific conditions. The default value is false, that is to say, it will not start until the specific conditions are met. When the setting value is true, the executable file will be opened unconditionally and kept in the whole system running cycle.
Runatload identifies that launchd starts the executable file specified by the path immediately after loading the service. The default value is false.
The value program is used to specify the path of the executable file of the process.
Programarguments if program is not specified, it must be specified, including executable files and running parameters.
##3. Startupitems
startupitems, as the name suggests, are programs that run during the system startup. They can be programs that terminate immediately after running (for example, start to empty the wastebasket), or they can be background processes that continue in the system running cycle.
Startupitems are generally stored in the following two paths:
1)/System/Library/StartupItems
2)/Library/StartupItems
Most of the system related startupitems are placed in the path of / system / library / startupitems, and they will be executed prior to the path of / library / startupitems, because the startupitems in the path of the former provide system level basic services, such as crash reporting, core graphics services, system The latter path does not exist by default and needs to be created manually.
Here we take iceberg control tower in / library / startupitems directory as an example.

In short, on Mac OS X, a startupitems includes the following two aspects:
1) Executable program;
2) Plist file containing dependent process relationships( StartupParameters.plist )。
StartupParameters.plist Is a property list that contains the necessary conditions for running an executable program, the main fields in plist, and its meaning

The plist needs to obtain root permission, which includes several aspects:
1)Description;
A simple description of the service is only a description, not the actual process name.
2)Provides;
Specify the services provided by startupitems. As shown in the plist file provides, the background process started by startupitems is named iceberg control tower.
Provides can specify multiple services, which are reflected in the figure as item0, Item1 And so on. There is only item0.
3)Uses;
Specifies the services that need to be opened before startupitems is loaded. The Mac OS X system first attempts to load the service specified in uses, and then loads startupitems. In other words, even if the service specified in uses is not loaded successfully, the system will still load startupitems.
4)OrderPreference;
Specifies the chronological order in which startupitems are executed. The importance of this order comes after uses, which is the order after the specified uses are executed. Possible values include: first, early, none (default), late, last.
5)Messages。
The Executable File
Note: 1) the name of the executable file is the same as that of the folder where it is located, which is the default rule of the system.
2) Root permission is required to operate the executable.
3) The executable is a shell script.
Open the executable file with the same name in the icebergcontroltower file directory to see the specific content of the script

The general executable file includes the following aspects:
1)./etc/ rc.common
A script library provided by apple, which contains the interface of importing parameters for executable files. Here, the library mainly calls runservice.
2)StartService(), StopService(), RestartService()
When the parameters received by the executable file are start, stop or restart, the corresponding functions are executed.
Parameter meaning:
Start: start the service during startup;
Stop: stop the service during shutdown;
Restart: restart the service under specific conditions.
3)RunService “$1”
Executes the service specified by the first parameter passed to the script.
“$1” represents the first parameter passed to the script. For example, if the passed in parameter is start, startservice() is executed.
(some of the contents are quoted in http://blog.csdn.net/abby_ sheen/article/details/7817198