This exception occurs when you restart tomcat, but it does not affect the normal function.
Exception code:
Message: Illegal access: this web application instance has been stopped already. Could not load net.sf.ehcache.store.disk.DiskStore$KeySet. The eventual following stack trace is caused by an error thrown for debugging purposes as well as to attempt to terminate the thread which caused the illegal access, and has no functional impact.
java.lang.IllegalStateException
at org.apache.catalina.loader.WebappClassLoaderBase.loadClass(WebappClassLoaderBase.java:1776)
at org.apache.catalina.loader.WebappClassLoaderBase.loadClass(WebappClassLoaderBase.java:1734)
at net.sf.ehcache.store.disk.DiskStore.keySet(DiskStore.java:521)
at net.sf.ehcache.store.disk.DiskStorageFactory$DiskExpiryTask.run(DiskStorageFactory.java:828)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:304)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Exception analysis: restart Tomcat repeatedly and frequently, resulting in the thread in the last tomat not closing normally
solutions:
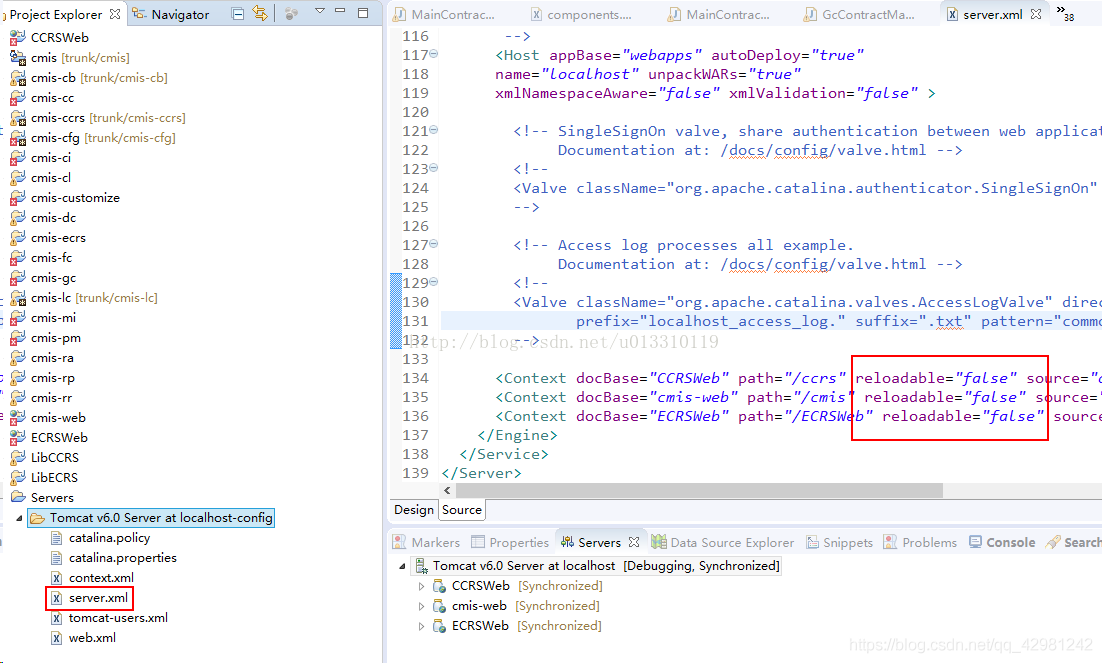
Change the reloadable in server.xml in Tomcat from true to false.
After setting reloadable = “true”, Tomcat will monitor the source code of the project in real time, and restart the Tomcat server in case of any change. When debugging a program, relaodable = true is usually not set. It is unreasonable to restart Tomcat frequently. If you set reloadable = false, or do not set this property, only when you add, delete or rename method or instance fields, do you require the service to restart, which is suitable for you to debug programs.
File settings: server.xml & gt; reloadable=“false”。