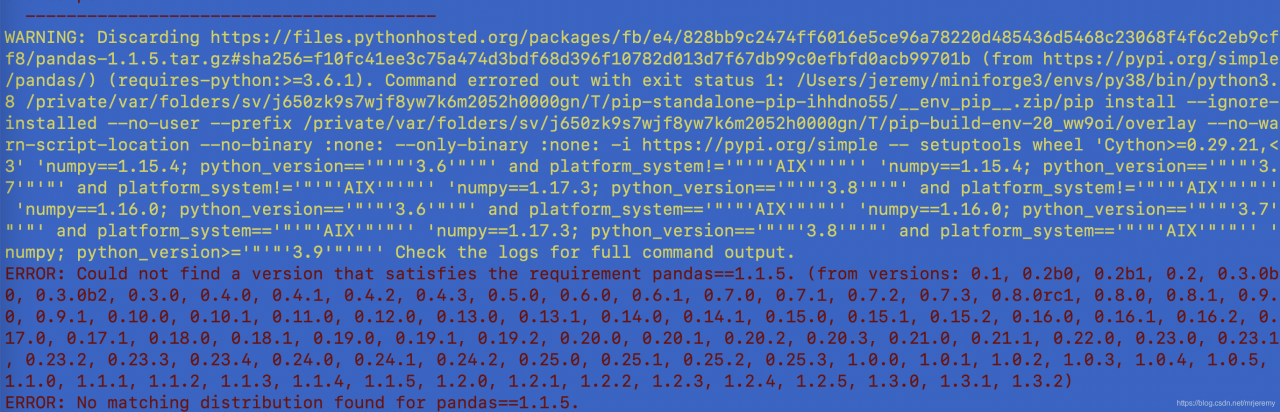
Key errors are as follows:
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
All error prompts are as follows:
//
Traceback (most recent call last):
Traceback (most recent call last):
File "main.py", line 19, in <module>
File "<string>", line 1, in <module>
t.train()
File "c:\Paper Code\RCAN-master-Real\RCAN_TrainCode\code\trainer.py", line 45, in train
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\spawn.py", line 105, in spawn_main
for batch, (lr, hr, _, idx_scale) in enumerate(self.loader_train):
File "c:\Paper Code\RCAN-master-Real\RCAN_TrainCode\code\dataloader.py", line 144, in __iter__
exitcode = _main(fd)
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\spawn.py", line 114, in _main
prepare(preparation_data)
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\spawn.py", line 225, in prepare
return _MSDataLoaderIter(self)
File "c:\Paper Code\RCAN-master-Real\RCAN_TrainCode\code\dataloader.py", line 117, in __init__
_fixup_main_from_path(data['init_main_from_path'])
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\spawn.py", line 277, in _fixup_main_from_path
w.start()
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\process.py", line 105, in start
run_name="__mp_main__")
File "C:\Anaconda3\envs\pytorch0.4.0\lib\runpy.py", line 263, in run_path
self._popen = self._Popen(self)
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\context.py", line 223, in _Popen
pkg_name=pkg_name, script_name=fname)
File "C:\Anaconda3\envs\pytorch0.4.0\lib\runpy.py", line 96, in _run_module_code
mod_name, mod_spec, pkg_name, script_name)
File "C:\Anaconda3\envs\pytorch0.4.0\lib\runpy.py", line 85, in _run_code
return _default_context.get_context().Process._Popen(process_obj)
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\context.py", line 322, in _Popen
exec(code, run_globals)
File "c:\Paper Code\RCAN-master-Real\RCAN_TrainCode\code\main.py", line 19, in <module>
t.train()
return Popen(process_obj)
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\popen_spawn_win32.py", line 65, in __init__
File "c:\Paper Code\RCAN-master-Real\RCAN_TrainCode\code\trainer.py", line 45, in train
for batch, (lr, hr, _, idx_scale) in enumerate(self.loader_train):
File "c:\Paper Code\RCAN-master-Real\RCAN_TrainCode\code\dataloader.py", line 144, in __iter__
reduction.dump(process_obj, to_child)
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\reduction.py", line 60, in dump
return _MSDataLoaderIter(self)
File "c:\Paper Code\RCAN-master-Real\RCAN_TrainCode\code\dataloader.py", line 117, in __init__
w.start()
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\process.py", line 105, in start
ForkingPickler(file, protocol).dump(obj)
self._popen = self._Popen(self)
BrokenPipeError: [Errno 32] Broken pipe
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\context.py", line 322, in _Popen
return Popen(process_obj)
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\popen_spawn_win32.py", line 33, in __init__
prep_data = spawn.get_preparation_data(process_obj._name)
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\spawn.py", line 143, in get_preparation_data
_check_not_importing_main()
File "C:\Anaconda3\envs\pytorch0.4.0\lib\multiprocessing\spawn.py", line 136, in _check_not_importing_main
is not going to be frozen to produce an executable.''')
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
Original code:
torch.manual_seed(args.seed)
checkpoint = utility.checkpoint(args)
if checkpoint.ok:
loader = data.Data(args)
model = model.Model(args, checkpoint)
loss = loss.Loss(args, checkpoint) if not args.test_only else None
t = Trainer(args, loader, model, loss, checkpoint)
while not t.terminate():
t.train()
t.test()
checkpoint.done()
After modification:
if __name__ == '__main__':
torch.manual_seed(args.seed)
checkpoint = utility.checkpoint(args)
if checkpoint.ok:
loader = data.Data(args)
model = model.Model(args, checkpoint)
loss = loss.Loss(args, checkpoint) if not args.test_only else None
t = Trainer(args, loader, model, loss, checkpoint)
while not t.terminate():
t.train()
t.test()
checkpoint.done()
Run~~
Study notes.