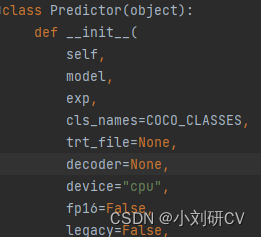
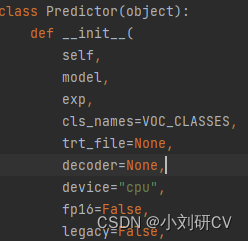
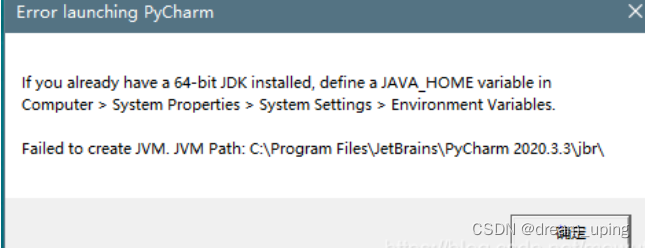
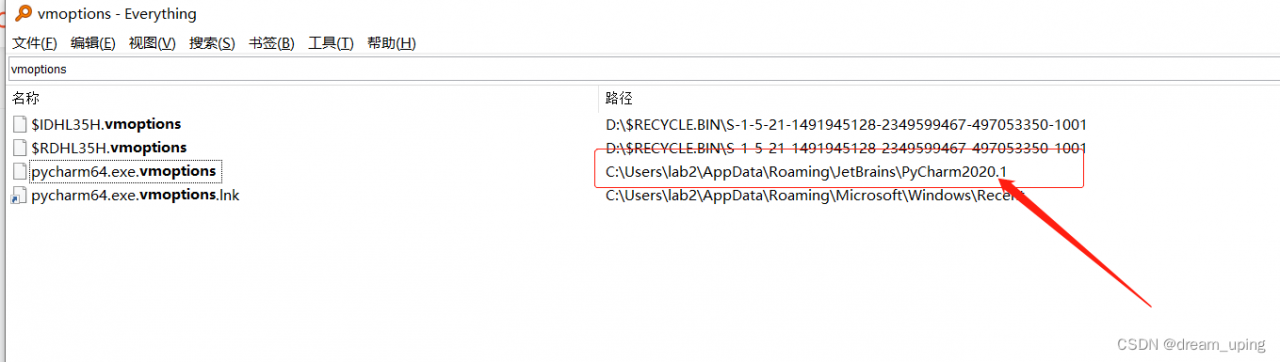
Project scenario:
This problem is encountered in distributed training,
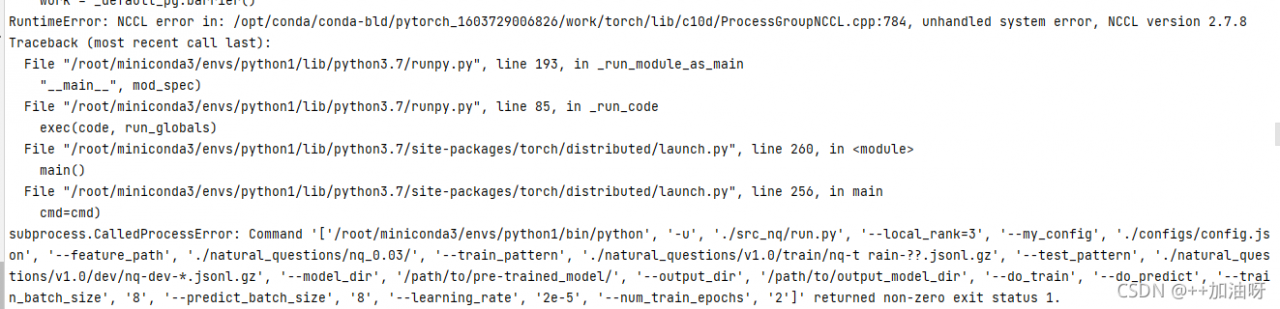
Problem description
Perhaps parallel operation is not started???(
Solution:
(1) First, check the server GPU related information. Enter the pytorch terminal to enter the code
python
torch.cuda.is_available()# to see if cuda is available.
torch.cuda.device_count()# to see the number of gpu's.
torch.cuda.get_device_name(0)# to see the gpu name, the device index starts from 0 by default.
torch.cuda.current_device()# return the current device index.
Ctrl+Z Exit
(2) cd enters the upper folder of the file to be run
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5 python -m torch.distributed.launch --nproc_per_node=6 #启动并行运算
Plus files to run and related configurations
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5 python -m torch.distributed.launch --nproc_per_node=6 src_nq/create_examples.py --vocab_file ./bert-base-uncased-vocab.txt \--input_pattern "./natural_questions/v1.0/train/nq-train-*.jsonl.gz" \--output_dir ./natural_questions/nq_0.03/\--do_lower_case \--num_threads 24 --include_unknowns 0.03 --max_seq_length 512 --doc_stride 128
Problem-solving!