When you need to generate the package and corresponding version required by a project, you can first CD it to the project directory, and then enter:
pipreqs ./
Code error is reported as follows:
Traceback (most recent call last):
File "f:\users\asus\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "f:\users\asus\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "F:\Users\asus\Anaconda3\Scripts\pipreqs.exe\__main__.py", line 7, in <module>
File "f:\users\asus\anaconda3\lib\site-packages\pipreqs\pipreqs.py", line 470, in main
init(args)
File "f:\users\asus\anaconda3\lib\site-packages\pipreqs\pipreqs.py", line 409, in init
follow_links=follow_links)
File "f:\users\asus\anaconda3\lib\site-packages\pipreqs\pipreqs.py", line 122, in get_all_imports
contents = f.read()
File "f:\users\asus\anaconda3\lib\codecs.py", line 321, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbb in position 570: invalid start byte
Find line 122 of pipreqs.py and modify the coding format to iso-8859-1.
with open_func(file_name, "r", encoding='ISO-8859-1') as f:
contents = f.read()
After trying many encoding formats, such as GBK, GB18030, etc., errors are still reported until iso-8859-1 is used. The specific reason is that the parameter setting of decode is too strict. It is set to igonre, but it is not found where the decode function is changed. Change it when you find it later.



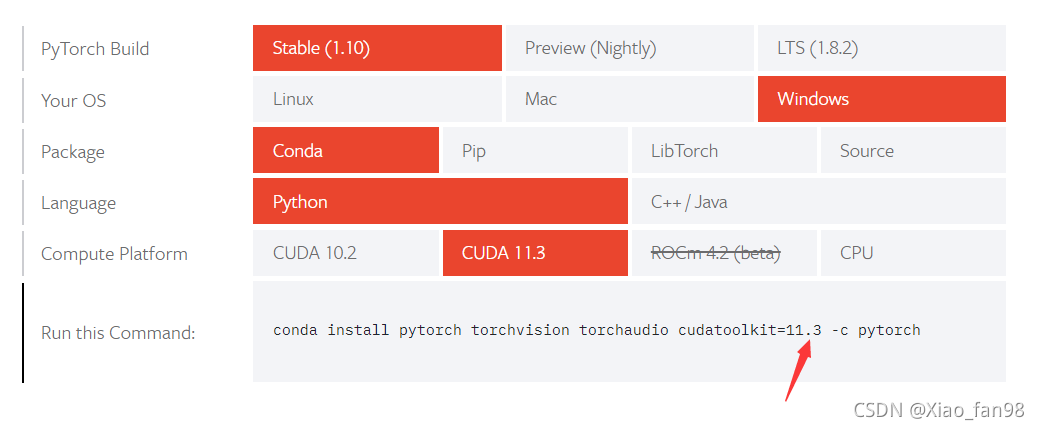 The versions at the two arrows should be consistent.
The versions at the two arrows should be consistent.