1. Check whether the appropriate version of torch is used
print(torch.__version__) # 1.9.1+cu111
print(torch.version.cuda) # 11.1
print(torch.backends.cudnn.version()) # 8005
print(torch.cuda.current_device()) # 0
print(torch.cuda.is_available()) # TRUE
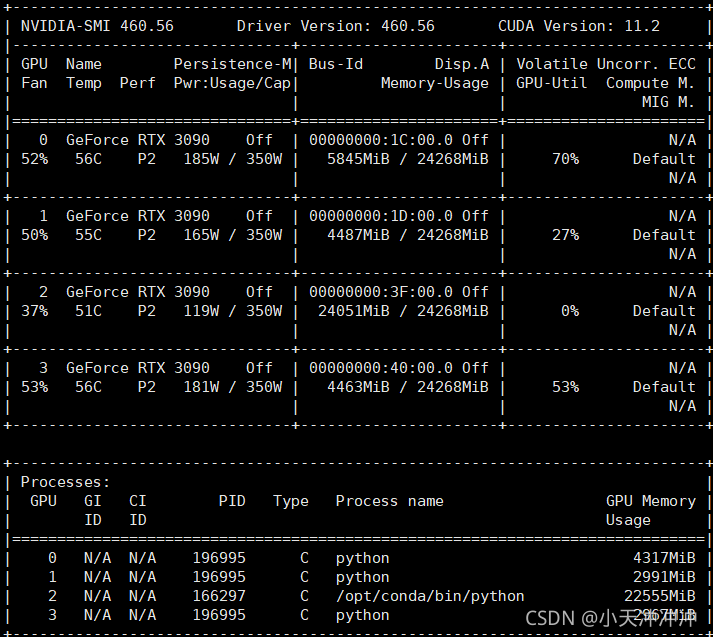
2. Check whether the video memory is insufficient, try to modify the batch size of the training, and it still cannot be solved when it is modified to the minimum, and then use the following command to monitor the video memory occupation in real time
watch -n 0.5 nvidia-smi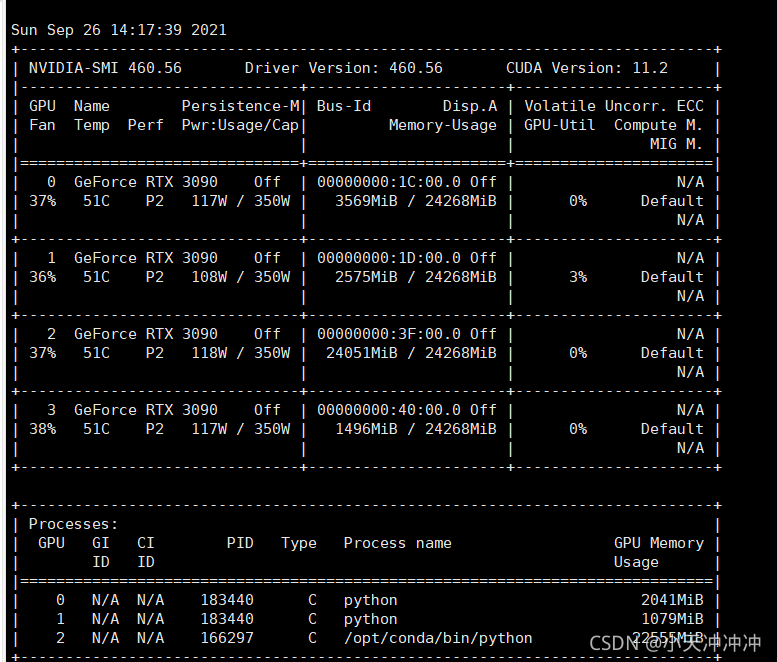
When the program is not called, the display memory is occupied
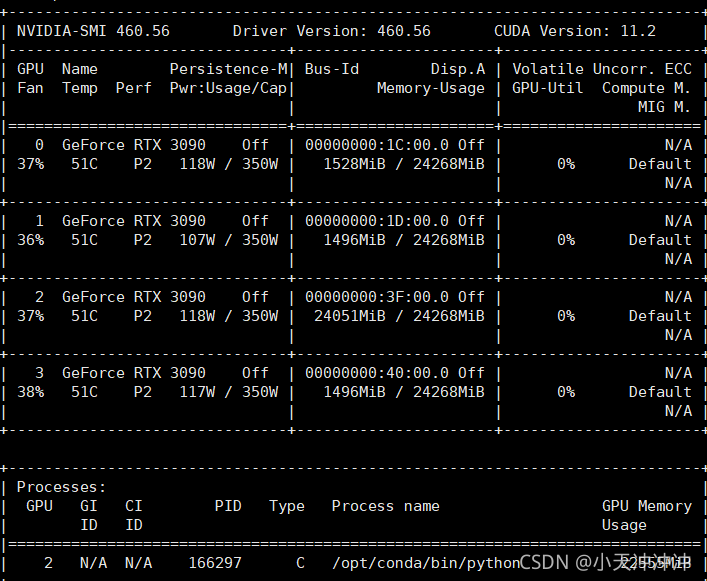
Therefore, the problem is that the program specifies to use four GPUs. There is no problem when calling the first two resources, but the third block is occupied by the programs of other small partners, so an error is reported.
3. Specify the GPU to use
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu") # cuda Specifies the GPU device to be used
model = torch.nn.DataParallel(model, device_ids=[0, 1, 3]) # Specify the device number to be used for multi-GPU parallel processingSo you can run happily