Go to Windows > Preferences.Locate Java > Installed JREs. (Or simply type JREs in the search box).The screen will show the list of JREs.Click on Add button, locate the new folder on your machine and select.Remove the old JRE from the list.
Tag Archives: ProgrammerAH
0001: unable to locate the content swf directory: app:/mod/win
resolvent:
X:\Riot Games\League of Legends\RADS\projects\lol_ air_ Client / releases / 0.0.1.195 delete s_ OK file, the client will force the difference matching again, check the integrity of the file
Reproduced in: https://www.cnblogs.com/knightluffy/p/5373579.html
Latex bracket size control
Various brackets are often used when editing formulas under latex. If you directly input brackets (curly brackets need to be escaped), the size is fixed. If the height of the formula is large, it will be very inconsistent.
As shown in the figure below, the brackets on the right are better than those on the left.
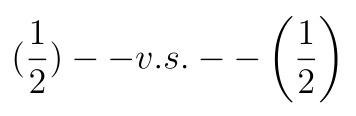
There are two main control methods
1. Use left and right
\Left in front of the left bracket and right in front of the right bracket.
Precautions for use
Need to pair use, can automatically control the size of different levels of brackets
Use examples
The following formula:
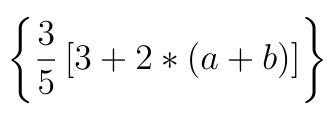
The corresponding latex code is:
\begin{equation}
\left \{ \frac{3}{5} \left [ 3 + 2 * \left ( a + b \right ) \right ] \right \}
\end{equation}
2. Use the big series label
This is a series of tags, including the tag of \\\\\\\\\\\\\\\. In order, the brackets they control keep getting bigger.
Precautions for use
It doesn’t need to be used in pairs. You can control half brackets separately. The size of brackets is controlled by the specific label and can’t be adjusted automatically, so you need to pay attention to matching.
Use examples
Replace the corresponding tag in the previous example with a series of tags, as follows:
\begin{equation}
\bigg \{ \frac{3}{5} \Big [ 3 + 2 * \big ( a + b \big ) \Big ] \bigg \}
\end{equation}
The following formula:
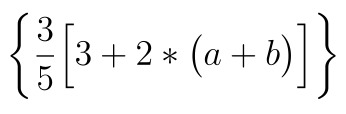
After a little comparison, we can find that the size of brackets is obviously different. This is because the size of brackets displayed by the left and right can be controlled automatically. It does not think it is necessary to use such large brackets, while the size of brackets displayed by the big is relatively fixed.
Therefore, it is recommended to control the size of parentheses by using both left and right
Solution to the problem of vs2017 error report unable to open source file
Problem Description:
Problem Description: a new QT GUI project is created without any modification, but the error list shows that the existing file cannot be opened, and there are various red underscores under the header file of the file code, but it can be run directly main.cpp no problem.
terms of settlement:
For the existing files in the project that cannot be opened, it means that the path of the current project is not included. Here, you can refer to the acquisition method of C + + header file reference (c + + knowledge focus). So we just need to add in the current project path.
Methods: right click the project, click properties, select the included directory in VC + + directory, add $(projectdir) , then apply and confirm.
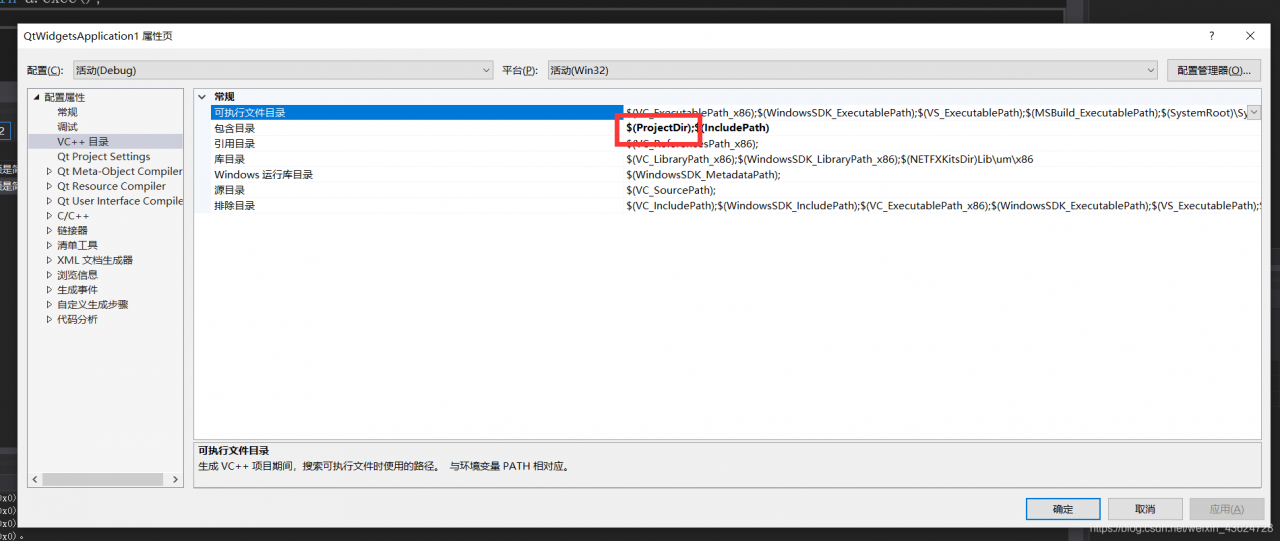
principle
#Include & lt; XX. H & gt; means to search for files directly from the function library of the compiler, and the compiler starts to search for. Xxh from the standard library path
#Include “XX. H” means to search from the user-defined file first. If not, search from the function library. The compiler starts to search XX. H from the user’s working path
If we refer to the header file written by ourselves in the way of & lt; & gt;, we will inevitably be unable to find the source file, because our file is placed in the user directory. The above solution is essentially to append the user directory to the compiler search scope. In fact, we can solve the problem by replacing & lt; & gt; with “” instead.
unable to access ‘https://github.com/facebook/react-devtools/‘:
Encountered fatal: unable to access‘ https://github.com/facebook/react-devtools/ ’: Unknown SSL protocol error in connection to github.com:443 ]( https://img-blog.csdnimg.cn/20210306100824601.png
Solution: change HTTPS to GIT
Microsoft Store install Ubuntu
Search for Ubuntu in the Microsoft Store (I only tested this system. If someone likes to toss, they can also try other systems, such as SUSE and Debian). The process of installing Ubuntu in the application page is very simple, just like installing software.
Search for Ubuntu in Cortana in the lower left corner, and click to enter. The interface you see is just like our terminal interface in Ubuntu. Test the LS command in this window, and it is correct.
Windows 10 Linux subsystem graphical interface
Update
sudo apt-get update
Install xorg
sudo apt-get install xorg
Install xfce4
sudo apt-get install xfce4
Installing xrdp
sudo apt-get install xrdp
Configuring xrdp
sudo sed -i ‘s/port=3389/port=3390/g’ /etc/xrdp/ xrdp.ini
Above is the configuration port
Write xfce4 session to xsession
sudo echo xfce4-session >~/.xsession
Restart xrdp service
sudo service xrdp restart
If there is a firewall, just allow it.
Search for remote desktop connection in Cortana, click enter, input local IP: port, and subsystem user name (in step 2, before the @ symbol in the terminal window)
Graphical interface of Linux subsystem under Windows 10
graphical interface of Linux subsystem under Windows 10
login is successful, and the graphical interface of Ubuntu is displayed.
Graphical interface of Linux subsystem under Windows 10
Xrdp should be started in the terminal before each remote connection, and the window cannot be closed.
Duplicate modifier for the method XXX in type XXX
A very low-level error when writing code. At that time, I didn’t carefully look at the method I wrote. As a result, the constructor wrote more permission modifiers. The record is as follows:
private final ExecutionEnvironment env;
private final String jobId;
private final CalJobParam.JdbcParam dataSink;
public public IndicatorParamFunction(ExecutionEnvironment env, String jobId, CalJobParam.JdbcParam dataSink) {
this.env = env;
this.jobId = jobId;
this.dataSink = dataSink;
}
More public………….. zero
XML tag has empty body less… (Ctrl+F1) Reports empty tag body. The validation works in XML / JSP
The activity of the Android manifest file has been warned several times. The first reaction is that you can’t remember to look it up online. Just wrap it or end it with a ‘/’.
On the Internet:
It appears to have worked by getting rid of the closing tags and replacing them with the self closing tags
<activity
android:name="com.np.npvideoserver.UserConfig"
android:configChanges="orientation|keyboard"></activity>Change to
<activity
android:name="com.np.npvideoserver.UserConfig"
android:configChanges="orientation|keyboard">
</activity>or
<activity
android:name="com.np.npvideoserver.UserConfig"
android:configChanges="orientation|keyboard"/>
Matlab matrix transpose function
For the known matrix A, matlab provides us with two transpose operations.
A. ‘non conjugate transpose
A ‘conjugate transpose
When a is a real matrix, they are the same
Simply conjugate with: conj ()
Simple transpose: transpose ()
example:
a =
12.0000 0 + 2.0000i 5.0000
0 5.0000 4.0000
>> a’
ans =
12.0000 0
0 – 2.0000i 5.0000
5.0000 4.0000
>> a.’
ans =
12.0000 0
0 + 2.0000i 5.0000
5.0000 4.0000
Springboot startup error: java.lang.IllegalArgumentException : Property ‘sqlSessionFactory’ or ‘sqlSessionTempla
Refer to this blog: https://www.cnblogs.com/dbaxyx/p/10663485.html
Error information:
Caused by: java.lang.IllegalArgumentException : Property ‘sqlSessionFactory’ or ‘sqlSessionTemplate’ are required
at org.springframework.util . Assert.notNull ( Assert.java:198 )
at org.mybatis.spring . support.SqlSessionDaoSupport.checkDaoConfig ( SqlSessionDaoSupport.java:74 )
at org.mybatis.spring . mapper.MapperFactoryBean.checkDaoConfig ( MapperFactoryBean.java:90 )
at org.springframework.dao . support.DaoSupport.afterPropertiesSet ( DaoSupport.java:44 )
at org.springframework.beans . factory.support.AbstractAutowireCapableBeanFactory .invokeInitMethods(AbstractAutowi reCapableBeanFactory.java:1837 )
at org.springframework.beans . factory.support.AbstractAutowireCapableBeanFactory .initializeBean(AbstractAutowi reCapableBeanFactory.java:1774 )
… 56 common frames omitted
This is because there is no package introduced:
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>Just import (pay attention to jar package conflicts)
urlopen error unknown url type:httpë/HTTP Error 400:Bad Request
DevTools listening on ws://127.0.0.1:18388/devtools/browser/166d68b9-5bd6-4eaf-9c9c-90b26921a7ae
Traceback (most recent call last):
File "C:\Users\yanghang\Desktop\comic.py", line 39, in <module>
urllib.request.urlretrieve(**thisurl2**,filename=localpath)
File "F:\Python\lib\urllib\request.py", line 248, in urlretrieve
with contextlib.closing(urlopen(url, data)) as fp:
File "F:\Python\lib\urllib\request.py", line 223, in urlopen
return opener.open(url, data, timeout)
File "F:\Python\lib\urllib\request.py", line 526, in open
response = self._open(req, data)
File "F:\Python\lib\urllib\request.py", line 549, in _open
'unknown_open', req)
File "F:\Python\lib\urllib\request.py", line 504, in _call_chain
result = func(*args)
File "F:\Python\lib\urllib\request.py", line 1388, in unknown_open
raise URLError('unknown url type: %s' % type)
urllib.error.URLError: urlopen error unknown url type: "http
To solve this problem, I have tried many methods on the Internet. But I found that there is no error when I change thisurl2 to a certain URL, so the easiest way is to put all the URLs in a list first, and then call it
Python: crawler handles strings of XML and HTML
When crawling a web page, sometimes the data returned by the web page is XML or HTML fragments, which needs to be processed and analyzed by yourself. After searching the processing methods on the Internet, here is a summary.
First, let’s give a simple “Crawler”:
import urllib2
def get_html(url,response_handler):
response=urllib2.urlopen(url)
return response_handler(response.read())
#crawl the page
get_html("www.zhihu.com/topics",html_parser)The above is to get a single page of the “Crawler”, it is indeed very simple, but also describes the core process of crawler: grab the web page and analyze the web page.
The process of crawling web pages is basically solidified, and our focus is on response_ In the handler, this parameter is the method of analyzing web pages. In some popular crawler frameworks, we mainly need to complete the process of analyzing web pages. The example above uses XML_ The parser function, do not think that there is a default implementation (in fact, there is no), let’s complete this function:
#Use lxml library to analyze web pages, the detailed use of this library can be Google
import lxml.etree
def html_parser(response):
page=lxml.etree.HTML(response)
#XPATH is used here to fetch the elements, XPATH usage on your own Google
for elem in page.xpath('//ul[@class="zm-topic-cat-main"]/li'):
print elem.xpath('a/text()')[0]We used it lxml.etree.HTML () load the content of the web page. The returned object can use XPath to retrieve the elements of the web page. It seems that it also supports CSS syntax to retrieve elements. For details, please refer to the relevant documents. The above analysis function completes printing the names of all categories.
For the method of parsing XML strings, it is similar to the above, with the following examples:
import lxml.etree
def xml_parser(response):
page=lxml.etree.fromstring(response)
#do what you want
passThat’s all for now