Softmax is a function in Python, so before using it, you need to change numpy.ndarray type to tensor type of torch
torch.from_ Numpy (ndarray type variable)
2; Ndarray
tensor type variable. Numpy ()
Tag Archives: pytorch
An error related to field none type occurs when allennlp executes the train
An error has been reported
TypeError: ArrayField.empty_field: return type `None` is not a `<class 'alleSolution:
the error comes from the overlaps package. Replace it with an older version
PIP install overlaps = = 4.1.2
Syntax Error: Non-UTF-8 code start with \xce’in file
Question:
SyntaxError: Non-UTF-8 code starting with '\xce' in file E:/python_work/study/no_black.py on line 6, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for detailssolve:
Write [# – * – Coding: GBK – * -] on the first line of the PY file (including #, #, and one space after #)
# -*- coding: gbk -*- 12304;388382;3906442nd 123057 SyntaxError and unicode error and 8216215;
The error is path ‘/’ “\”
for file in glob.glob('E:\2021\deep learning\unet-pytorch-main\miou_pr_dir\*.png'):
togrey(file,'E:\2021\deep learning\tianchi\no_black_png')Amend to read
for file in glob.glob('E:/2021/deep learning/unet-pytorch-main/miou_pr_dir/*.png'):
togrey(file,'E:/2021\deep learning/tianchi/no_black_png')PyTorch CUDA error: an illegal memory access was encountered
Debugging the Python code encountered this error
there is a similar error CUDA error: cublas_ STATUS_ INTERNAL_ ERROR when calling cublasSgemm(...)
Network search, all kinds of answers, driver version, fixed CUDA device number and so on. Although all of them have been successful, they feel unreliable.
This error message looks like a memory access error
solutions:
Check the code carefully and unify the data on CPU or GPU.
Inspection process is very troublesome, in order to facilitate inspection, I wrote a small function.
def printTensor(t, tag:str):
sz = t.size()
p = t
for i in range(len(sz)-1):
p = p[0]
if len(p)>3:
p = p[:3]
print('\t%s.size'%tag, t.size(), ' dev :', t.device, ": ",p.data)
return
When using, printtensor (context, 'context') , the output is similar
context.size torch.Size([4, 10, 10]) dev : cuda:0 : tensor([0, 0, 0], device=‘ cuda:0 ’)
This function has two main points
- output device output data
The second point is particularly important. Only output devices do not necessarily trigger errors. Only when you output data and pytorch runs down according to the process, can you make a real error.
Finally, the author found that the network of NN. * did not call to (device) explicitly. However, the customized models do inherit NN. Module , which needs to be checked in the future.
[Solved] ValueError: only one element tensors can be converted to Python scalars
This error occurred in Python.
At first, the reason is that I want to change the list with a tensor to a tensor type, that is, [tensor (), tensor ()] to a tensor, and then I write like this,
a = torch.randn(1,2) # tensor([[-0.4962, 0.6034]])
d = [a, a, a] # [tensor([[-0.4962, 0.6034]]), tensor([[-0.4962, 0.6034]]), tensor([[-0.4962, 0.6034]])]
d = torch.tensor(d)It’s a mistake. ValueError: only one element tensors can be converted to Python scalars
I see a solution on the Internet,
val= torch.tensor([item.cpu().detach().numpy() for item in val]).cuda() This method is very unsophisticated and concise.
Another way is to use torch. Cat, which is very concise. If you want to expand dimensions, you can use operations such as unsqueeze on this basis.
d = torch.cat(d, 0)
'''
Output: tensor([[-0.4962, 0.6034],
[-0.4962, 0.6034],
[-0.4962, 0.6034]])
'''Pytorch error: `module ‘torch‘ has no attribute ‘__version___‘`
Today, I configured the python environment on windows. After installing python, I checked whether it was installed successfully. There was no error in inputting import torch. However, I found that print (torch. Version) could not query torch. After careful examination, I found that two underscores were missing, and there was no error in inputting print (torch. Version). It was a false alarm.
To solve the problem of increasing video memory when training network (torch)
Method 1
torch.backends.cudnn.enabled = True
torch.backends.cudnn.benchmark = TruePrinciple:
Cundnn follows the following criteria:
- if the dimension or type of network input data changes little, set torch.backends.cudnn.benchmark = true It can increase the operation efficiency; If the input data of the network changes every iteration, cndnn will find the optimal configuration every time, which will improve the operation efficiency
Method 2
Tensor calculation should be written as follows:
train_loss += loss.item()‘InceptionOutputs‘ object has no attribute ‘log_softmax‘
Problem Statement.
When using inception_v3 with torchvision.models.inception_v3 today, an error was reported during training.
Solution.
Put net = torchvision.models.inception_v3(pretrained=False).to(DEVICE)
Change to
net = torchvision.models.inception_v3(aux_logits=False,pretrained=False).to(DEVICE)
When using inception_v3 with torchvision.models.inception_v3 today, an error was reported during training.
Solution.
Put net = torchvision.models.inception_v3(pretrained=False).to(DEVICE)
Change to
net = torchvision.models.inception_v3(aux_logits=False,pretrained=False).to(DEVICE)
AttributeError: module ‘onnxruntime‘ has no attribute ‘InferenceSession‘
Because the PY file name is named onnxruntime. Py and the python library onnxruntime have the same name. Change onnxruntime. Py to onnxruntime_ Just execute test. Py…
raise ValueError(‘Expected input batch_size ({}) to match target batch_size ({}).‘
raise ValueError(‘Expected input batch_ size ({}) to match target batch_ size ({}).’
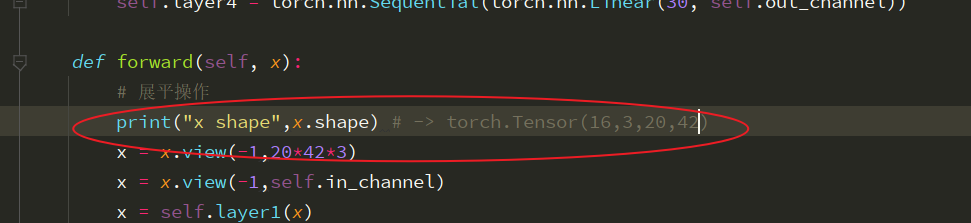
Remember to print the size of the picture before forward propagation. I didn’t notice that all the pictures come in RGB three channel data this time. When using the . View function, I remember to look at it first. When I used it, I calculated the size of the picture directly according to a single channel. Generally, this is the phenomenon that the size of the picture does not match
The phenomenon of mating
pytorch raise RuntimeError(‘Error(s) in loading state_dict for {}:\n\t{}‘.format
When training the model, we need to find out whether there is multi GPU training
If using Python to load the model normally:
model.load_state_dict(torch.load(model_path))
If multi GPU training is used in training
model = torch.nn.DataParallel(model, device_ids=range(opt.ngpu))
If so, loading the model requires
model.load_state_dict({k.replace('module.',''):v for k,v in torch.load(model_path).items()})