Exit the command
: quit
: quit
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument
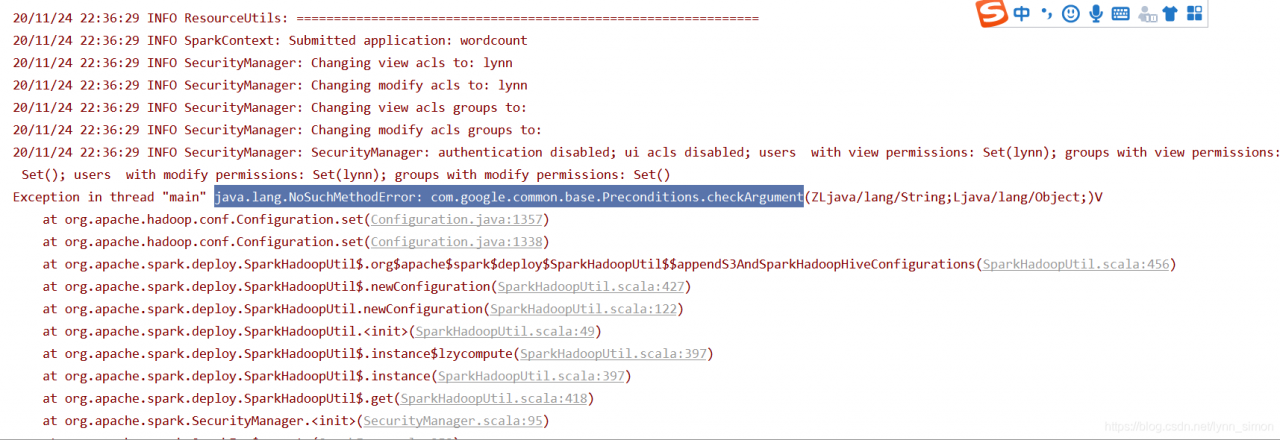 this error is that jar jar dependency conflicts need to remove duplicate dependencies
this error is that jar jar dependency conflicts need to remove duplicate dependencies
step 1: locate the jar where the class is located
IDEA quick search CTRL +c double click shift
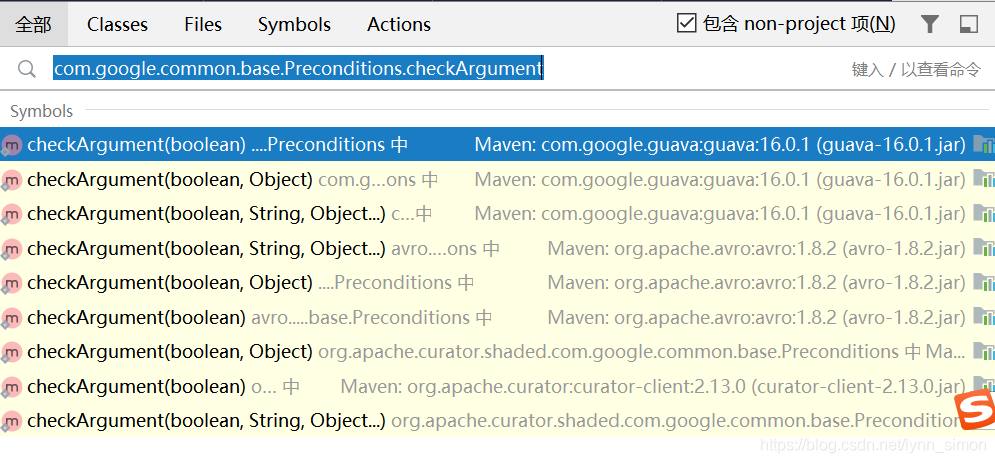 locate the version to be deleted
locate the version to be deleted
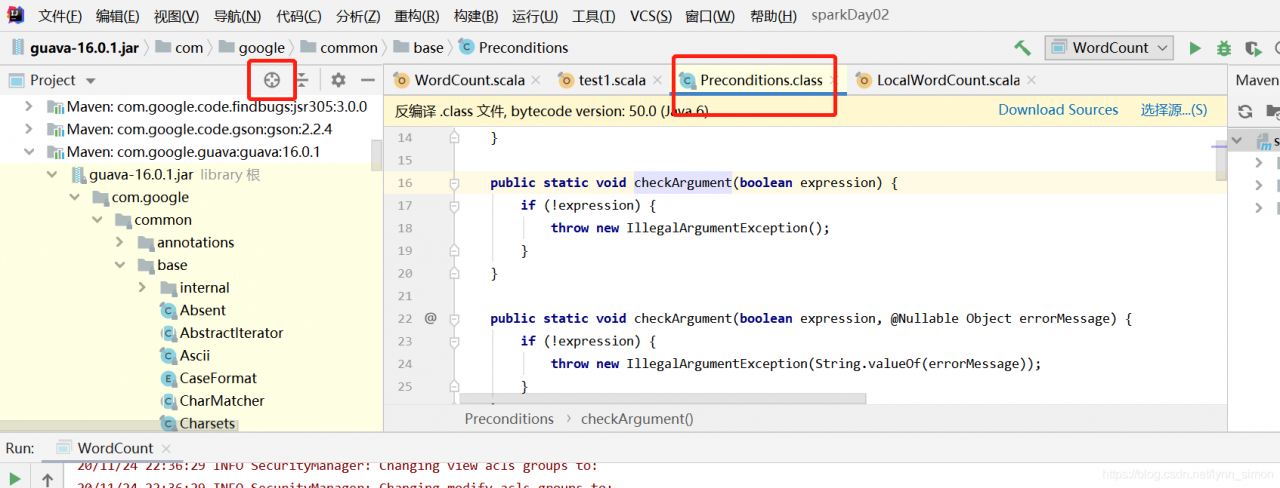 locate the jar location of the specific class
locate the jar location of the specific class
then add the remove operation
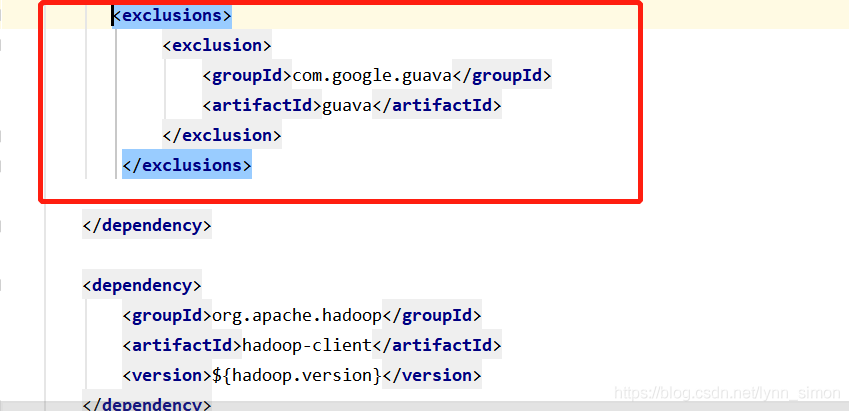 in the pom file
in the pom file
haven’t used spark for a long time. Today, log on the Ubuntu system remotely and execute./spark-shell report error “Failed to initialize compiler: object java.lang. object in compiler mirror not found”.
looked at the Java installation version, there is no problem, so check the ~/.bashrc file, found that the Java path is not, rewrote it is OK.
Spark divides each RDD into several partitions, and the calculation on each partition is an independent task. Each task has its own schedule when it executes, so it needs to complete the sorting, serialization, calculation and deserialization work once.
the overhead of a large part of the work is basically constant and does not vary with the amount of data in partition. So when there are too many partitions in an RDD, there will be a large overhead to compute.
in the process of calculation, we often need to put two or more variables together to do some calculation, we usually use join, cogroup operations. Take a.join(b) for example. In the process of execution, the mapb3 operations would be done to partitions (a and b) for the two RDDS respectively. This is because sharding is not guaranteed by default and b's method is not the same, so it is impossible to complete the join operation with only local data. After re-sharding, you can ensure that the keys of a and B on the same partition are the same. The join operation can then be performed locally.
Due to the existence of mapPartitions, operations such as joins would add partition Numbers. In an iterative computing task, the number of partitions would be added to an unimaginably large number, and the computation time for each round would continue to swell.
below is an example of iteratively calculating the shortest path, where we use the BFS algorithm. Among them, we use graph. Join (SSSP) to combine the graph and the current known shortest distance, and then calculate the distance from each node to other nodes through flatMap and compute calculation approach, and finally calculate the known shortest distance in the new round with reduceByKey(min).
# 随机生成一个有权图
# 格式:(src, [(dst, weight)*n])
n=10000
graph=[(k, [(i, random.random()) for i in random.sample(range(n),random.randint(1,n-1))]) for k in range(n)]
print(graph[0])
# 初始化从source到各个节点的已知最短距离
source=0
sssp=graph.map(lambda r:(r[0],0 if r[0]==source else math.inf)
# 定义计算函数
def compute(links, v):
for d,w in links:
yield (d,v+w)
# 迭代计算
for i in range(20):
t=time.time()
c=graph.join(sssp).flatMap(lambda kls: compute(kls[1][0],kls[1][1]))
sssp=c.reduceByKey(min)
#sssp=sssp.coalesce(4)
p=sssp.aggregate((0,0), (lambda lr,v:(lr[0],lr[1]+1) if math.isinf(v[1]) else(lr[0]+v[1],lr[1])), (lambda a,b:(a[0]+b[0],a[1]+b[1])))
print(i,time.time()-t,p,c.getNumPartitions(),sssp.getNumPartitions())
The getnumb2 function here called can see how many partitions are currently in an RDD.
the following data is the calculation result when I ran graph with 3 core, and cut graph into 3 pieces at the same time, and cut the initial SSSP into 6 pieces. It can be seen that, except for the first round, which was slower due to some initialization work, the calculation time of each round increased with the increase of partition number.
if WebUI is used, the corresponding stage information can be pointed out, and it can be seen clearly that the number of tasks is increasing gradually and overhead is also increasing. The resulting operation reduceByKey also took longer and longer to operate.
0 2.0179808139801025 (8745.09903, 1) 9 9
1 1.5022525787353516 (8745.099020000001, 0) 12 12
2 2.0394625663757324 (8745.09902, 0) 15 15
3 2.5546443462371826 (8745.099020000001, 0) 18 18
4 3.239337921142578 (8745.09902, 0) 21 21
Solution: merge partition
is the repartition function. It can convert an RDD into any number of Partitions.
a=sc.parallelize(range(100),5) # 初始为5个partition
print(a.getNumPartitions())
b=a.repartition(10) # 转为10个partition
print(b.getNumPartitions())
c=a.repartition(2) # 转为2个partition
print(c.getNumPartitions())
, but repartition will recalculate all the elements' partitions that they should be part of each execution, which may be very expensive.
function is different from the repartition function, and the coalesce function is used only to reduce the number of partitions. And it does not recompute partition ownership, it simply merges some data. Therefore, its parameters are only meaningful if they are less than the current number of partitions of the RDD.
its execution principle is not to carry out cross-communication, but simply to combine data blocks on the same core, so that the final partition quantity meets the given parameters.
a=sc.parallelize(range(100),5
b=a.coalesce(5)
Below is the result after I removed the comment in the above code for coalesce. The first run took a little longer because I did some other things with each other. But then the running time is very stable and no longer increases with the number of rounds.
0 2.5019025802612305 (8745.099020000001, 0) 7 4
1 0.9806034564971924 (8745.099020000001, 0) 7 4
2 0.8405632972717285 (8745.099020000001, 0) 7 4
3 0.795809268951416 (8745.099020000001, 0) 7 4
4 0.7986171245574951 (8745.099020000001, 0) 7 4