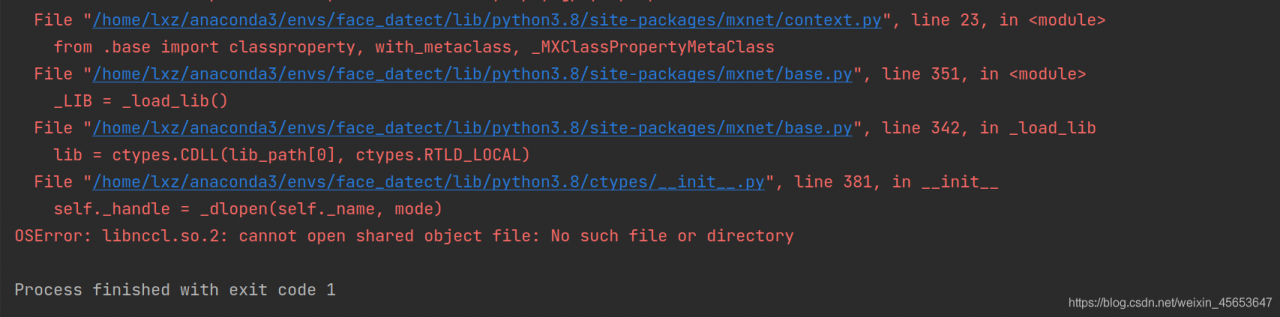
1. The system configuration is: windows10 + python3.6 + anaconda3 + swig4.0.2. Swig needs to add environment variables to the system environment manually.
2. According to the official readme file, execute the command [swig – C + + – Python polyiou. I], basically no problem.
3. When executing the command [Python setup. Py build]_ The error [if self. LD] appears when “ext — inplace”_ version >= ” 2.10.90″: TypeError: ‘>=’ not supported between instances of ‘NoneType’ and ‘str’】。 In the python installation path of the virtual environment, find the file of lib distutils distutils.cfg, open it and find the following content: [build] compiler = mingw32, the content of the file is correct.
4. Solution: after exploration and research, we need to configure GCC, install mingw-w64 compiler, command is [CONDA install libpython m2w64 toolchain – C msys2], and then execute the command [Python setup. Py build]_ Ext — inplace], run successfully, and you will find that the_ polyiou.cp36-win_ Amd64.pyd file.