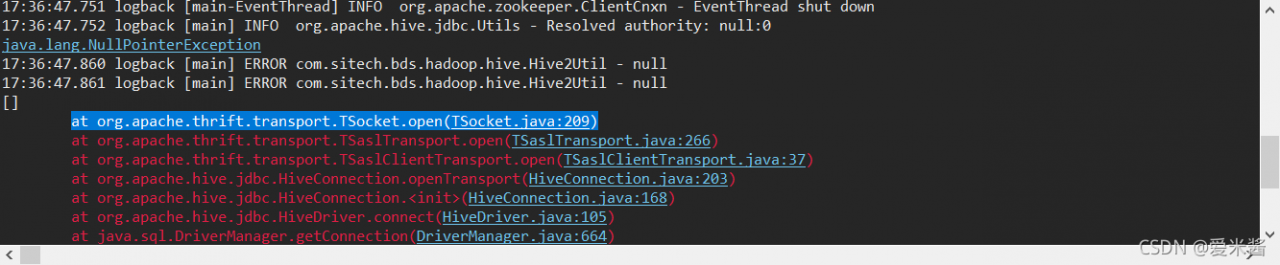
Error:
ERROR : Ended Job = job_1631679144970_1574917 with errors
ERROR : Error during job, obtaining debugging information...
ERROR :
Task with the most failures(4):
-----
Task ID:
task_1631679144970_1574917_m_000158
URL:
http://0.0.0.0:8088/taskdetails.jsp?jobid=job_1631679144970_1574917&tipid=task_1631679144970_1574917_m_000158
-----
Diagnostic Messages for this Task:
Container [pid=18442,containerID=container_1631679144970_1574917_01_003316] is running beyond physical memory limits. Current usage: 4.1 GB of 4 GB physical memory used; 5.8 GB of 80 GB virtual memory used. Killing container.
I checked the written information on the Internet and said it was
java.lang.outofmemoryerror: Java heap space. The reason is that the memory space of the namenode is not enough and the JVM is not enough. It is caused by the start of a new job
the solution is to set the local mode
set hive.exec.mode.local.auto=true;
The specific error reported by me is running beyond physical memory limits. Current usage: 4.1 GB of 4 GB physical memory used
the physical memory size is insufficient
Solution:
set mapreduce.map.memory.mb=8192;
set mapreduce.reduce.memory.mb=8192;