Problem description
During the big data storage experiment, an error is reported with the shell command of HBase. Connection closed
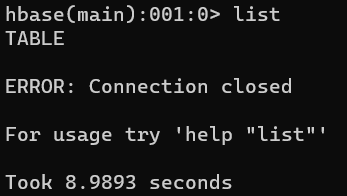
check the log and find that the error reporting service does not exist
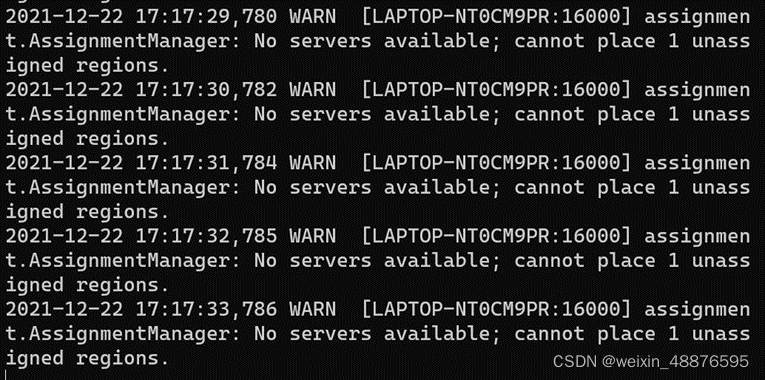
Final solution
After a lot of troubleshooting, I finally found that it was a problem with the JDK version. I used version java-17.0.1 is too high. Finally, it was changed to jdk-8u331-linux-x64.tar.gz is solved
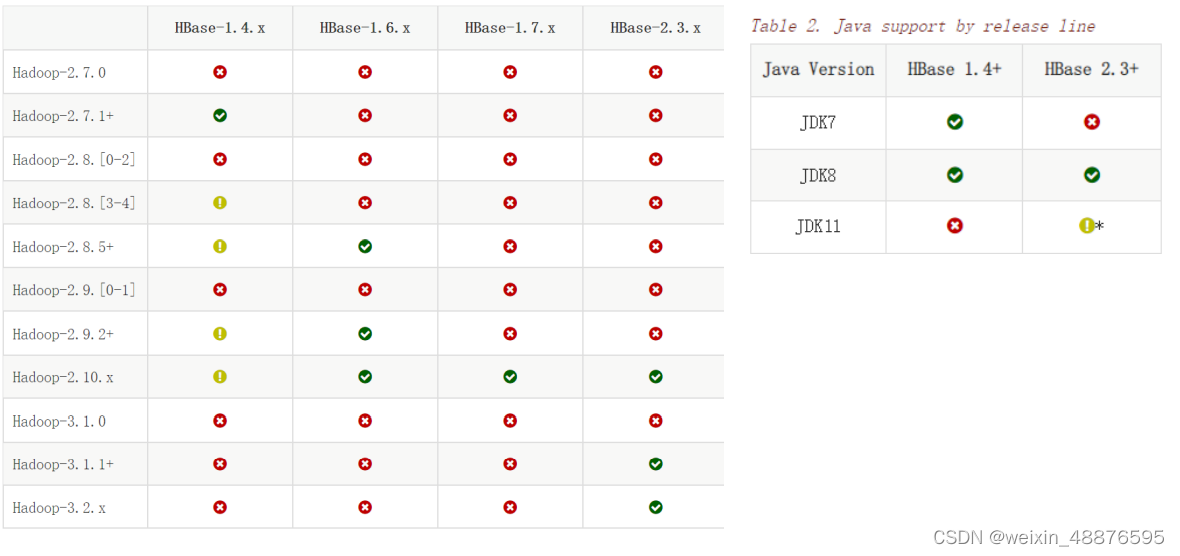
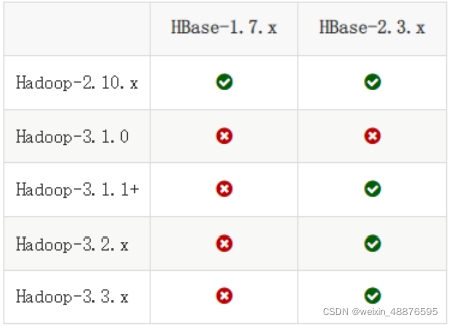
My versions are
hadoop 3.2. 2
hbase 2.3. 6
java 1.8. 0
The matching table of Hadoop, HBase and Java is attached
Solution steps
1 empty the temporary files of Hadoop
Close HBase and Hadoop processes first
stop-all.sh
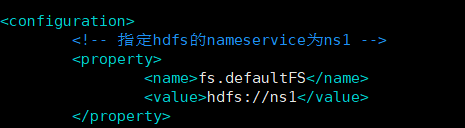
View HDFS site XML
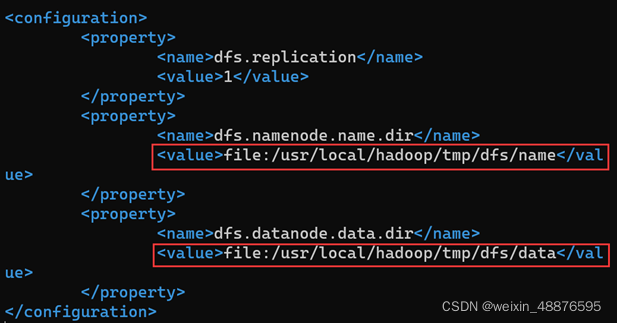
delete all the files in the two folders (the same is true for the name folder)

Re perform Hadoop formatting

2 change java to the specified version (don’t forget to change the Java folder name in the environment variable)
I use 1.8 0_ three hundred and thirty-one
java -version

3 restart the computer and start SSH, Hadoop and HBase
service ssh start
start-dfs.sh
start-hbase.sh
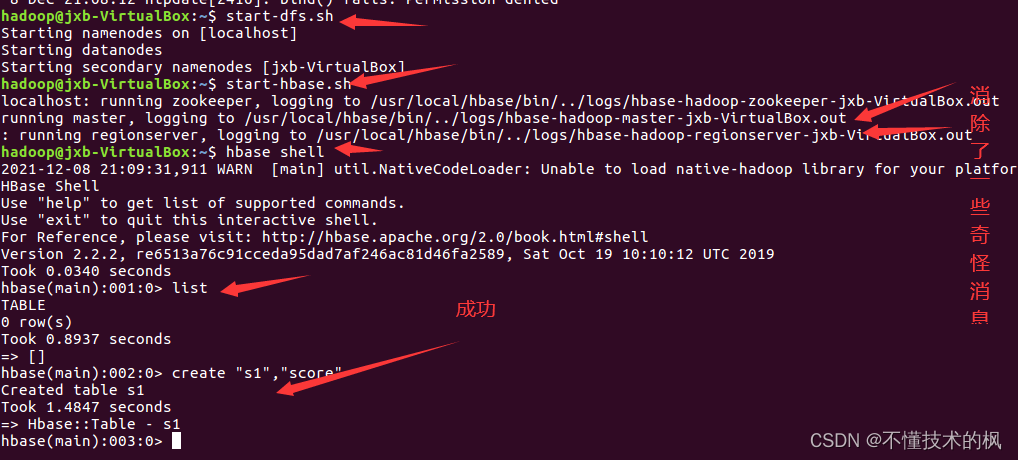
4. Enter HBase shell and find it successful
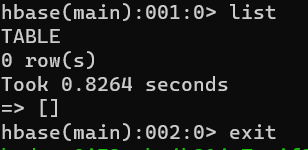

 3. Eliminate strange messages from HBase
3. Eliminate strange messages from HBase