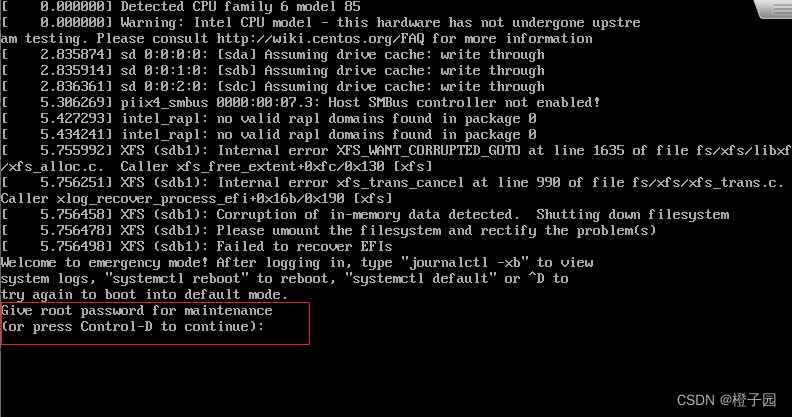
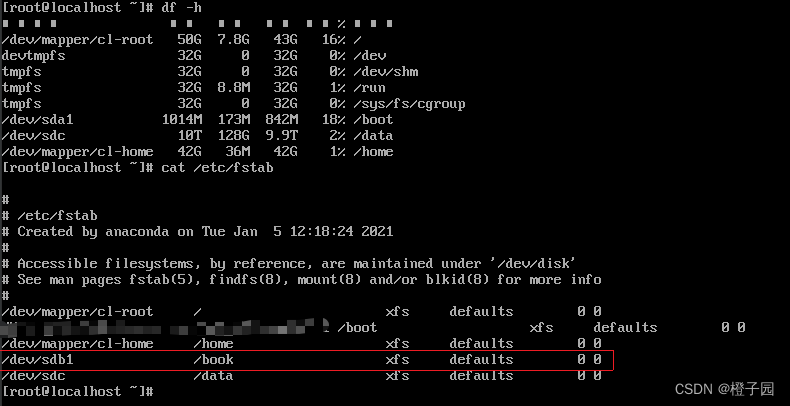
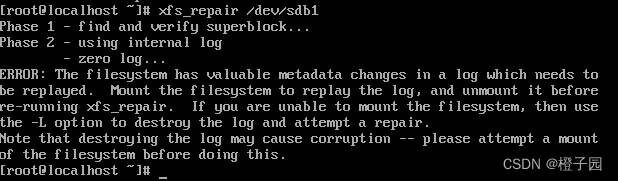
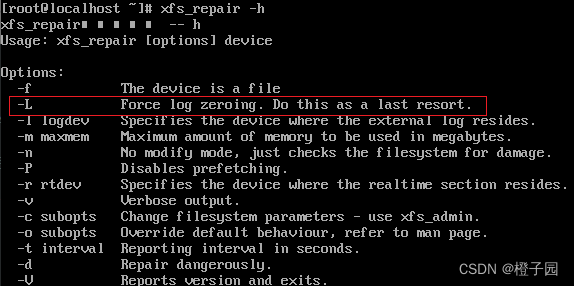
In case of the above error, generally speaking, the server cannot create the file. At this time, we can find the problem from two directions
1. The disk is full of blocks or inodes
1. The disk block is full. Check the command df -h
[root@S100900 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda3 35G 28G 5.6G 83% /
tmpfs 504M 0 504M 0% /dev/shm
/dev/vda1 194M 47M 138M 26% /boot
/dev/vdb1 325G 118G 192G 38% /home/wwwroot/vdb1data
2. Disk inode is full. Check the command df -i
[root@S1000900 ~]# df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/vda3 2289280 1628394 660886 72% /
tmpfs 128827 1 128826 1% /dev/shm
/dev/vda1 51200 44 51156 1% /boot
/dev/vdb1 21626880 21626880 0 100% /home/wwwroot/vdb1data
We found after comparison that the disk block occupied 38%, but the inode occupied 100%, it can be imagined that the disk fragmentation of small files are particularly large, we can go to the corresponding disk under the deletion of useless small files to solve the problem; we have to keep the following two ideas, of course, to solve the fundamental problem also need to buy mount more disks to solve;
Idea one: inode is full: delete useless small files as much as possible to release enough inode
Idea two: block full: delete as many useless large files as possible to free up enough blocks
2. Error: ENOSPC: no space left on device, watch
node project reactnative Error: Error: ENOSPC: no space left on device, watch
[root@iz2zeihk6kfcls5kwmqzj1z JFReactNativeProject]# npm start
> [email protected] start /app/jenkins_workspace/workspace/JFReactNativeProject
> react-native start
┌──────────────────────────────────────────────────────────────────────────────┐
│ │
│ Running Metro Bundler on port 8081. │
│ │
│ Keep Metro running while developing on any JS projects. Feel free to │
│ close this tab and run your own Metro instance if you prefer. │
│ │
│ https://github.com/facebook/react-native │
│ │
└──────────────────────────────────────────────────────────────────────────────┘
Looking for JS files in
/app/jenkins_workspace/workspace/JFReactNativeProject
Loading dependency graph...fs.js:1413
throw error;
^
Error: ENOSPC: no space left on device, watch '/app/jenkins_workspace/workspace/JFReactNativeProject/node_modules/.staging/react-native-ddd311e5/ReactAndroid/src/androidTest/java/com/facebook/react/testing/idledetection'
at FSWatcher.start (fs.js:1407:26)
at Object.fs.watch (fs.js:1444:11)
at NodeWatcher.watchdir (/app/jenkins_workspace/workspace/JFReactNativeProject/node_modules/[email protected]@sane/src/node_watcher.js:159:22)
at Walker.<anonymous> (/app/jenkins_workspace/workspace/JFReactNativeProject/node_modules/[email protected]@sane/src/common.js:109:31)
at Walker.emit (events.js:182:13)
at /app/jenkins_workspace/workspace/JFReactNativeProject/node_modules/[email protected]@walker/lib/walker.js:69:16
at go$readdir$cb (/app/jenkins_workspace/workspace/JFReactNativeProject/node_modules/[email protected]@graceful-fs/graceful-fs.js:187:14)
at FSReqWrap.oncomplete (fs.js:169:20)
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! [email protected] start: `react-native start`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the [email protected] start script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in:
npm ERR! /root/.npm/_logs/2019-09-25T06_57_58_754Z-debug.log
Solution:
Enospc means error no more hard disk space available
First, use df -hTto find that there is still a lot of disk space
Then find FSWatcher and Object.fs.watch field, and then view the contents related to the number of files that the system allows users to listen to
#Indicates the number of watches that can be added by the same user at the same time (watches are generally directory-specific and determine the number of directories that can be monitored by the same user at the same time)
[root@iz2zeihk6kfcls5kwmqzj1z JFReactNativeProject]# cat /proc/sys/fs/inotify/max_user_watches
8192
[root@iz2zeihk6kfcls5kwmqzj1z JFReactNativeProject]# echo 100000 > /proc/sys/fs/inotify/max_user_watches
[root@iz2zeihk6kfcls5kwmqzj1z JFReactNativeProject]# cat /proc/sys/fs/inotify/max_user_watches
100000
The permanent effective method is as follows: (this method is recommended)
vim /etc/sysctl.conf
fs.inotify.max_user_watches = 100000(The latter value can be adjusted according to the actual situation)
Just add and run /sbin/sysctl -p
Start validation:
Restart, normal