Question
I’m executing the DWS Layer command DWS_load_member_When start.sh 2020-07-21 , an error is reported. This is all the error information
which: no hbase in (:/opt/install/jdk1.8.0_231/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/install/hadoop-2.9.2/bin:/opt/install/hadoop-2.9.2/sbin:/opt/install/flume-1.9.0/bin:/opt/install/hive-2.3.7/bin:/opt/install/datax/bin:/opt/install/spark-2.4.5/bin:/opt/install/spark-2.4.5/sbin:/root/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/install/hive-2.3.7/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/install/tez-0.9.2/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/install/hadoop-2.9.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/install/hive-2.3.7/lib/hive-common-2.3.7.jar!/hive-log4j2.properties Async: true
Query ID = root_20211014210413_76de217f-e97b-4435-adca-7e662260ab0b
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1634216554071_0002)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------
VERTICES: 00/00 [>>--------------------------] 0% ELAPSED TIME: 8.05 s
----------------------------------------------------------------------------------------------
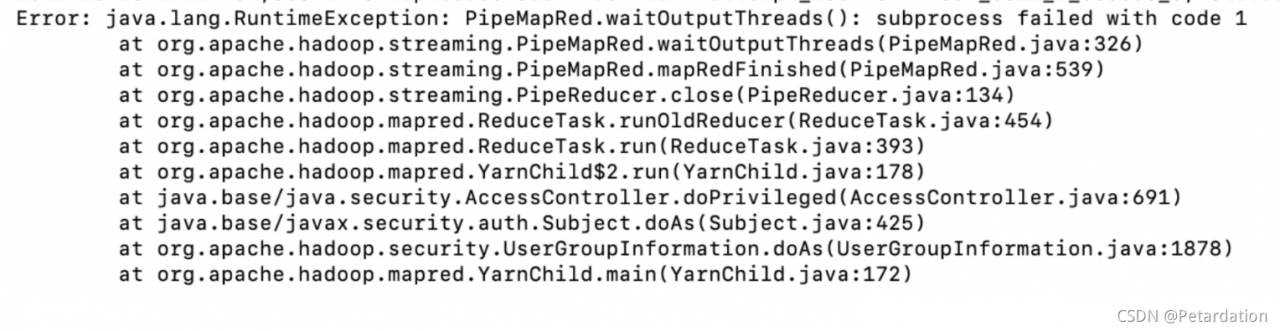
Status: Failed--------------------------------------------------------------------------------
Application application_1634216554071_0002 failed 2 times due to AM Container for appattempt_1634216554071_0002_000002 exited with exitCode: -103
Failing this attempt.Diagnostics: [2021-10-14 21:04:29.444]Container [pid=20544,containerID=container_1634216554071_0002_02_000001] is running beyond virtual memory limits. Current usage: 277.4 MB of 1 GB physical memory used; 2.7 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1634216554071_0002_02_000001 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 20544 20543 20544 20544 (bash) 0 0 115900416 304 /bin/bash -c /opt/install/jdk1.8.0_231/bin/java -Xmx819m -Djava.io.tmpdir=/opt/install/hadoop-2.9.2/data/tmp/nm-local-dir/usercache/root/appcache/application_1634216554071_0002/container_1634216554071_0002_02_000001/tmp -server -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -XX:+PrintGCDetails -verbose:gc -XX:+PrintGCTimeStamps -XX:+UseNUMA -XX:+UseParallelGC -Dlog4j.configuratorClass=org.apache.tez.common.TezLog4jConfigurator -Dlog4j.configuration=tez-container-log4j.properties -Dyarn.app.container.log.dir=/opt/install/hadoop-2.9.2/logs/userlogs/application_1634216554071_0002/container_1634216554071_0002_02_000001 -Dtez.root.logger=INFO,CLA -Dsun.nio.ch.bugLevel='' org.apache.tez.dag.app.DAGAppMaster --session 1>/opt/install/hadoop-2.9.2/logs/userlogs/application_1634216554071_0002/container_1634216554071_0002_02_000001/stdout 2>/opt/install/hadoop-2.9.2/logs/userlogs/application_1634216554071_0002/container_1634216554071_0002_02_000001/stderr
|- 20551 20544 20544 20544 (java) 367 99 2771484672 70721 /opt/install/jdk1.8.0_231/bin/java -Xmx819m -Djava.io.tmpdir=/opt/install/hadoop-2.9.2/data/tmp/nm-local-dir/usercache/root/appcache/application_1634216554071_0002/container_1634216554071_0002_02_000001/tmp -server -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -XX:+PrintGCDetails -verbose:gc -XX:+PrintGCTimeStamps -XX:+UseNUMA -XX:+UseParallelGC -Dlog4j.configuratorClass=org.apache.tez.common.TezLog4jConfigurator -Dlog4j.configuration=tez-container-log4j.properties -Dyarn.app.container.log.dir=/opt/install/hadoop-2.9.2/logs/userlogs/application_1634216554071_0002/container_1634216554071_0002_02_000001 -Dtez.root.logger=INFO,CLA -Dsun.nio.ch.bugLevel= org.apache.tez.dag.app.DAGAppMaster --session
[2021-10-14 21:04:29.458]Container killed on request. Exit code is 143
[2021-10-14 21:04:29.481]Container exited with a non-zero exit code 143.
For more detailed output, check the application tracking page: http://hadoop1:8088/cluster/app/application_1634216554071_0002 Then click on links to logs of each attempt.
. Failing the application.
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.tez.TezTask. Application application_1634216554071_0002 failed 2 times due to AM Container for appattempt_1634216554071_0002_000002 exited with exitCode: -103
Failing this attempt.Diagnostics: [2021-10-14 21:04:29.444]Container [pid=20544,containerID=container_1634216554071_0002_02_000001] is running beyond virtual memory limits. Current usage: 277.4 MB of 1 GB physical memory used; 2.7 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1634216554071_0002_02_000001 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 20544 20543 20544 20544 (bash) 0 0 115900416 304 /bin/bash -c /opt/install/jdk1.8.0_231/bin/java -Xmx819m -Djava.io.tmpdir=/opt/install/hadoop-2.9.2/data/tmp/nm-local-dir/usercache/root/appcache/application_1634216554071_0002/container_1634216554071_0002_02_000001/tmp -server -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -XX:+PrintGCDetails -verbose:gc -XX:+PrintGCTimeStamps -XX:+UseNUMA -XX:+UseParallelGC -Dlog4j.configuratorClass=org.apache.tez.common.TezLog4jConfigurator -Dlog4j.configuration=tez-container-log4j.properties -Dyarn.app.container.log.dir=/opt/install/hadoop-2.9.2/logs/userlogs/application_1634216554071_0002/container_1634216554071_0002_02_000001 -Dtez.root.logger=INFO,CLA -Dsun.nio.ch.bugLevel='' org.apache.tez.dag.app.DAGAppMaster --session 1>/opt/install/hadoop-2.9.2/logs/userlogs/application_1634216554071_0002/container_1634216554071_0002_02_000001/stdout 2>/opt/install/hadoop-2.9.2/logs/userlogs/application_1634216554071_0002/container_1634216554071_0002_02_000001/stderr
|- 20551 20544 20544 20544 (java) 367 99 2771484672 70721 /opt/install/jdk1.8.0_231/bin/java -Xmx819m -Djava.io.tmpdir=/opt/install/hadoop-2.9.2/data/tmp/nm-local-dir/usercache/root/appcache/application_1634216554071_0002/container_1634216554071_0002_02_000001/tmp -server -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -XX:+PrintGCDetails -verbose:gc -XX:+PrintGCTimeStamps -XX:+UseNUMA -XX:+UseParallelGC -Dlog4j.configuratorClass=org.apache.tez.common.TezLog4jConfigurator -Dlog4j.configuration=tez-container-log4j.properties -Dyarn.app.container.log.dir=/opt/install/hadoop-2.9.2/logs/userlogs/application_1634216554071_0002/container_1634216554071_0002_02_000001 -Dtez.root.logger=INFO,CLA -Dsun.nio.ch.bugLevel= org.apache.tez.dag.app.DAGAppMaster --session
[2021-10-14 21:04:29.458]Container killed on request. Exit code is 143
[2021-10-14 21:04:29.481]Container exited with a non-zero exit code 143.
For more detailed output, check the application tracking page: http://hadoop1:8088/cluster/app/application_1634216554071_0002 Then click on links to logs of each attempt.
. Failing the application.
It’s taken off to interpret this error message.
The logs at the beginning of slf4j before line 9 do not need to be concerned, but only indicate that some unimpeded packages are missing;
Then is the implementation of the task I submitted this time
Logging initialized using configuration in jar:file:/opt/install/hive-2.3.7/lib/hive-common-2.3.7.jar!/hive-log4j2.properties Async: true
Query ID = root_20211014210413_76de217f-e97b-4435-adca-7e662260ab0b
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1634216554071_0002)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------
VERTICES: 00/00 [>>--------------------------] 0% ELAPSED TIME: 8.05 s
----------------------------------------------------------------------------------------------
Tell me again that the task execution failed, and the program exit number is - 103 ①
Status: Failed--------------------------------------------------------------------------------
Application application_1634216554071_0002 failed 2 times due to AM Container for appattempt_1634216554071_0002_000002 exited with exitCode: -103
Failing this attempt.Diagnostics: [2021-10-14 21:04:29.444]Container [pid=20544,containerID=container_1634216554071_0002_02_000001] is running beyond virtual memory limits. Current usage: 277.4 MB of 1 GB physical memory used; 2.7 GB of 2.1 GB virtual memory used. Killing container.
Followed by a list of reasons: container [attribute describing container] is running beyond virtual memory limits. Current usage: 277.4 MB of 1 GB physical memory used; 2.7 GB of 2.1 GB virtual memory used. Killing container ② means that my running task (actually container, which is easy to understand here) exceeds the limit of virtual memory. The usage is 1g of physical memory. My task uses 277.4m, which is OK. It’s not too much, but I use 2.7g of virtual memory, which is obviously unreasonable, So nodemanager killed it.
The last part of the log, which is also the most informative part, will tell us where the problem will be recorded
Dump of the process-tree for container_1634216554071_0002_02_000001 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- ...
|- ...
[2021-10-14 21:04:29.458]Container killed on request. Exit code is 143
[2021-10-14 21:04:29.481]Container exited with a non-zero exit code 143.
For more detailed output, check the application tracking page: http://hadoop1:8088/cluster/app/application_1634216554071_0002 Then click on links to logs of each attempt.
. Failing the application.
Focus on the penultimate sentence: for more detailed output, check the application tracking page: http://hadoop1:8088/cluster/app/application_1634216554071_0002 then click on links to logs of each attempt. http://hadoop1:8088/cluster/app/application_1634216554071_0002 find it. ③
Solution:
The old idea is that there are problems in resources, and there are only two directions: 1. Too heavy tasks and 2. Too few resources. In this case, the task is not heavy. It can also be seen from the occupied physical memory that the memory I allocate is more than enough to complete the task. The problem lies in the virtual memory. Then I have two ideas about the “virtual memory”. First, what configuration can intervene? Which configuration is it?
Next time you encounter this kind of problem, you can think about these points:
Cancel the check of virtual memory
yarn-site.xmlSet in or program yarn.nodemanager.vmem-check-enabledasfalse
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers.</description>
</property>
In addition to virtual memory super, there may be a super-physical memory, also can be set to check physical memory yarn.nodemanager.pmem-check-enabledis false, personally think that this approach is not very good, if a program has a memory leak and other issues, cancel the check, it could lead to cluster collapse.
Increase mapreduce.map.memory.mbormapreduce.reduce.memory.mb
This method should be given priority. This method can not only solve the virtual memory, perhaps most of the time the physical memory is not enough, this method is just suitable.
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
<description>maps</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
<description>reduces</description>
</property>
Properly increase yarn.nodemanager.vmem-pmem-ratiothe size, one physical memory increases multiple virtual memory, but this parameter should not be too outrageous, the essence is to deal with mapreduce.reduce.memory.db* yarn.nodemanager.vmem-pmem-ratio.
If the memory occupied by the task is too ridiculous, more consideration should be whether the program has a memory leak, whether there is data skew, etc., and the program should be given priority to solve such problems.
 under this directory
under this directory