today’s sayings: knowledge lies in sharing, give rose, hand has fragrance.
problem description:
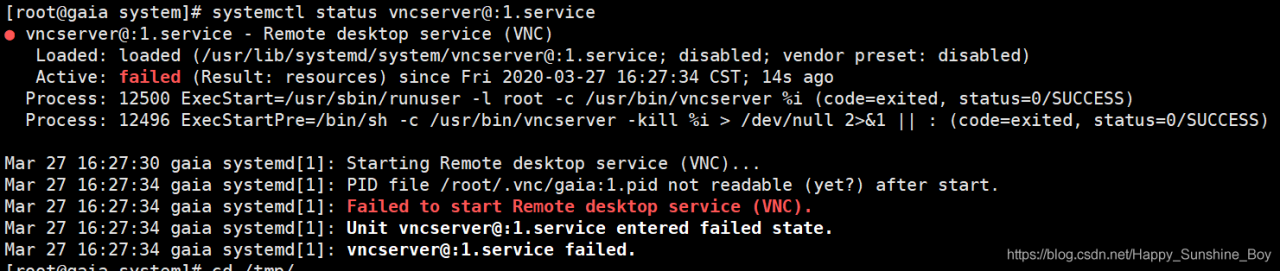
computer suddenly freezes, that is, VirtualBox is closed abnormally. After restarting the computer, opening VirtualBox presents the following error:
Failed to acquire the VirtualBox COM object.
The application will now terminate.
Details:
Failed to acquire the VirtualBox COM object.
The application will now terminate.
Document is empty.
Location: ‘C:\Users\Fred\.VirtualBox\VirtualBox.xml’, line 1 (0), column 1.
F: \ tinderbox, win – 5.1 \ SRC \ VBox, Main \ SRC – server \ VirtualBoxImpl CPP [550] (long __cdecl VirtualBox: : init (void)).
| Result Code: |
E_FAIL (0x80004005) |
| Component: |
VirtualBoxWrap |
| Interface: |
IVirtualBox {0169423f-46b4-cde9-91af-1e9d5b6cd945} |
| Callee: |
IVirtualBoxClient {d2937a8e-cb8d-4382-90ba-b7da78a74573} |
search on the Internet did not find a good solution, mostly said uninstall. Compelled by the thirst for solving the problem, I couldn’t help myself. Fortunately, it was done with the sixth sense of a codebreaker. In order to serve as a reference for the companion who encountered the same problem and to facilitate their own reference, I hereby make a record. Without further ado, go straight to the dry goods.
solution:
‘C:\Users\Fred\.virtualbox \ virtualbox.xml ‘, line 1 (0), column 1
I don’t know exactly what the virtualbox.xml file does, but if VirtualBox is enabled properly, it should be a management file or log. Virtualbox. XML file. If you restart VirtualBox, you can open it, but if you open it, there is nothing left. Like this,
click on the menu bar: Machine-> Add
found before the VirtualBox configuration folder, that is, the folder with the suffixes. Vbox and. Vdi, I added
under C:\Users\Fred\VirtualBox VMs\vm
vm. Vbox file (my vm name is vm, you want to add the suffix . Vbox file), So easy! You will be configured before the virtual machine added to the normal use!