Background
After solving the installation of docker desktop above, I continue to operate according to the instructions of vs code plug-in remote container, in order to connect and edit the files in the container on the remote server (Linux) on the PC (Windows).
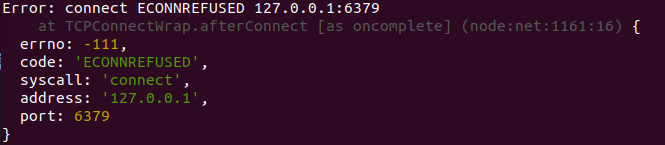
After everything is completed, the container is connected, but an error is reported. The log content is cannot connect to the docker daemon at http://docker.example.com. Is the docker daemon running. However, the docker desktop of my PC has already started docker, no problem.
After searching, I found that my account on the server is not in the docker group, that is, I need sudo to execute the docker instruction every time. The solution is to add my account to the docker group.
Solution:
Add according to the instructions on the official website, and then everything goes well and the problem is solved. The following code is a simple version, you can go directly to the official website.
cat /etc/group | grep docker # Print group information and filter with grep to view onlydocker
# If there are no results, run the following command to create a new docker group
sudo groupadd docker
# If the cat command yields results, then instead of creating a new group, just run the following command
sudo usermod -aG docker $USER # where $USER is replaced by your account name
newgrp docker # In Linux environment, make the group update take effect; other environments see the official website link
docker run hello-world # Check if docker can be executed without sudo
Post-installation steps for Linux | Docker Documentation
To access files in a remote server’s container with vs Code
1. Install VS code on PC
2. Connect to the server remotely: Find the Remote-SSH plug-in in the extension of VS code, configure the ssh file after installation, and connect to the server successfully
3. Find Remote-Container in the extension of VS code, install it, and then install docker and WSL2 software according to the extension’s introduction ( the link where the problem occurred above )
4. Connect to the server according to the introduction of Remote-Container (the problematic link in this article)