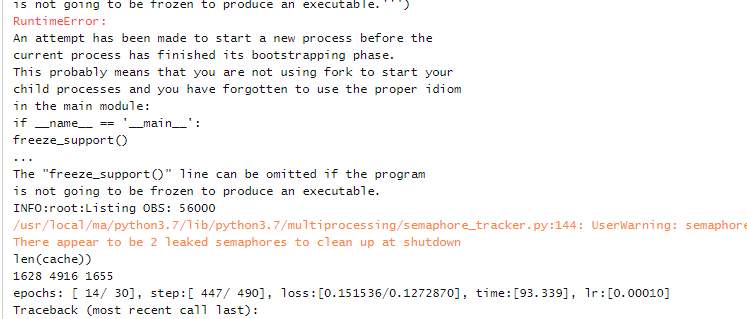
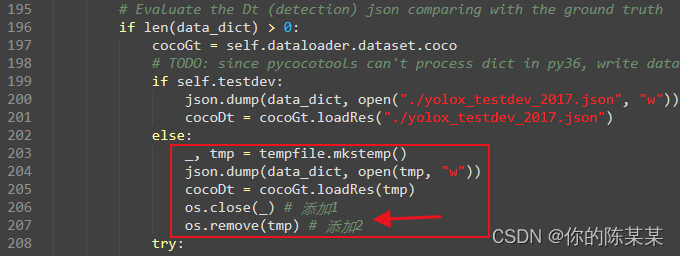
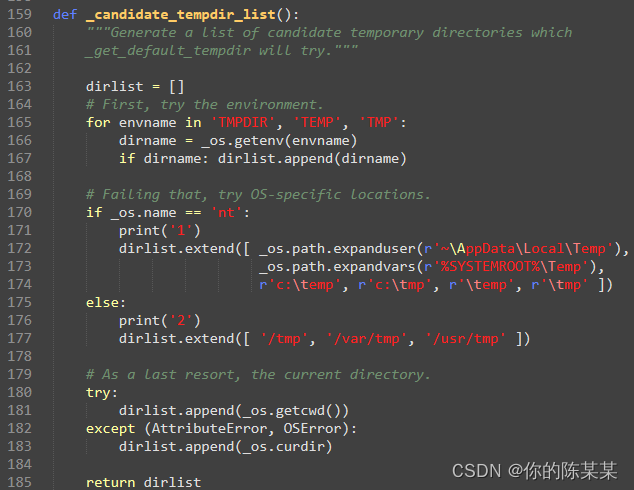
Vitis AI reports an error when generating a quantitative model
Traceback (most recent call last):
File "generate_model.py", line 191, in <module>
run_main()
File "generate_model.py", line 185, in run_main
quantize(args.build_dir,args.quant_mode,args.batchsize)
File "generate_model.py", line 160, in quantize
quantizer = torch_quantizer(quant_mode, new_model, (rand_in), output_dir=quant_model)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/pytorch_nndct/apis.py", line 77, in __init__
custom_quant_ops = custom_quant_ops)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/pytorch_nndct/qproc/base.py", line 122, in __init__
device=device)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/pytorch_nndct/qproc/utils.py", line 175, in prepare_quantizable_module
graph = parse_module(module, input_args)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/pytorch_nndct/qproc/utils.py", line 78, in parse_module
module, input_args)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/pytorch_nndct/parse/parser.py", line 68, in __call__
raw_graph, raw_params = graph_handler.build_torch_graph(graph_name, module, input_args)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/pytorch_nndct/parse/trace_helper.py", line 37, in build_torch_graph
fw_graph, params = self._trace_graph_from_model(input_args, train)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/pytorch_nndct/parse/trace_helper.py", line 61, in _trace_graph_from_model
train)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/pytorch_nndct/utils/jit_utils.py", line 235, in trace_and_get_graph_from_model
graph, torch_out = _get_trace_graph()(model, args)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/torch/jit/__init__.py", line 277, in _get_trace_graph
outs = ONNXTracedModule(f, _force_outplace, return_inputs, _return_inputs_states)(*args, **kwargs)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 532, in __call__
result = self.forward(*input, **kwargs)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/torch/jit/__init__.py", line 360, in forward
self._force_outplace,
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/torch/jit/__init__.py", line 347, in wrapper
outs.append(self.inner(*trace_inputs))
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 530, in __call__
result = self._slow_forward(*input, **kwargs)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 516, in _slow_forward
result = self.forward(*input, **kwargs)
File "/opt/vitis_ai/conda/envs/vitis-ai-pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 96, in forward
raise NotImplementedError
NotImplementedError
The possible reasons for the above problems are:
no forward implementation is added to the model