Argument interpolation should be of type InterpolationMode instead of int.
-
- provide
from torchvision.transforms import InterpolationMode
Image.BICUBIC
-
- Replace as
InterpolationMode.BICUBIC
Argument interpolation should be of type InterpolationMode instead of int.
from torchvision.transforms import InterpolationMode
Image.BICUBIC
InterpolationMode.BICUBIC
MobaXterm error cuda:out of memory
When using mobaxterm training model, the cuda:out of In addition to the fact that the conventional video memory is too small and the value of subdivisions needs to be adjusted, there may also be a literal meaning that the storage space is insufficient and the data set is too large. At this time, you only need to reduce the capacity of the data set and then reduce it.
CONDA install pydot
The problem of numpy version.
just reduce numpy to 1.19.2.
see here for details
Version keras nightly = 2.5.0.dev2021032900
Error information
from keras.optimizers import Adam
ImportError: cannot import name 'Adam' from 'keras.optimizers'
Solution
error code
from keras.optimizers import Adam
opt = Adam(lr=lr, decay=lr/epochs)
modify
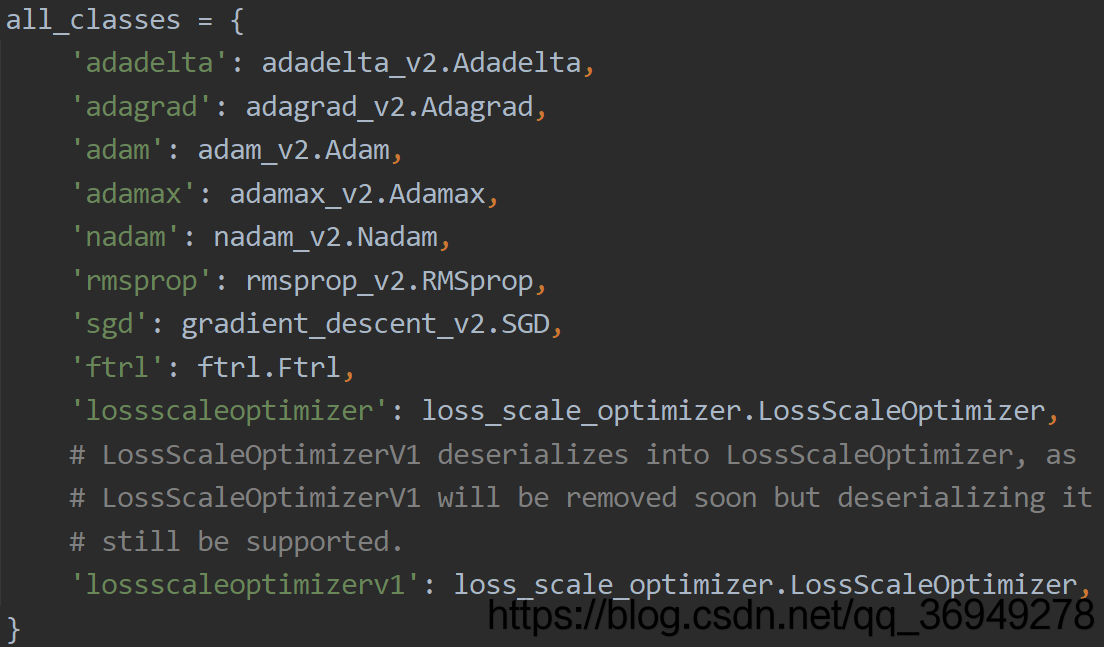
from keras.optimizers import adam_v2
opt = adam_v2.Adam(learning_rate=lr, decay=lr/epochs)
reason
After the keras library is updated, the package cannot be imported in the original way. Open the optimizers.py source code and find the following two key codes. You can see that Adam import has changed, so it is modified as above.
from keras.optimizer_v2 import adam as adam_v2
'adam': adam_v2.Adam,
Keras’s model defines metric or loss,
there is no problem when saving to H5, but when using load_ When importing the model, an error will be reported:
unknown metric function: HammingScore. Please ensure this object is passed to the
custom_ objectsargument.
This is because the custom parameters are not passed in. There are two solutions:
compile = false directly
model = keras.models.load_model('model.h5', compile = False)
If you need further training or modification, add your own metrics code and compile it again
model.compile(loss='binary_crossentropy',
optimizer=Ada,
metrics=[HammingScore]) # 这里HammingScore是我自定义的metric
Custom as a key value_ objects
model = keras.models.load_model('model.h5', custom_objects={'HammingScore': HammingScore} )
Note that the key value should be consistent
Recently, I encountered some mistakes as shown in the title when doing deep learning classification, but I don’t know how to modify them. Finally, after exploration, I successfully solved them
the problems and solutions are reported directly below.
Error 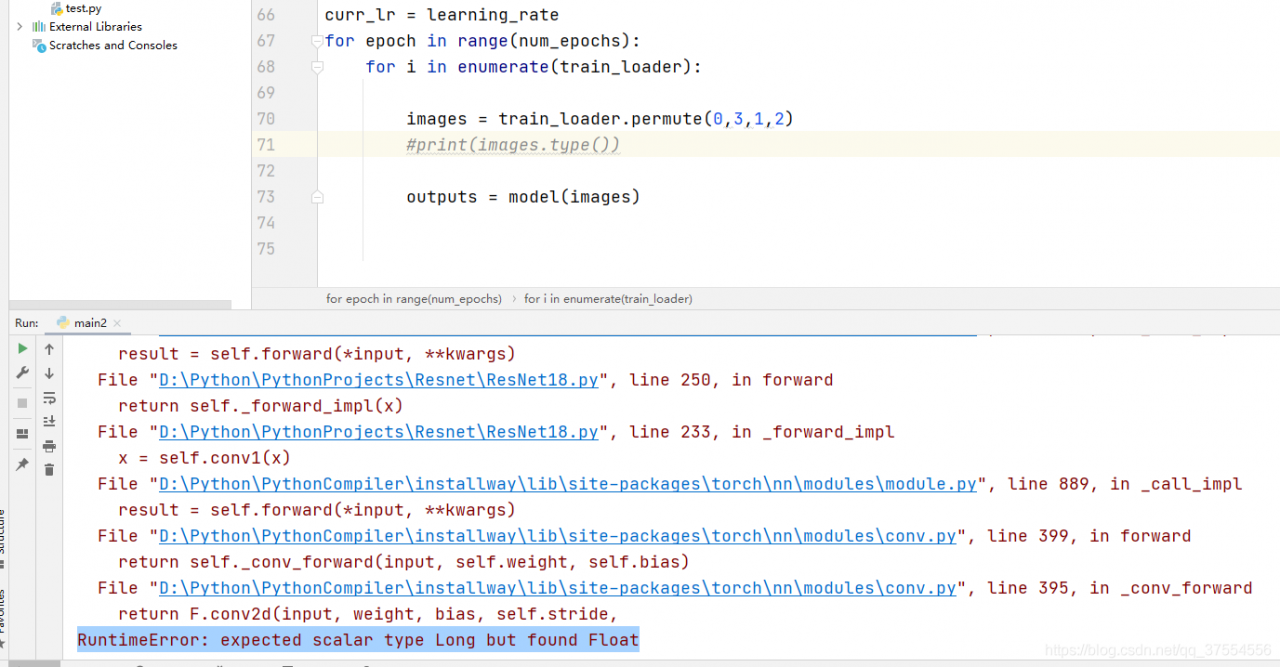

Solution
In practice, the label of classification should be long, and the image should be float32
therefore, modifying the data type will succeed
CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://repo.anaconda.com/pkgs/main/win-64/repodata.json>
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
Solution:
Win + R
then find

and replace it with
channels:
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
show_channel_urls: true
ssl_verify: false
This error is usually caused by the version of mmcv
just click in one by one according to the following error prompt to find utils.py file:
change the code in the circle below:
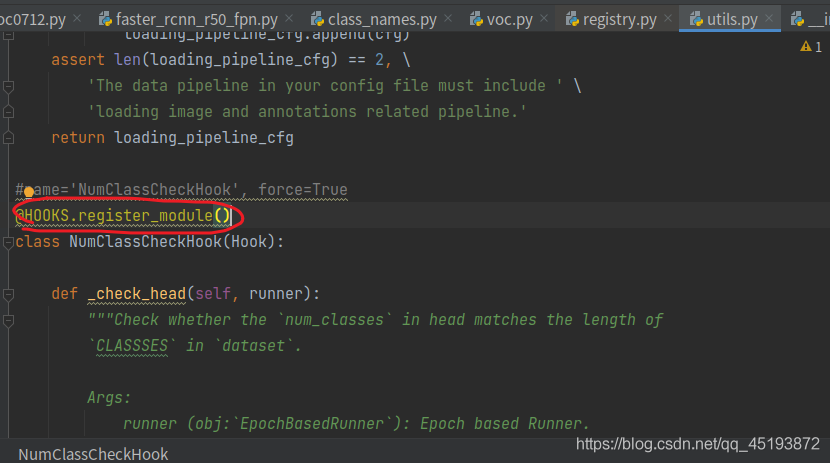
add in brackets:
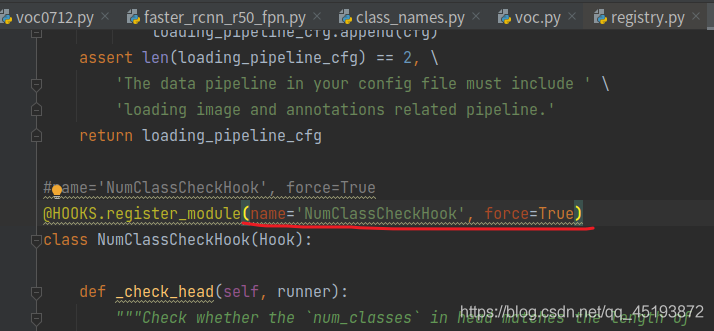
finally, it can run successfully.
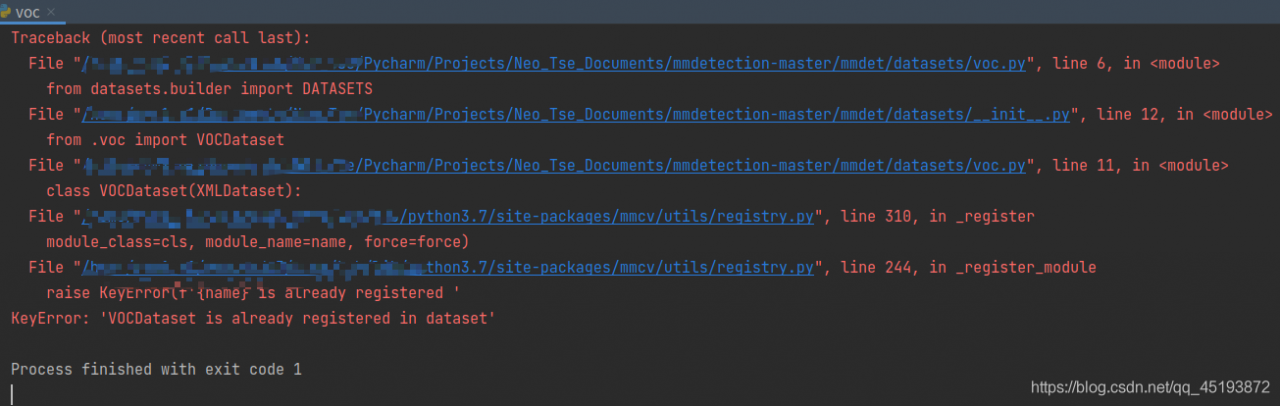
Similar questions:
keyerror: ‘XXX is already registered in xxx’
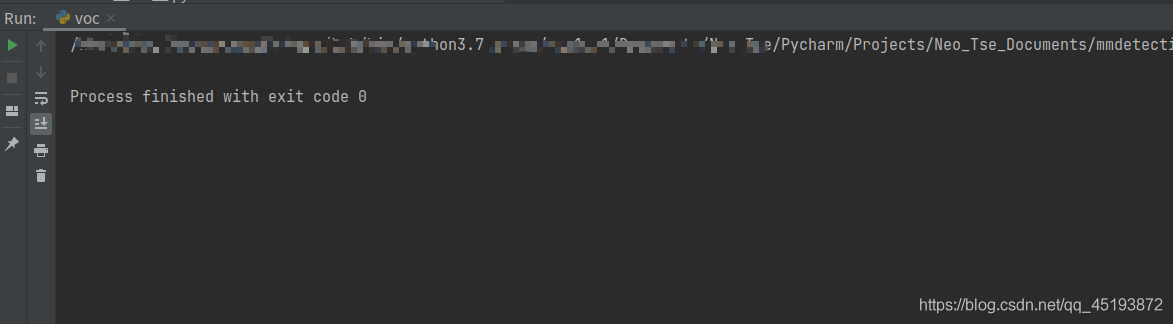
Results: it runs perfectly
When training the model in vscode, the following errors appear:
CUDA runtime error (38): no CUDA capable device is detected at/Torch/aten/SRC/THC/thcgeneral cpp:51
The reason is that CUDA is not selected correctly, so you need to check how many graphics cards you have first:
Enter Python in terminal; Enter the following code
import torch
print(torch.cuda.device_count()) #Number of available GPUs
View CUDA version
nvcc --version # Check your own CUDA version
I have two graphics cards in my library. Choose one from 0 or 1 and write it before
model = torch.nn.dataparallel (net). Cuda()
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
model = torch.nn.DataParallel(net).cuda()
Problem solving.
Method 1
torch.backends.cudnn.enabled = True
torch.backends.cudnn.benchmark = TruePrinciple:
Cundnn follows the following criteria:
Method 2
Tensor calculation should be written as follows:
train_loss += loss.item()Command line
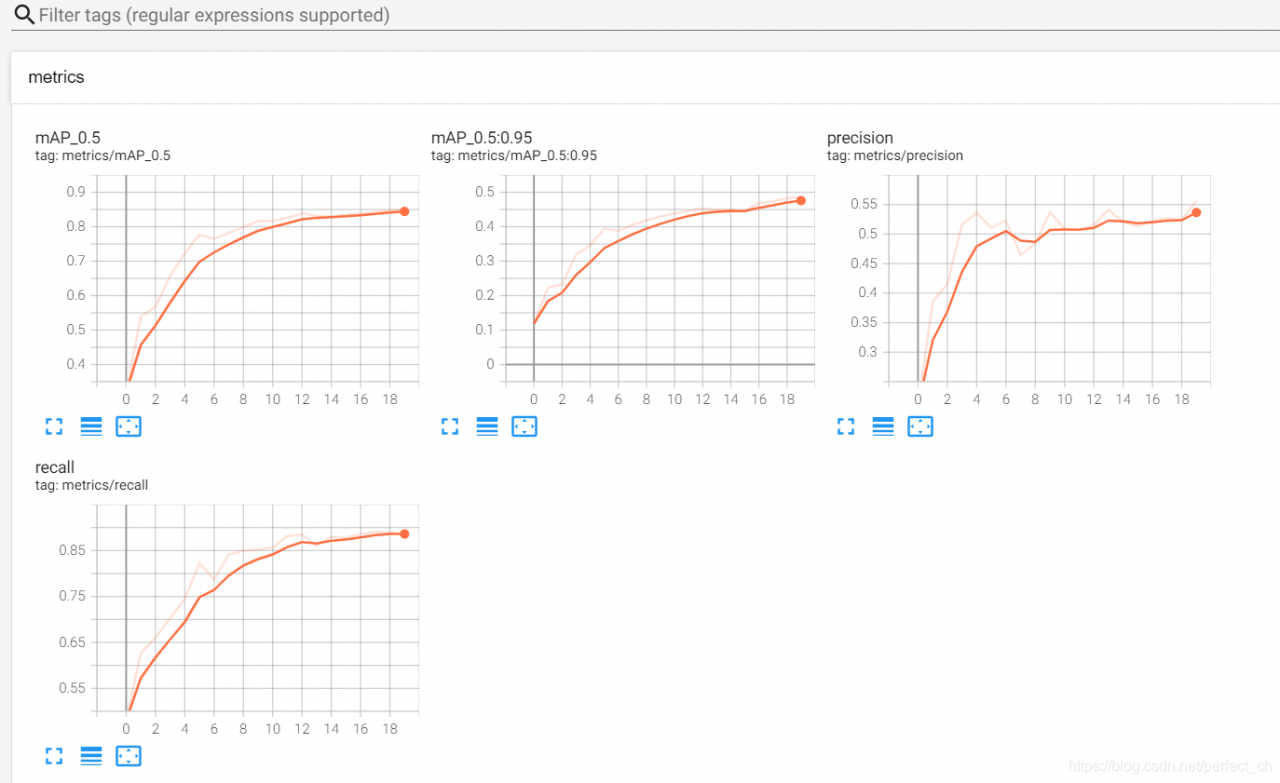
Tensorboard — logdir = event dir (event save path)
After meeting the problem of “no dashboards are active for the current data set”, it is not solved after searching on the Internet for several hours; I tried several times according to my own ideas and finally solved the problem. Now I share the solutions as follows:
1> Find the path of tensorboard, and then CD to the path;
2> Copy and paste the directory of the file to be displayed to the path of the tensorboard;
3> CD to the directory of tensorboard, enter:
tensorboard –logdir=
4> Copy address http://localhost : 6006 /, input to browser, finish.