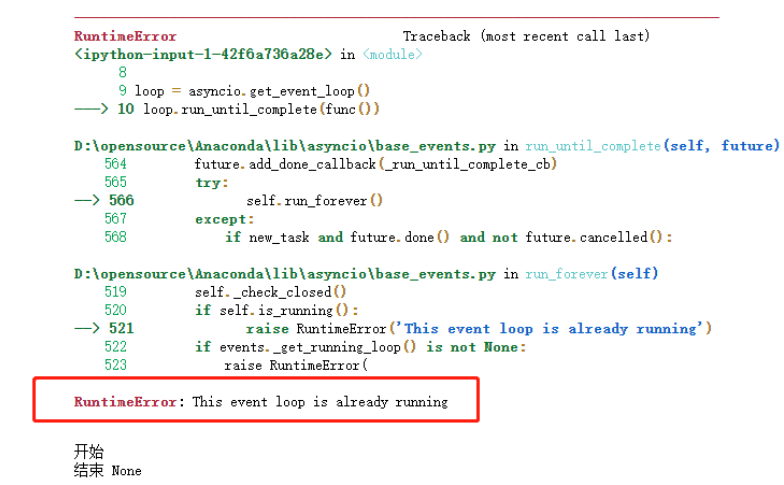
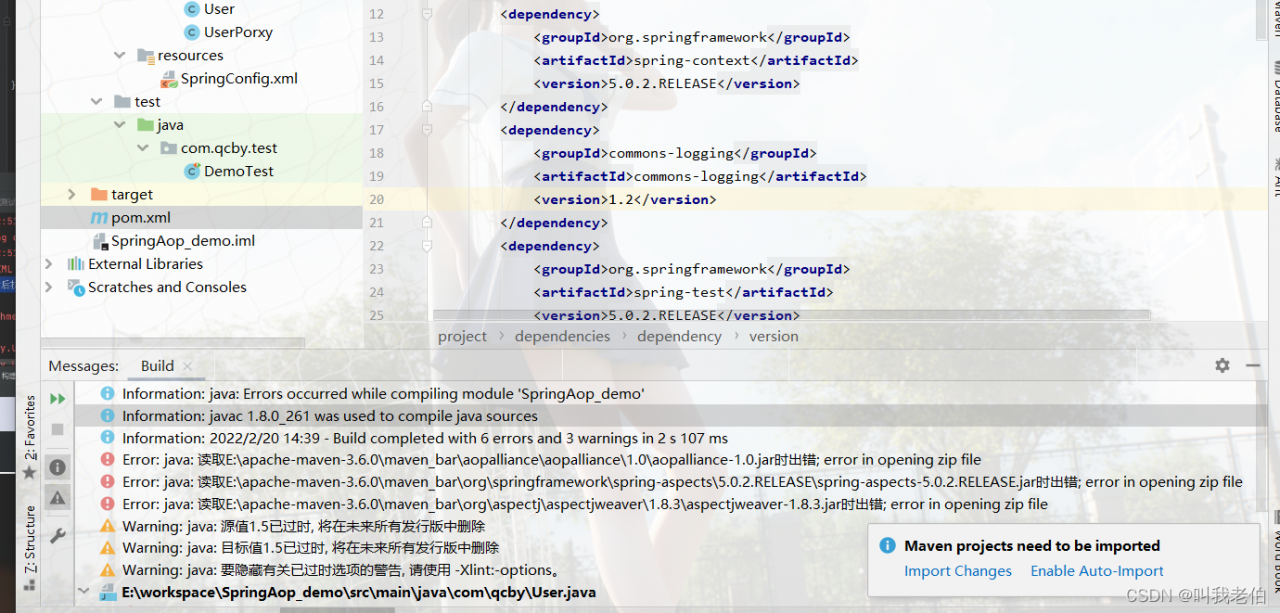
Error:
An occasional fault is found and an error is reported when initializing the database connection pool:
public key is not available client side (option serverRsaPublicKeyFile not set)
Detailed error reporting contents are as follows:
2022-08-24 16:35:08.008 ERROR 233504 --- [ main] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Exception during pool initialization.
java.sql.SQLTransientConnectionException: Could not connect to address=(host=127.0.0.1)(port=3306)(type=master) : RSA public key is not available client side (option serverRsaPublicKeyFile not set)
at org.mariadb.jdbc.internal.util.exceptions.ExceptionFactory.createException(ExceptionFactory.java:79)
at org.mariadb.jdbc.internal.util.exceptions.ExceptionFactory.create(ExceptionFactory.java:192)
at org.mariadb.jdbc.internal.protocol.AbstractConnectProtocol.connectWithoutProxy(AbstractConnectProtocol.java:1372)
at org.mariadb.jdbc.internal.util.Utils.retrieveProxy(Utils.java:635)
After a long time of troubleshooting, it was finally found that the reason is:
the database used in the project is MySQL 8.0.X, but the connection driver used is MariaDB (MariaDB was used before). pom file dependencies are as follows:
<dependency>
<groupId>org.mariadb.jdbc</groupId>
<artifactId>mariadb-java-client</artifactId>
<version>2.6.1</version>
</dependency>
Solution:
Just change the driver to MySQL
pom.xml dependency
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
application.yml driver and URL configuration.
spring:
datasource:
driver: driver: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/databaseName?serverTimezone=GMT%2B8&characterEncoding=utf8