1. Sparksql configuration
Put $hive_ HOME/conf/hive- site.xml Copy configuration file to $spark_ Home/conf directory.
Add $Hadoop_ HOME/etc/hadoop/hdfs- site.xml Copy configuration file to $spark_ Home/conf directory.
2. Run sparkql
Run./bin/spark SQL under Cd/usr/local/spark to report error creating transactional connection factory
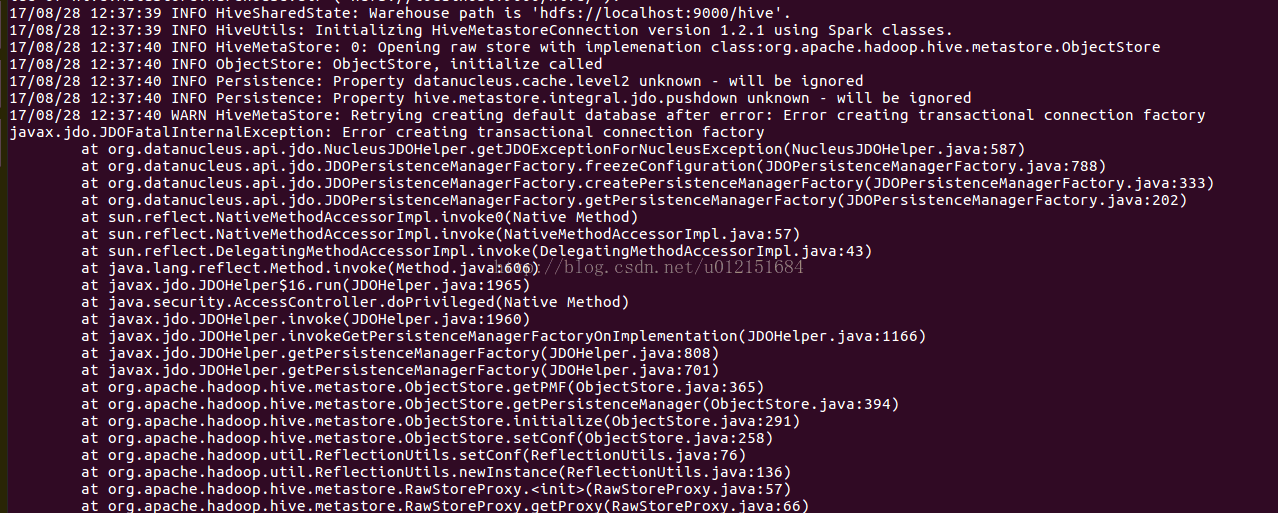
First of all, because the MySQL provided for hive is used as the metadata server, the corresponding jar package support is required. Looking at the detailed error output log, we find that the jar package lacking MySQL connector is indeed missing, so we need to specify the path of the MySQL jar package when starting sparkql as follows:
modify
./bin/spark SQL — driver class path/usr/local/hive/lib/mysql-connector-java-5.1.25. Jar can run normally
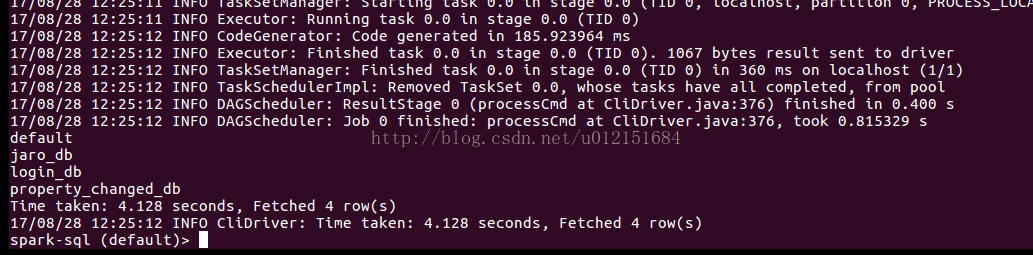
The output is as follows: