Hi~ Long time no update
1.Problems that need attention after restarting kafka:
Kafka will have a write file a in the target storage location during execution,this file a will keep a write state for a while,usually one hour Heavy
Generate a new write file b,End the last write file a(The duration of this ending needs to check the configuration of each cluster). then restart
Here comes the problem,The last write file a,will be recreated after restarting,The last write file b,So the current
a will keep writing status,when reading and writing file a, it will report an error,including importing Hive query will also report an error&# xff08; load to hive
The table will not report an error,but it will report an error when selecting),because this file is always in the write state,It is inoperable,It is also called writing
Lock(I believe everyone has heard of).
Solution:Then we need to manually terminate the write status of the write file,First we need to determine the status of the write file,In the command
Execute the command on the line :
hdfs fsck /data/logs/( Write the directory where the file is located,Change according to where your file is located) -openforwrite
The displayed files are all in the write state:

After seeing the writing file,execute the command to stop all writing files,here explain,why all stop&# xff0c; Logically, it should be stopped before
A write file, but stopping all of them can also solve the problem, is relatively simple and violent, because manual stopping will automatically generate a
, writing files, so you can stop them all. then now execute the command :
hdfs debug recoverLease -path /logs/common_log/2022-09 -16/FlumeData.1663292498820.tmp(Execute the previous command to display Output write file path) -retries 3
It can be solved by executing each file once,Say more,If this file has been loaded into hive,, you need to go to /user/warehouse/hive/ to find this write status file

2.CDH's Cloudera Manager launch browser access returns 500error:
① First check the configuration of the /etc/hosts file, only need to leave these two lines with the cluster The intranet IP mapping can be
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
②It is also necessary to check whether the ports related to ,cm are occupied by the firewall.
③ Then restart CM, execute the command
nameNode:systemctl stop cloudera-scm-server
Then execute :systemctl stop cloudera-scm-agent on each node
nameNode:systemctl start cloudera-scm-server
Then execute :systemctl start cloudera-scm-agent on each node
Attention Pay attention to!!! The execution order of these commands cannot be reversed, Otherwise, there may be problems with cluster startup.
Then you can systemctl status cloudera-scm-server, systemctl status cloudera-scm-agent
Check out the operation.
②If cm starts and can access , but starts HDFS error 1 or 2
1.Unable to retrieve non-local non-loopback IP address. Seeing address: cm/127.0.0.1
2.ERROR ScmActive-0:com.cloudera.server.cmf. components.ScmActive: ScmActive was not able to access CM identity to validate it.2017-04-18 09:40 :29,308 ERROR ScmActive-0
So congratulations ,find a solution.
First find the source database of CM,Some of them were configured at that time,If you don’t know, ask the person who installed them,Almost all of them are in
Don't ask me for the , account password on nameNode ~, then show databases; can See that there is a cm or scm library
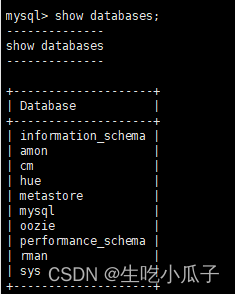
use this library,then show tables;
You will see a table called HOSTS,View the data of this table-select * from HOSTS ;
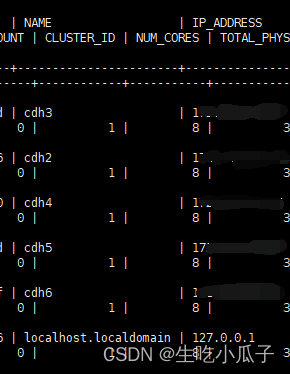
You will find that there is a different line , that is, there is a difference between NAME and IP_ADDRESS, Then you need to modify it back, to
The name and IP_ADDRESS of the intranet,I believe everyone will modify it!Then restart the CM,It's done!