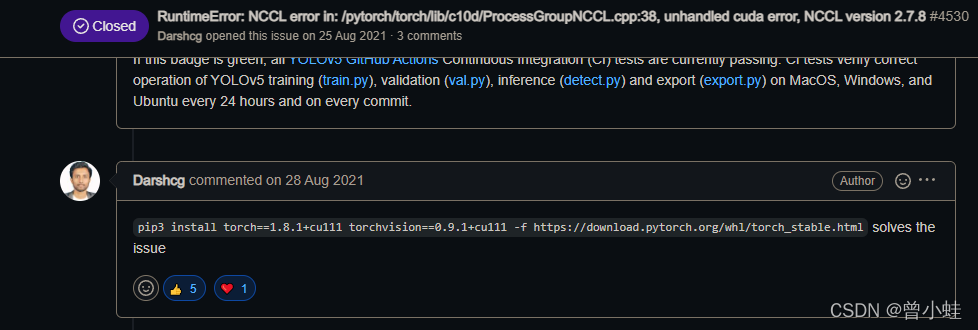
The method used in this paper
The versions of pytorch, cudatoolkit and CUDA driver should be consistent
Problem description
When training the stylegan3 model with multi GPU:
python train.py --outdir=training-runs --cfg=stylegan3-r \
--data=datastes/your_data.zip \
--cfg=stylegan3-r --gpus=4 --batch=32 --gamma=8 --kimg=1800 --snap=50 --tick=2
Error Messages:
torch.multiprocessing.spawn.ProcessRaisedException:
……
RuntimeError: NCCL error in: /opt/conda/conda-bld/pytorch_1631630841592/work/torch/lib/c10d/ProcessGroupNCCL.cpp:911, unhandled cuda error, NCCL version 2.7.8
ncclUnhandledCudaError: Call to CUDA function failed.
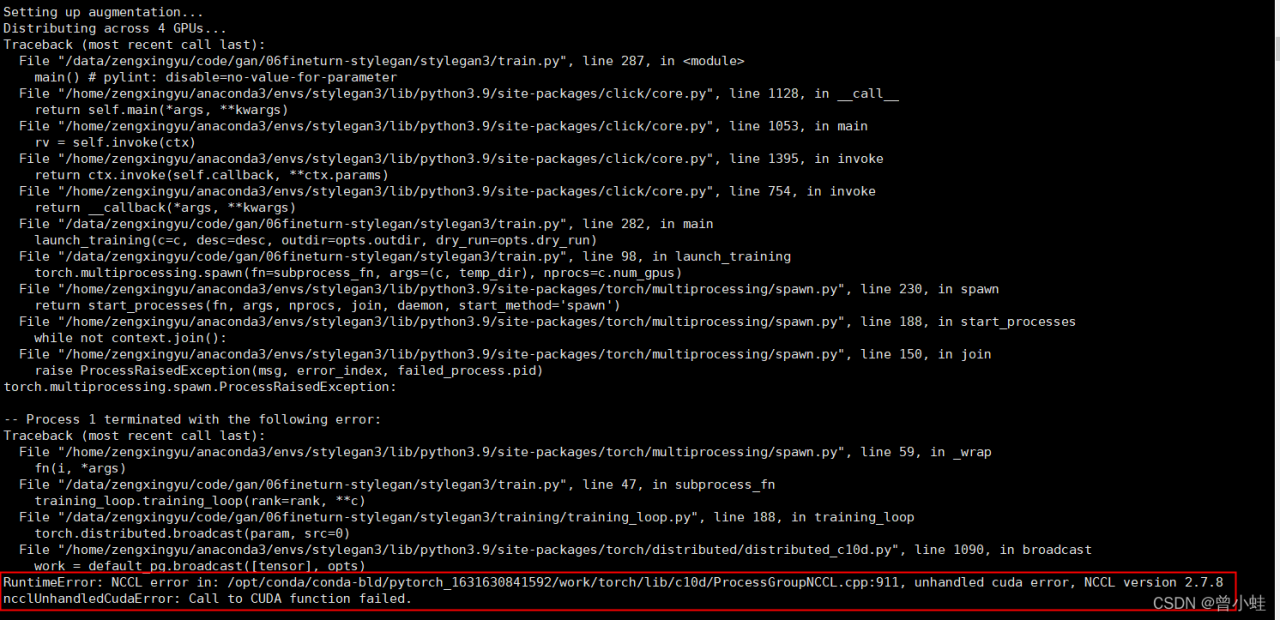
Local Environment
4xTeslaV100 graphics card drivers and CUDA version 11.0

stylegan3 Default Environment
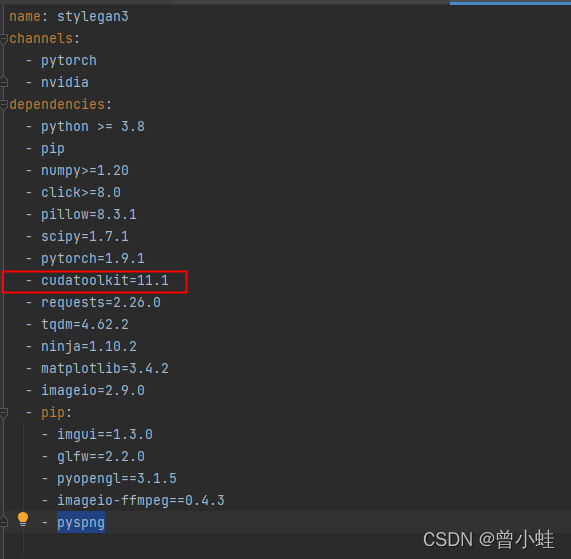
Solution:
Go to the pytorch official website and search the corresponding version of Cudatookit
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch
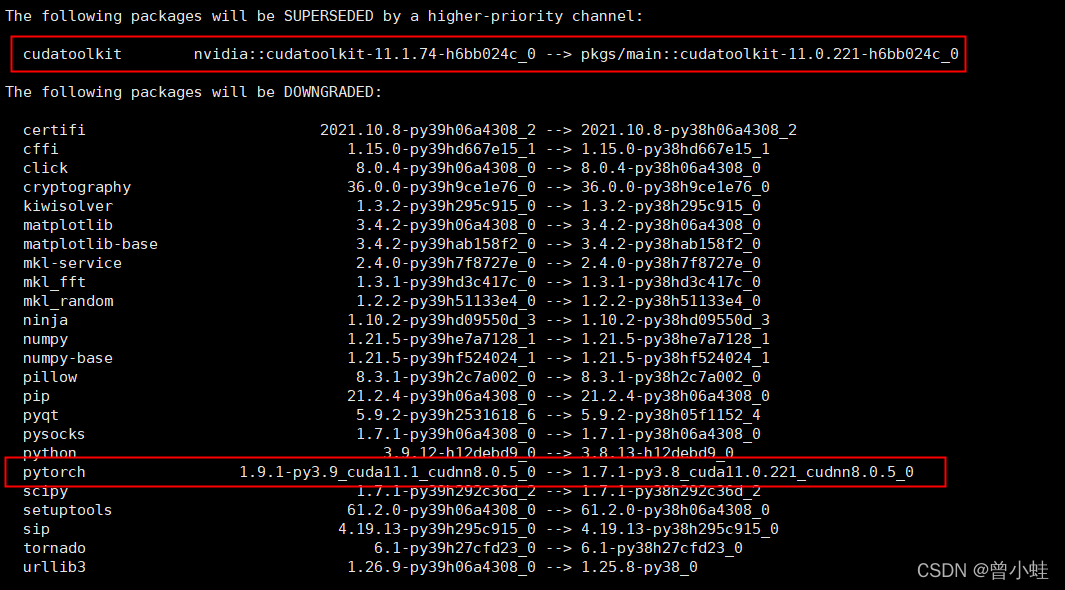
Tried Method:
Method 1: install nccl (this article is useless)
Method 2: the versions of pytorch, CUDA toolkit and CUDA driver are the same