first, the previous wave reported an error message:
/pytorch/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [35,0,0], thread: [96,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [35,0,0], thread: [97,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [35,0,0], thread: [98,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [35,0,0], thread: [99,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [35,0,0], thread: [100,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [35,0,0], thread: [101,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [35,0,0], thread: [102,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [35,0,0], thread: [103,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
/pytorch/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType,
......
......
......
/pytorch/aten/src/THC/THCTensorIndex.cu:362: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [35,0,0], thread: [95,0,0] Assertion `srcIndex < srcSelectDimSize` failed.
Traceback (most recent call last):
File "../paragrah_selector/para_sigmoid_train.py", line 533, in <module>
main()
File "../paragrah_selector/para_sigmoid_train.py", line 463, in main
eval_loss = eval_model(model, eval_data, device)
File "../paragrah_selector/para_sigmoid_train.py", line 419, in eval_model
loss, logits = model(input_ids, segment_ids, input_mask, labels=label_ids)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 143, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/parallel/data_parallel.py", line 153, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 83, in parallel_apply
raise output
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/parallel/parallel_apply.py", line 59, in _worker
output = module(*input, **kwargs)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/lisen/caiyun_projects/generative_mrc/paragrah_selector/modeling.py", line 1001, in forward
loss = loss_fn(logits, labels)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/modules/loss.py", line 504, in forward
return F.binary_cross_entropy(input, target, weight=self.weight, reduction=self.reduction)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/functional.py", line 2027, in binary_cross_entropy
input, target, weight, reduction_enum)
RuntimeError: reduce failed to synchronize: device-side assert triggered
terminate called after throwing an instance of 'c10::Error'
what(): CUDA error: device-side assert triggered (insert_events at /pytorch/aten/src/THC/THCCachingAllocator.cpp:470)
frame #0: std::function<std::string ()>::operator()() const + 0x11 (0x7f0e52afc021 in /home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/lib/libc10.so)
frame #1: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x2a (0x7f0e52afb8ea in /home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/lib/libc10.so)
frame #2: <unknown function> + 0x13dbd92 (0x7f0e5e065d92 in /home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/lib/libcaffe2_gpu.so)
frame #3: at::TensorImpl::release_resources() + 0x50 (0x7f0e534c6440 in /home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/lib/libcaffe2.so)
frame #4: <unknown function> + 0x2af03b (0x7f0e51bb703b in /home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/lib/libtorch.so.1)
frame #5: torch::autograd::Variable::Impl::release_resources() + 0x17 (0x7f0e51e29d27 in /home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/lib/libtorch.so.1)
frame #6: <unknown function> + 0x124cfb (0x7f0e8ce4ccfb in /home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #7: <unknown function> + 0x3204af (0x7f0e8d0484af in /home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #8: <unknown function> + 0x3204f1 (0x7f0e8d0484f1 in /home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
<omitting python frames>
frame #25: __libc_start_main + 0xf0 (0x7f0ecf782830 in /lib/x86_64-linux-gnu/libc.so.6)
Aborted (core dumped)
(py36) lisen@octa:~/caiyun_projects/generative_mrc/script$ sh para_sigmoid_train.sh
before heading off to New York next week, we appear under the heading of
before heading off to New York next week. We haven’t lost our labels before heading off to New York before heading off to New York next week. We haven’t lost our labels before heading off to New York next week. And so on. So check your labels carefully. 2. There is something wrong with your word vector, such as the position vector exceeding the preset length of the model, the word vector exceeding the size of the word table, etc.
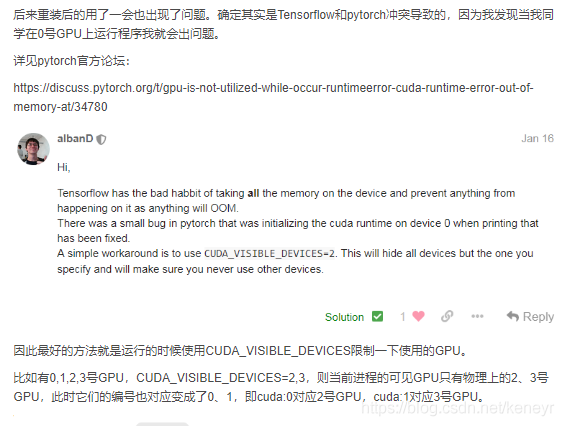
And then, the point of this article, if you just say these two reasons, it might not be easy to figure out the problem. Let me show you a simple debug method, and you’ll see what the problem is. That is: put the model on the CPU and run . If it doesn’t fit, just turn down the batch size. For example, after I finished the adjustment, I reported the following error:
File "../paragrah_selector/para_sigmoid_train.py", line 533, in <module>
main()
File "../paragrah_selector/para_sigmoid_train.py", line 463, in main
eval_loss = eval_model(model, eval_data, device)
File "../paragrah_selector/para_sigmoid_train.py", line 419, in eval_model
loss, logits = model(input_ids, segment_ids, input_mask, labels=label_ids)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/lisen/caiyun_projects/generative_mrc/paragrah_selector/modeling.py", line 987, in forward
_, pooled_output = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/lisen/caiyun_projects/generative_mrc/paragrah_selector/modeling.py", line 705, in forward
embedding_output = self.embeddings(input_ids, token_type_ids)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/lisen/caiyun_projects/generative_mrc/paragrah_selector/modeling.py", line 281, in forward
position_embeddings = self.position_embeddings(position_ids)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/lisen/.conda/envs/py36/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: index out of range at /pytorch/aten/src/TH/generic/THTensorEvenMoreMath.cpp:191
thorough analysis clearly shows that File “/home/lisen/caiyun_projects/generative_mrc/paragrah_selector/modeling. Py”, line 281, in forward
position_embeddings = self. Position_embeddings (position_ids) “, If the position vector exceeds the preset length value of the model, then I go back to check and find that the longer text is indeed not truncated to that length, leading to this problem.