Article catalog
Datanode failed to start and reported an error incompatible clusterids information error summary problem description problem cause analysis steps solution reference
Datanode startup failed with an error: incompatible clusterids
Information
Environment version: Hadoop 3.3.1 system version: CentOS 7.4 java version: Java se 1.8.0_ three hundred and one
Error report summary
java.io.IOException: Incompatible clusterIDs in /opt/module/hadoop-3.3.1/data/dfs/data: namenode clusterID = CID-aa23cfe4-9ad3-4c06-87fc-e862c8f3a722; datanode clusterID = CID-55fa9a51-7777-4ff4-87d6-4df7cf2cb8b9
Problem description
An error is reported when datanode is started. The contents of the error reported in/opt/module/hadoop-3.3.1/logs/hadoop-bordy-datanode-hadoop 102.log log are as follows:
2021-11-29 21:58:51,350 INFO org.apache.hadoop.hdfs.server.common.Storage: Using 1 threads to upgrade data directories (dfs.datanode.parallel.volumes.load.threads.num=1, dataDirs=1)
2021-11-29 21:58:51,354 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /opt/module/hadoop-3.3.1/data/dfs/data/in_use.lock acquired by nodename 13694@hadoop102
2021-11-29 21:58:51,356 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/opt/module/hadoop-3.3.1/data/dfs/data
java.io.IOException: Incompatible clusterIDs in /opt/module/hadoop-3.3.1/data/dfs/data: namenode clusterID = CID-aa23cfe4-9ad3-4c06-87fc-e862c8f3a722; datanode clusterID = CID-55fa9a51-7777-4ff4-87d6-4df7cf2cb8b9
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:746)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:296)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:409)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:389)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:561)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1753)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1689)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:394)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:295)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:854)
at java.lang.Thread.run(Thread.java:748)
2021-11-29 21:58:51,358 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid a4eeff59-0192-4402-8278-4743158fa405) service to hadoop101/192.168.2.101:8020. Exiting.
java.io.IOException: All specified directories have failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:562)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1753)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1689)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:394)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:295)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:854)
at java.lang.Thread.run(Thread.java:748)
2021-11-29 21:58:51,359 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Ending block pool service for: Block pool <registering> (Datanode Uuid a4eeff59-0192-4402-8278-4743158fa405) service to hadoop101/192.168.2.101:8020
2021-11-29 21:58:51,363 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Removed Block pool <registering> (Datanode Uuid a4eeff59-0192-4402-8278-4743158fa405)
2021-11-29 21:58:53,364 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Exiting Datanode
2021-11-29 21:58:53,424 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DataNode at hadoop102/192.168.2.102
************************************************************/
Cause of problem
The upgrade function of Hadoop requires data node to store a permanent clusterid in its version file. When datanode starts, it will check and match the clusterid in the version file of namenode. If the two do not match, an exception of “incompatible clusterids” will appear. See the official CCR [hdfs-107]
Analysis steps
- View
clusterid in the version file under /opt/module/hadoop-3.3.1/data/DFs/data/current in the datanode directory /opt/module/hadoop-3.3.1/data/DFs/name/current . 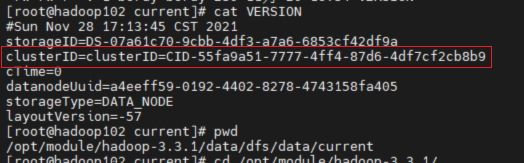 view
view clusterid in the version file under /code> in the namnode directory /opt/module/hadoop-3.3.1/data/name/current . Br> 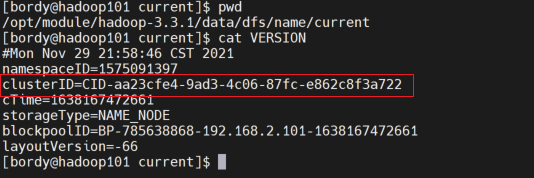 found two files The clusterid in is missing and does not match. It is understood that in the HDFS architecture, each datanode needs to communicate with the namenode, and the clusterid is the unique ID of the namenode.
found two files The clusterid in is missing and does not match. It is understood that in the HDFS architecture, each datanode needs to communicate with the namenode, and the clusterid is the unique ID of the namenode.
terms of settlement
Modify the clusterid value of the failed datanode to the clusterid of the primary namenode
reference resources
Hadoop failed to start datanode. There is a problem with clusterid - Wang Shen - blog Garden (cnblogs. Com)