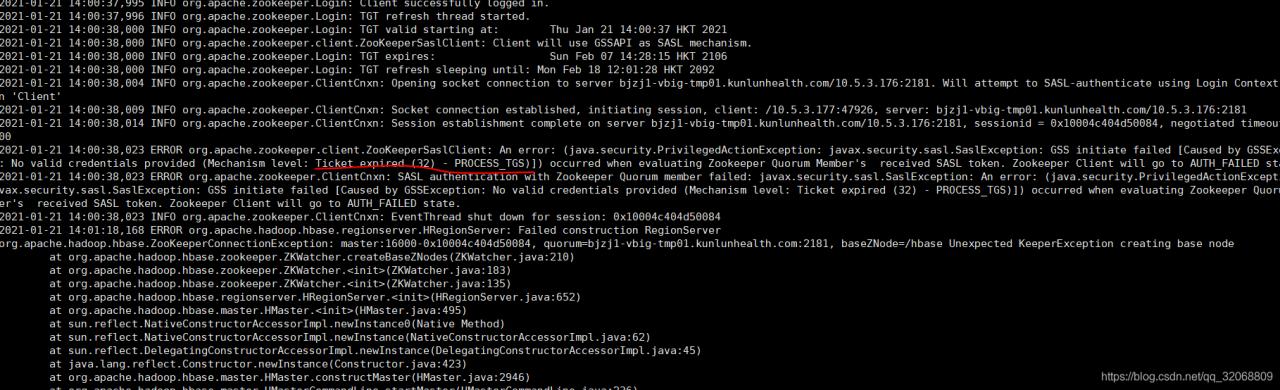
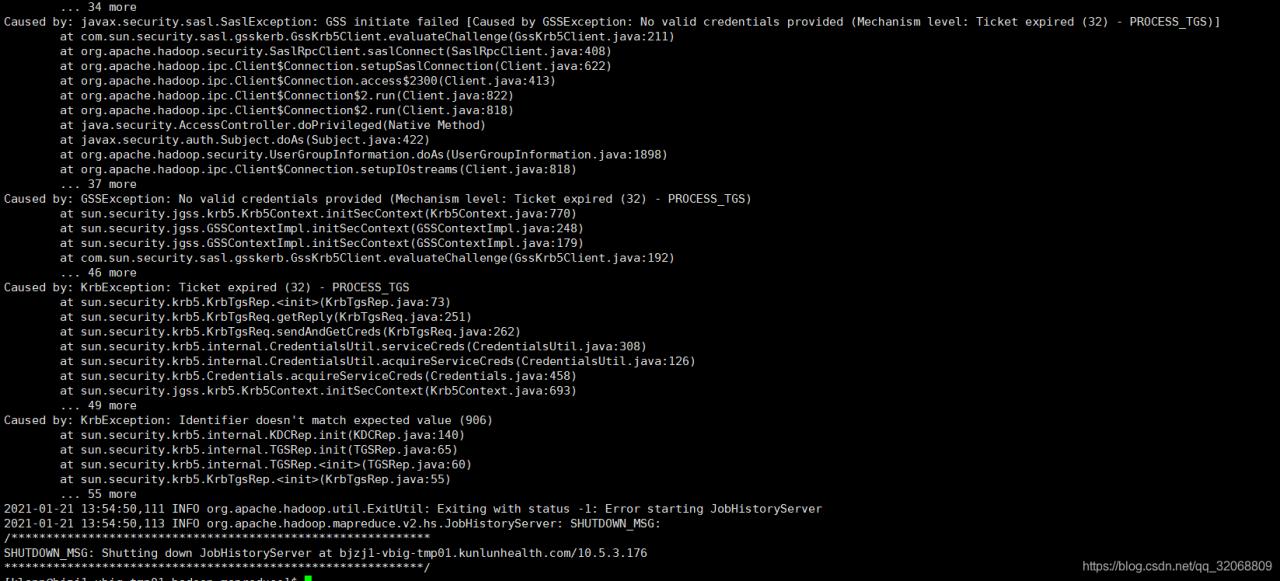
[error 1]:
java.lang.RuntimeException: HMaster Aborted
at org.apache.hadoop.hbase.master.HMasterCommandLine.startMaster(HMasterCommandLine.java:261)
at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:149)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:149)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:2971)
2021-08-26 12:25:35,269 INFO [main-EventThread] zookeeper.ClientCnxn: EventThread shut down for session: 0x37b80a4f6560008
[attempt 1]: delete the HBase node under ZK
but not solve my problem
[attempt 2]: reinstall HBase
but not solve my problem
[attempt 3]: turn off HDFS security mode
hadoop dfsadmin -safemode leave
Still can’t solve my problem
[try 4]: check zookeeper. You can punch in spark normally or add new nodes. No problem.
Turn up and report an error
[error 2]:
master.HMaster: Failed to become active master
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category READ is not supported in state standby. Visit https://s.apache.org/sbnn-error
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:108)
at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:2044)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1409)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getFileInfo(FSNamesystem.java:2961)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getFileInfo(NameNodeRpcServer.java:1160)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getFileInfo(ClientNamenodeProtocolServerSideTranslatorPB.java:880)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:507)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1034)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:1003)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:931)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1926)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2854)
Here’s the point: an error is reported that my master failed to become an hmaster. The reason is: operation category read is not supported in state standby. That is, the read operation fails because it is in the standby state. Check the NN1 state at this time
# hdfs haadmin -getServiceState nn1
Sure enough, standby

[solution 1]:
manual activation
hdfs haadmin -transitionToActive --forcemanual nn1
Kill all HBase processes, restart, JPS view, access port
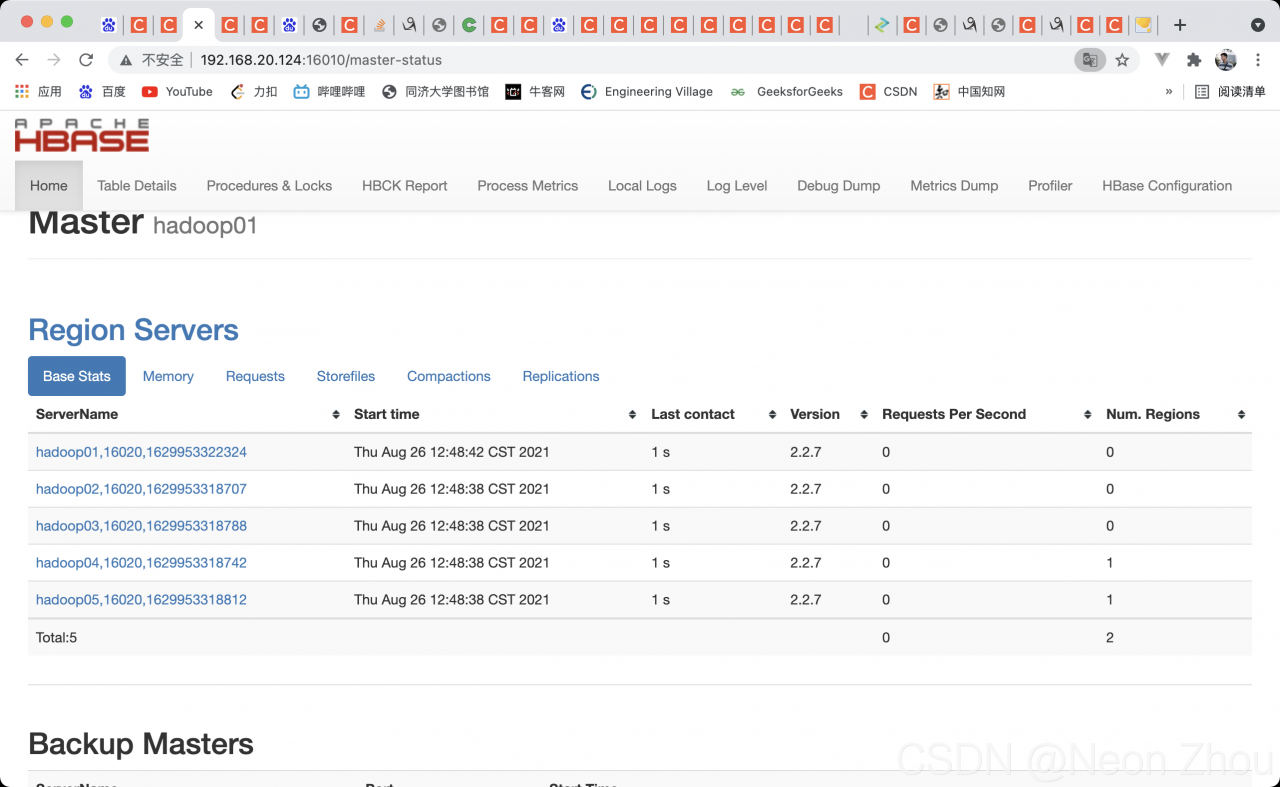
Bravo!!!
It’s been changed for a few hours. It’s finally good. The reason is that I forgot the correct startup sequence
zookeeper —— & gt; hadoop——-> HBase
every time I start Hadoop first, I waste a long time. I hope I can help you.