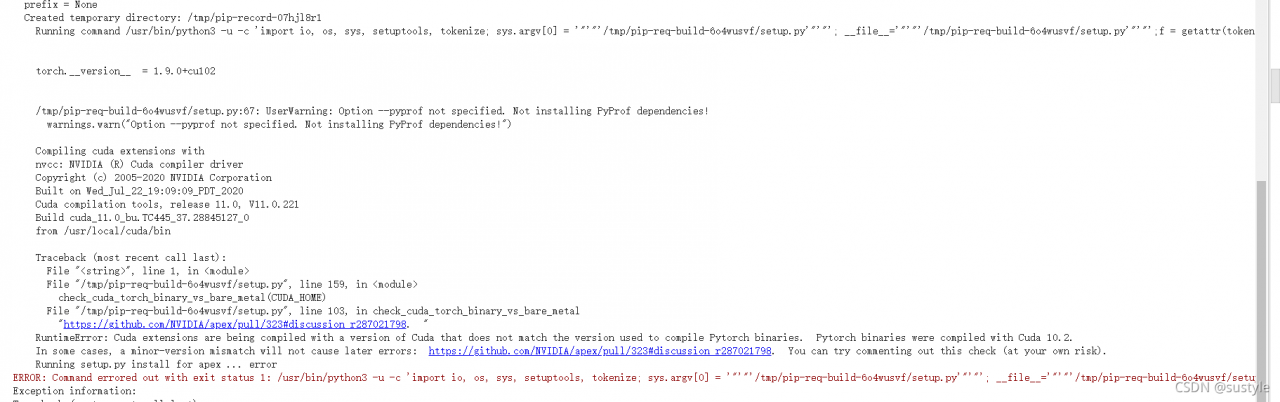
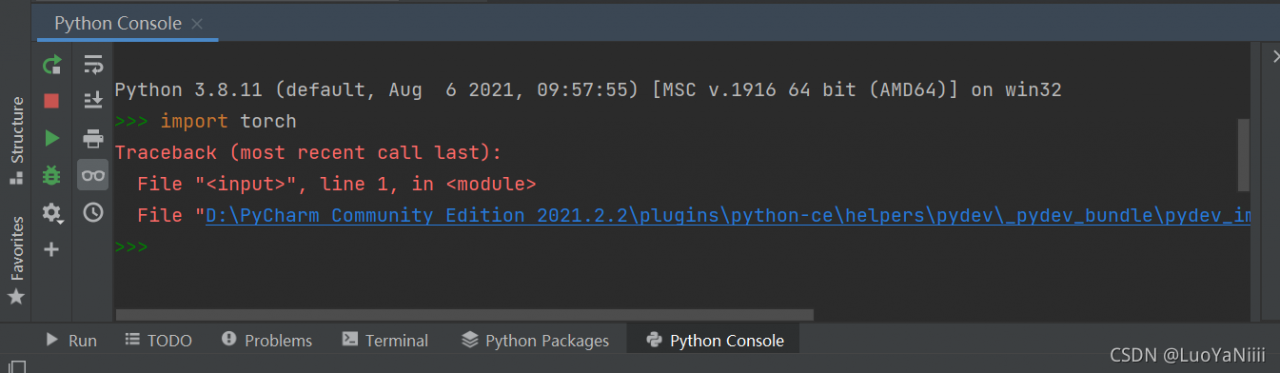
This error is reported because you did not successfully install apex. Note ~: it is not PIP install apex
ERROR: Command errored out with exit status 1: /usr/bin/python3 -u -c 'import io, os, sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-req-build-6o4wusvf/setup.py'"'"'; __file__='"'"'/tmp/pip-req-build-6o4wusvf/setup.py'"'"';f = getattr(tokenize, '"'"'open'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from setuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' --cpp_ext --cuda_ext install --record /tmp/pip-record-07hjl8r1/install-record.txt --single-version-externally-managed --compile --install-headers /usr/local/include/python3.7/apex Check the logs for full command output.
Exception information:
Traceback (most recent call last):
Processing method: Step 1: use this command to check the CUDA version supported by your machine:
nvcc --version
Step 2: use the following command to view the version of CUDA you currently have installed.
pip list
Note: when installing apex, you must ensure that the two versions are consistent. That is, if the version supported by the machine is 11.0, you can install CUDA of the corresponding torch version.
First use the following command to uninstall the original torch of your machine
!pip uninstall -y torch torchvision torchaudio
Then use the following command to install. For example, the machine here supports CUDA version 11.0
!pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
Next, install apex:
!git clone https://github.com/NVIDIA/apex
%cd apex
!pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
The above work is completed.

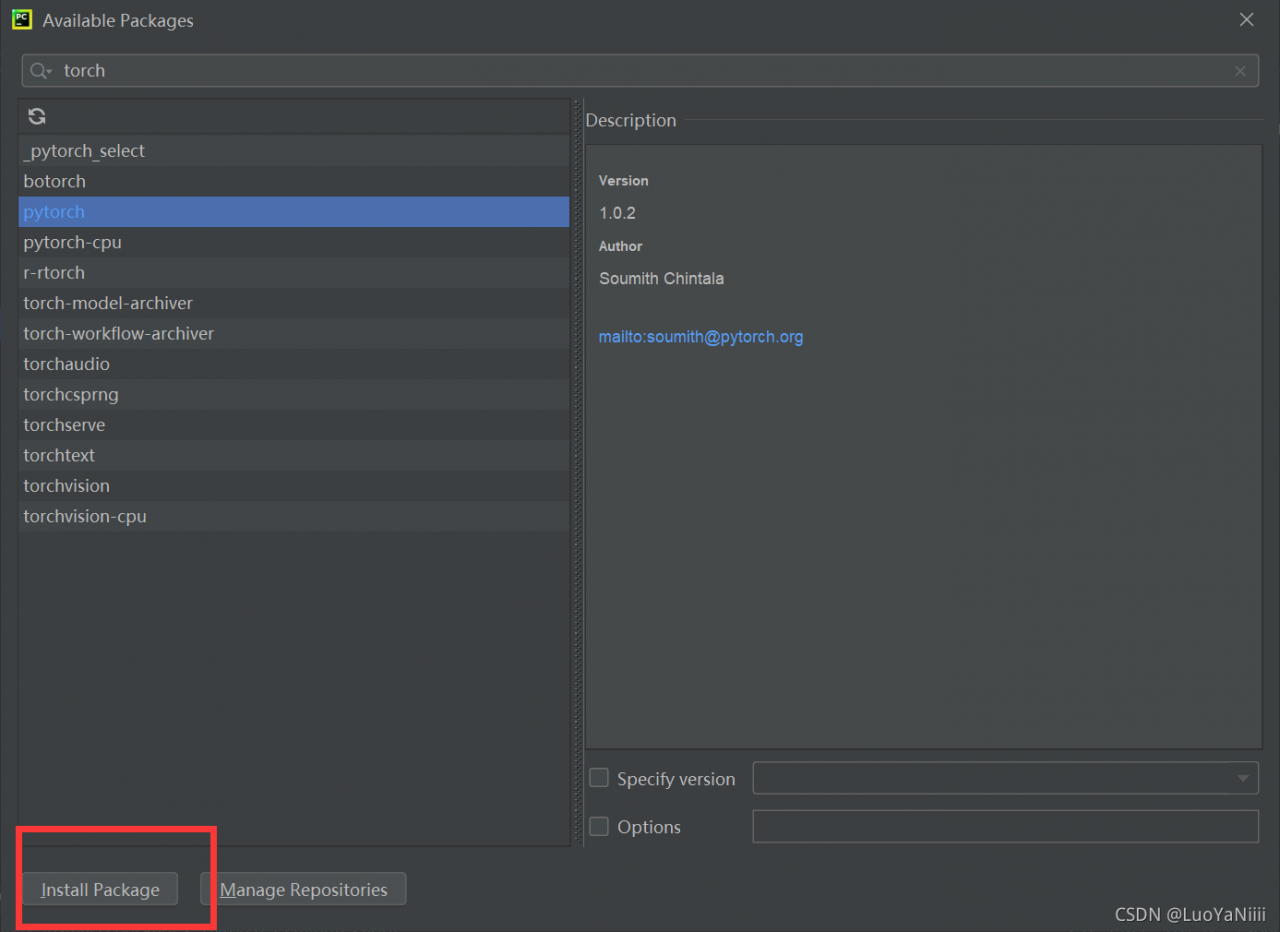
 Search torch
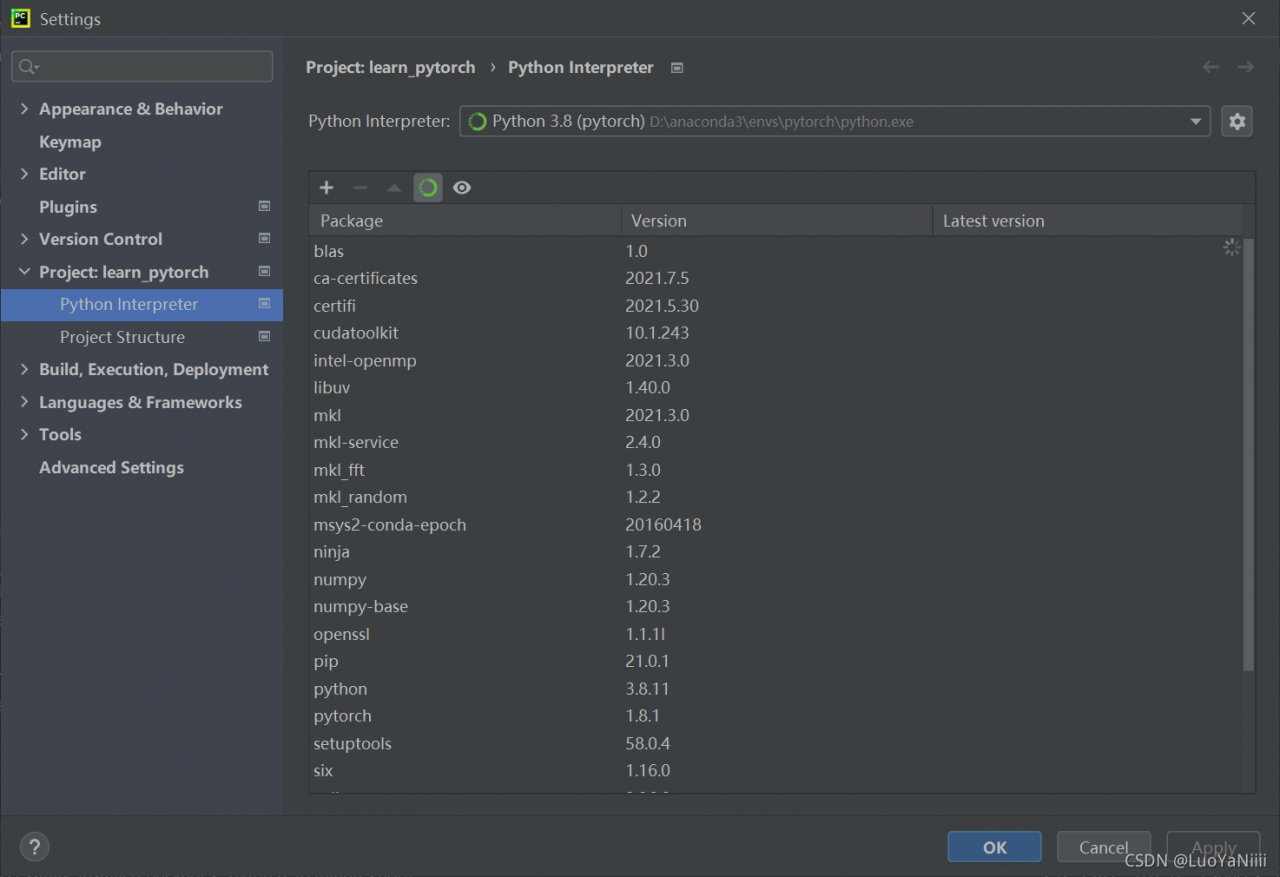
Search torch Choose install Package
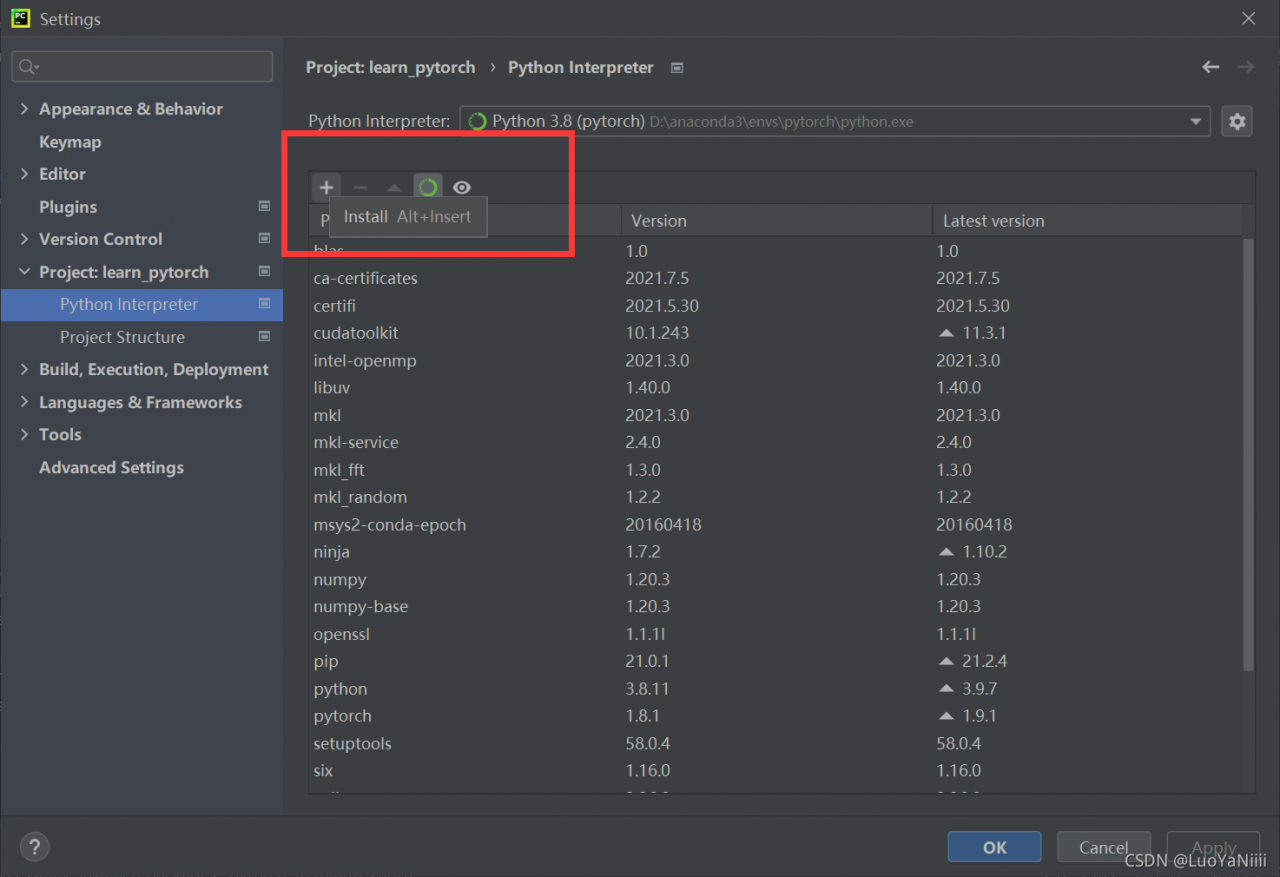
Choose install Package