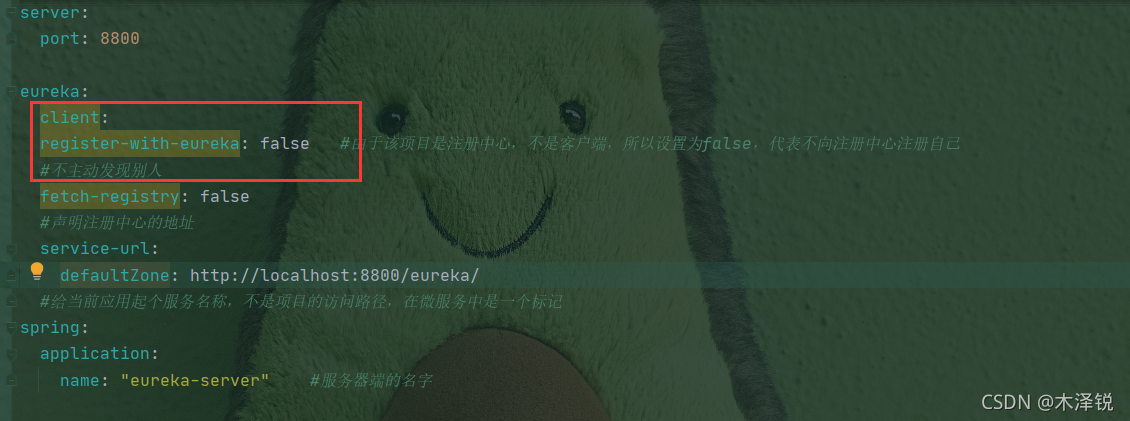
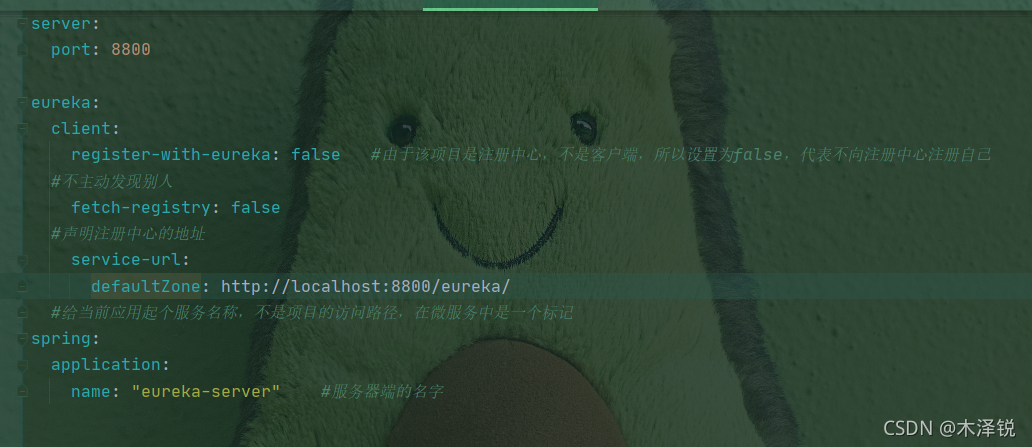
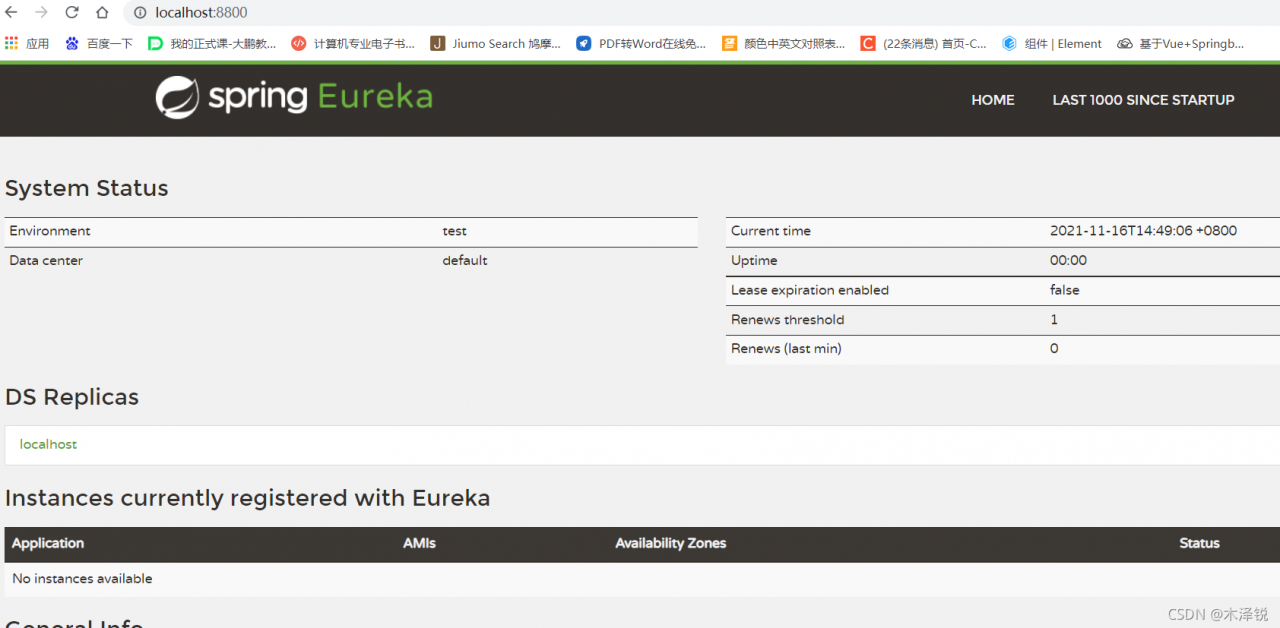
import requests
url=['www....','www.....',...]
for i in range(0,len(url)):
linkhtml = requests.get(url[i])
The crawler reported the following error:
File "C:\Users\lenovo7\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 247, in urlretrieve
with contextlib.closing(urlopen(url, data)) as fp:
File "C:\Users\lenovo7\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "C:\Users\lenovo7\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 531, in open
response = meth(req, response)
File "C:\Users\lenovo7\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 640, in http_response
response = self.parent.error(
File "C:\Users\lenovo7\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 569, in error
return self._call_chain(*args)
File "C:\Users\lenovo7\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 502, in _call_chain
result = func(*args)
File "C:\Users\lenovo7\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 649, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 404: Not Found
Refer to an article on stack overflow
Python: urllib.error.HTTPError: HTTP Error 404: Not Found – Stack Overflow
In the crawler scenario, the original link may not open. Naturally, it will prompt HTTP Error 404. What you need to do is skip this link and then crawl to the following page
Correction code
import requests
url=['www....','www.....',...]
for i in range(0,len(url)):
try:
linkhtml = requests.get(url[i])
except:
pass